你好,我是Chrono。
在上节课里,我给出了一个书店程序的例子,讲了项目设计、类图和自旋锁、Lua配置文件解析等工具类,搭建出了应用的底层基础。
今天,我接着讲剩下的主要业务逻辑部分,也就是数据的表示与统计,还有数据的接收和发送主循环,最终开发出完整的应用程序。
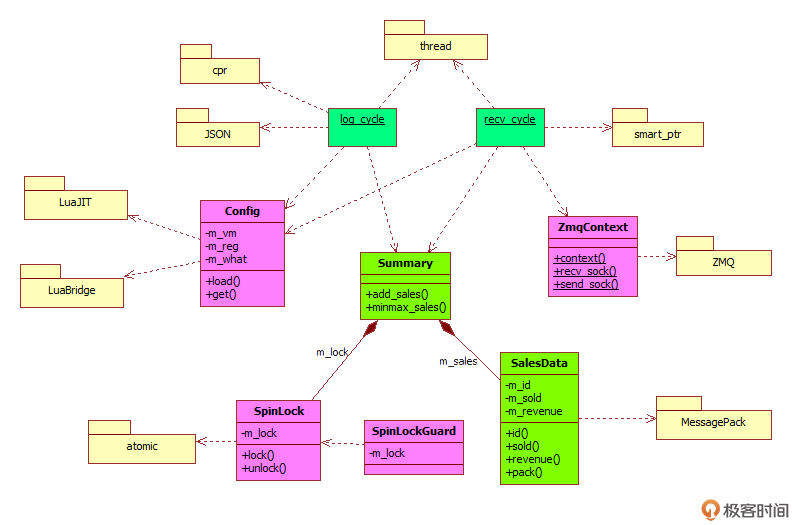
这里我再贴一下项目的UML图,希望给你提个醒。借助图形,我们往往能够更好地把握程序的总体结构。
图中间标注为绿色的两个类SalesData、Summary和两个lambda表达式recv_cycle、log_cycle是今天这节课的主要内容,实现了书店程序的核心业务逻辑,所以需要你重点关注它。
首先,我们来看一下怎么表示书本的销售记录。这里用的是SalesData类,它是书店程序数据统计的基础。
如果是实际的项目,SalesData会很复杂,因为一本书的相关信息有很多。但是,我们的这个例子只是演示,所以就简化了一些,基本的成员只有三个:ID号、销售册数和销售金额。
上节课,在讲自旋锁、配置文件等类时,我只是重点说了说代码内部逻辑,没有完整地细说,到底该怎么应用前面讲过的那些C++编码准则。
那么,这次在定义SalesData类的时候,我就集中归纳一下。这些都是我写C++代码时的“惯用法”,你也可以在自己的代码里应用它们,让代码更可读可维护:
列的点比较多,你可以对照着源码来进行理解:
class SalesData final // final禁止继承
{
public:
using this_type = SalesData; // 自己的类型别名
public:
using string_type = std::string; // 外部的类型别名
using string_view_type = const std::string&;
using uint_type = unsigned int;
using currency_type = double;
STATIC_ASSERT(sizeof(uint_type) >= 4); // 静态断言
STATIC_ASSERT(sizeof(currency_type) >= 4);
public:
SalesData(string_view_type id, uint_type s, currency_type r) noexcept // 构造函数,保证不抛出异常
: m_id(id), m_sold(s), m_revenue(r)
{}
SalesData(string_view_type id) noexcept // 委托构造
: SalesData(id, 0, 0)
{}
public:
SalesData() = default; // 显式default
~SalesData() = default;
SalesData(const this_type&) = default;
SalesData& operator=(const this_type&) = default;
SalesData(this_type&& s) = default; // 显式转移构造
SalesData& operator=(this_type&& s) = default;
private:
string_type m_id = ""; // 成员变量初始化
uint_type m_sold = 0;
uint_type m_revenue = 0;
public:
void inc_sold(uint_type s) noexcept // 不抛出异常
{
m_sold += s;
}
public:
string_view_type id() const noexcept // 常函数,不抛出异常
{
return m_id;
}
uint_type sold() const noexcept // 常函数,不抛出异常
{
return m_sold;
}
};
需要注意的是,代码里显式声明了转移构造和转移赋值函数,这样,在放入容器的时候就避免了拷贝,能提高运行效率。
SalesData作为销售记录,需要在网络上传输,所以就需要序列化和反序列化。
这里我选择的是MessagePack(第15讲),我看重的是它小巧轻便的特性,而且用起来也很容易,只要在类定义里添加一个宏,就可以实现序列化:
public:
MSGPACK_DEFINE(m_id, m_sold, m_revenue); // 实现MessagePack序列化功能
为了方便使用,还可以为SalesData增加一个专门序列化的成员函数pack():
public:
msgpack::sbuffer pack() const // 成员函数序列化
{
msgpack::sbuffer sbuf;
msgpack::pack(sbuf, *this);
return sbuf;
}
不过你要注意,写这个函数的同时也给SalesData类增加了点复杂度,在一定程度上违反了单一职责原则和接口隔离原则。
如果你在今后的实际项目中遇到类似的问题,就要权衡后再做决策,确认引入新功能带来的好处大于它增加的复杂度,尽量抵制扩充接口的诱惑,否则很容易写出“巨无霸”类。
有了销售记录之后,我们就可以定义用于数据存储和统计的Summary类了。
Summary类依然要遵循刚才的那些基本准则。从UML类图里可以看到,它关联了好几个类,所以类型别名对于它来说就特别重要,不仅可以简化代码,也方便后续的维护,你可要仔细看一下源码:
class Summary final // final禁止继承
{
public:
using this_type = Summary; // 自己的类型别名
public:
using sales_type = SalesData; // 外部的类型别名
using lock_type = SpinLock;
using lock_guard_type = SpinLockGuard;
using string_type = std::string;
using map_type = // 容器类型定义
std::map<string_type, sales_type>;
using minmax_sales_type =
std::pair<string_type, string_type>;
public:
Summary() = default; // 显式default
~Summary() = default;
Summary(const this_type&) = delete; // 显式delete
Summary& operator=(const this_type&) = delete;
private:
mutable lock_type m_lock; // 自旋锁
map_type m_sales; // 存储销售记录
};
Summary类的职责是存储大量的销售记录,所以需要选择恰当的容器。
考虑到销售记录不仅要存储,还有对数据的排序要求,所以我选择了可以在插入时自动排序的有序容器map。
不过要注意,这里我没有定制比较函数,所以默认是按照书号来排序的,不符合按销售量排序的要求。
(如果要按销售量排序的话就比较麻烦,因为不能用随时变化的销量作为Key,而标准库里又没有多索引容器,所以,你可以试着把它改成unordered_map,然后再用vector暂存来排序)。
为了能够在多线程里正确访问,Summary使用自旋锁来保护核心数据,在对容器进行任何操作前都要获取锁。锁不影响类的状态,所以要用mutable修饰。
因为有了RAII的SpinLockGuard(第21讲),所以自旋锁用起来很优雅,直接构造一个变量就行,不用担心异常安全的问题。你可以看一下成员函数add_sales()的代码,里面还用到了容器的查找算法。
public:
void add_sales(const sales_type& s) // 非const
{
lock_guard_type guard(m_lock); // 自动锁定,自动解锁
const auto& id = s.id(); // const auto自动类型推导
if (m_sales.find(id) == m_sales.end()) {// 查找算法
m_sales[id] = s; // 没找到就添加元素
return;
}
m_sales[id].inc_sold(s.sold()); // 找到就修改销售量
m_sales[id].inc_revenue(s.revenue());
}
Summary类里还有一个特别的统计功能,计算所有图书销量的第一名和最后一名。这用到了minmax_element算法(第13讲)。又因为比较规则是销量,而不是ID号,所以还要用lambda表达式自定义比较函数:
public:
minmax_sales_type minmax_sales() const //常函数
{
lock_guard_type guard(m_lock); // 自动锁定,自动解锁
if (m_sales.empty()) { // 容器空则不处理
return minmax_sales_type();
}
auto ret = std::minmax_element( // 求最大最小值
std::begin(m_sales), std::end(m_sales),// 全局函数获取迭代器
[](const auto& a, const auto& b) // 匿名lambda表达式
{
return a.second.sold() < b.second.sold();
});
auto min_pos = ret.first; // 返回的是两个迭代器位置
auto max_pos = ret.second;
return {min_pos->second.id(), max_pos->second.id()};
}
好了,所有的功能类都开发完了,现在就可以把它们都组合起来了。
因为客户端程序比较简单,只是序列化,再用ZMQ发送,所以我就不讲了,你可以课下去看GitHub上的源码,今天我主要讲服务器端。
在main()函数开头,首先要加载配置文件,然后是数据存储类Summary,再定义一个用来计数的原子变量count(第14讲),这些就是程序运行的全部环境数据:
Config conf; // 封装读取Lua配置文件
conf.load("./conf.lua"); // 解析配置文件
Summary sum; // 数据存储和统计
std::atomic_int count {0}; // 计数用的原子变量
接下来的服务器主循环,我使用了lambda表达式,引用捕获上面的那些变量:
auto recv_cycle = [&]() // 主循环lambda表达式
{
...
};
主要的业务逻辑其实很简单,就是ZMQ接收数据,然后MessagePack反序列化,存储数据。
不过为了避免阻塞、充分利用多线程,我在收到数据后,就把它包装进智能指针,再扔到另外一个线程里去处理了。这样主循环就只接收数据,不会因为反序列化、插入、排序等大计算量的工作而阻塞。
我在代码里加上了详细的注释,你一定要仔细看、认真理解:
auto recv_cycle = [&]() // 主循环lambda表达式
{
using zmq_ctx = ZmqContext<1>; // ZMQ的类型别名
auto sock = zmq_ctx::recv_sock(); // 自动类型推导获得接收Socket
sock.bind( // 绑定ZMQ接收端口
conf.get<string>("config.zmq_ipc_addr")); // 读取Lua配置文件
for(;;) { // 服务器无限循环
auto msg_ptr = // 自动类型推导获得智能指针
std::make_shared<zmq_message_type>();
sock.recv(msg_ptr.get()); // ZMQ阻塞接收数据
++count; // 增加原子计数
std::thread( // 再启动一个线程反序列化存储,没有用async
[&sum, msg_ptr]() // 显式捕获,注意!!
{
SalesData book;
auto obj = msgpack::unpack( // 反序列化
msg_ptr->data<char>(), msg_ptr->size()).get();
obj.convert(book);
sum.add_sales(book); // 存储数据
}).detach(); // 分离线程,异步运行
} // for(;;)结束
}; // recv_cycle lambda
你要特别注意lambda表达式与智能指针的配合方式,要用值捕获而不能是引用捕获,否则,在线程运行的时候,智能指针可能会因为离开作用域而被销毁,引用失效,导致无法预知的错误。
有了这个lambda,现在就可以用async(第14讲)来启动服务循环:
auto fu1 = std::async(std::launch::async, recv_cycle);
fu1.wait();
现在我们就能够接收客户端发过来的数据,开始统计了。
recv_cycle是接收前端发来的数据,我们还需要一个线程把统计数据外发出去。同样,我实现一个lambda表达式:log_cycle。
它采用了HTTP协议,把数据打包成JSON,发送到后台的某个RESTful服务器。
搭建符合要求的Web服务不是件小事,所以这里为了方便测试,我联动了一下《透视HTTP协议》,用那里的OpenResty写了个的HTTP接口:接收POST数据,然后打印到日志里,你可以参考第41讲在Linux上搭建这个后台服务。
log_cycle其实就是一个简单的HTTP客户端,所以代码的处理逻辑比较好理解,要注意的知识点主要有三个,都是前面讲过的:
你如果有点忘了,可以回顾一下,再结合下面的代码来理解、学习:
auto log_cycle = [&]() // 外发循环lambda表达式
{
// 获取Lua配置文件里的配置项
auto http_addr = conf.get<string>("config.http_addr");
auto time_interval = conf.get<int>("config.time_interval");
for(;;) { // 无限循环
std::this_thread::sleep_for(time_interval * 1s); // 线程睡眠等待
json_t j; // JSON序列化数据
j["count"] = static_cast<int>(count);
j["minmax"] = sum.minmax_sales();
auto res = cpr::Post( // 发送HTTP POST请求
cpr::Url{http_addr},
cpr::Body{j.dump()},
cpr::Timeout{200ms} // 设置超时时间
);
if (res.status_code != 200) { // 检查返回的状态码
cerr << "http post failed" << endl;
}
} // for(;;)
}; // log_cycle lambda
然后,还是要在主线程里用async()函数来启动这个lambda表达式,让它在后台定时上报数据。
auto fu2 = std::async(std::launch::async, log_cycle);
这样,整个书店程序就全部完成了,试着去编译运行一下看看吧。
好了,今天我就把书店示例程序从头到尾给讲完了。可以看到,代码里面应用了很多我们之前讲的C++特性,这些特性互相重叠、嵌套,紧凑地集成在了这个不是很大的程序里,代码整齐,逻辑清楚,很容易就实现了多线程、高性能的服务端程序,开发效率和运行效率都非常高。
我再对今天代码里的要点做个简单的小结:
那么,这些代码是否对你的工作有一些启迪呢?你是否能够把这些知识点成功地应用到实际项目里呢?希望你能多学习我在课程里给你分享的开发技巧和经验建议,熟练地掌握它们,写出媲美甚至超越示例代码的C++程序。
最后是课下作业时间,这次就不是思考题,全是动手题,是时候检验你的编码实战能力了:
再补充一点,在动手实践的过程中,你还可以顺便练习一下Git的版本管理:不要直接在master分支上开发,而是开几个不同的feature分支,测试完确认没有问题后,再合并到主干上。
欢迎你在留言区写下你的思考和答案,如果觉得今天的内容对你有所帮助,也欢迎分享给你的朋友。我们下节课见。

评论