上一节,系统终于进入了用户态,公司由一个“皮包公司”进入正轨,可以开始接项目了。
这一节,我们来解析Linux接项目的办事大厅是如何实现的,这是因为后面介绍的每一个模块,都涉及系统调用。站在系统调用的角度,层层深入下去,就能从某个系统调用的场景出发,了解内核中各个模块的实现机制。
有的时候,我们的客户觉得,直接去办事大厅还是不够方便。没问题,Linux还提供了glibc这个中介。它更熟悉系统调用的细节,并且可以封装成更加友好的接口。你可以直接用。
我们以最常用的系统调用open,打开一个文件为线索,看看系统调用是怎么实现的。这一节我们仅仅会解析到从glibc如何调用到内核的open,至于open怎么实现,怎么打开一个文件,留到文件系统那一节讲。
现在我们就开始在用户态进程里面调用open函数。
为了方便,大部分用户会选择使用中介,也就是说,调用的是glibc里面的open函数。这个函数是如何定义的呢?
int open(const char *pathname, int flags, mode_t mode)
在glibc的源代码中,有个文件syscalls.list,里面列着所有glibc的函数对应的系统调用,就像下面这个样子:
# File name Caller Syscall name Args Strong name Weak names
open - open Ci:siv __libc_open __open open
另外,glibc还有一个脚本make-syscall.sh,可以根据上面的配置文件,对于每一个封装好的系统调用,生成一个文件。这个文件里面定义了一些宏,例如#define SYSCALL_NAME open。
glibc还有一个文件syscall-template.S,使用上面这个宏,定义了这个系统调用的调用方式。
T_PSEUDO (SYSCALL_SYMBOL, SYSCALL_NAME, SYSCALL_NARGS)
ret
T_PSEUDO_END (SYSCALL_SYMBOL)
#define T_PSEUDO(SYMBOL, NAME, N) PSEUDO (SYMBOL, NAME, N)
这里的PSEUDO也是一个宏,它的定义如下:
#define PSEUDO(name, syscall_name, args) \
.text; \
ENTRY (name) \
DO_CALL (syscall_name, args); \
cmpl $-4095, %eax; \
jae SYSCALL_ERROR_LABEL
里面对于任何一个系统调用,会调用DO_CALL。这也是一个宏,这个宏32位和64位的定义是不一样的。
我们先来看32位的情况(i386目录下的sysdep.h文件)。
/* Linux takes system call arguments in registers:
syscall number %eax call-clobbered
arg 1 %ebx call-saved
arg 2 %ecx call-clobbered
arg 3 %edx call-clobbered
arg 4 %esi call-saved
arg 5 %edi call-saved
arg 6 %ebp call-saved
......
*/
#define DO_CALL(syscall_name, args) \
PUSHARGS_##args \
DOARGS_##args \
movl $SYS_ify (syscall_name), %eax; \
ENTER_KERNEL \
POPARGS_##args
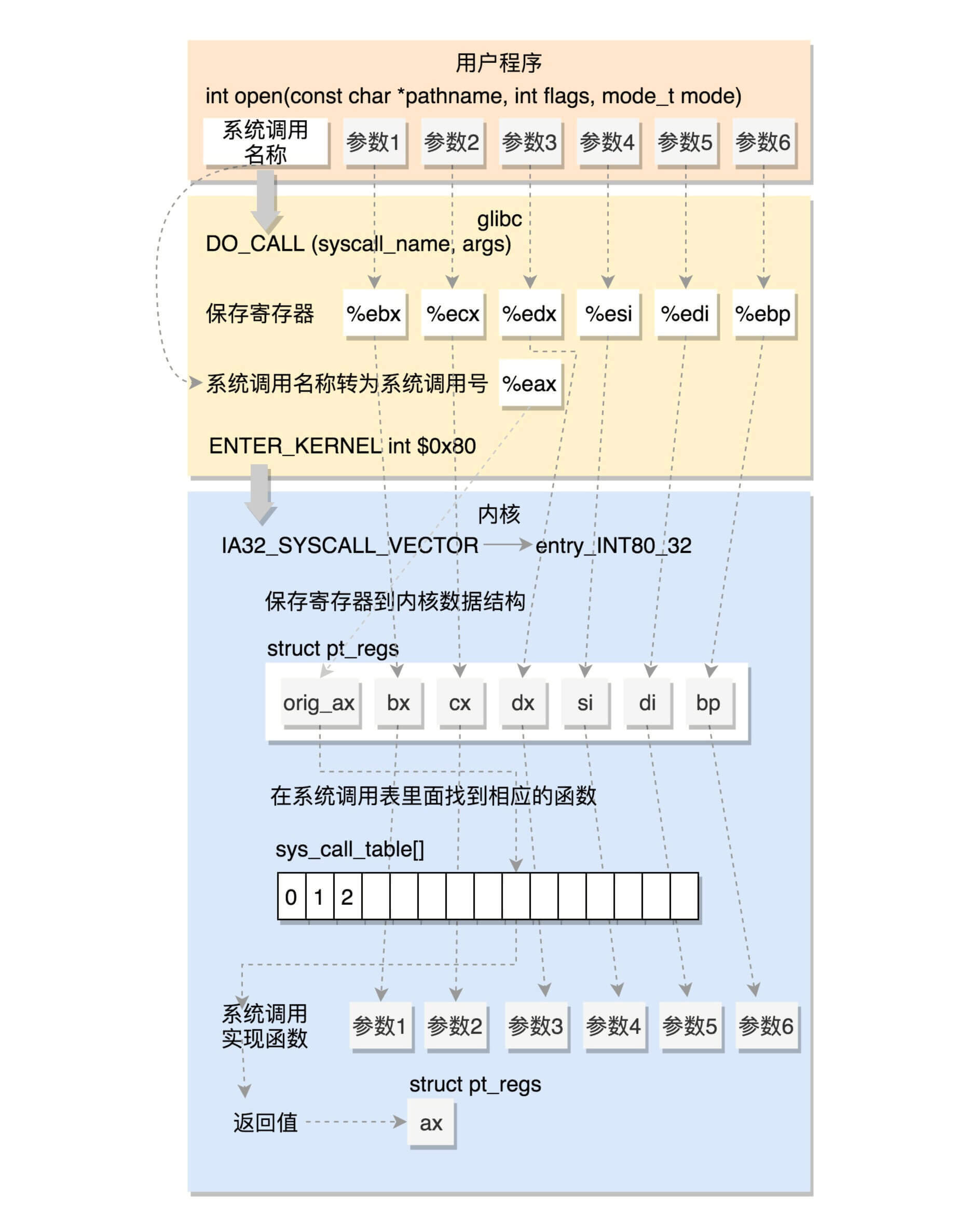
这里,我们将请求参数放在寄存器里面,根据系统调用的名称,得到系统调用号,放在寄存器eax里面,然后执行ENTER_KERNEL。
在Linux的源代码注释里面,我们可以清晰地看到,这些寄存器是如何传递系统调用号和参数的。
这里面的ENTER_KERNEL是什么呢?
# define ENTER_KERNEL int $0x80
int就是interrupt,也就是“中断”的意思。int $0x80就是触发一个软中断,通过它就可以陷入(trap)内核。
在内核启动的时候,还记得有一个trap_init(),其中有这样的代码:
set_system_intr_gate(IA32_SYSCALL_VECTOR, entry_INT80_32);
这是一个软中断的陷入门。当接收到一个系统调用的时候,entry_INT80_32就被调用了。
ENTRY(entry_INT80_32)
ASM_CLAC
pushl %eax /* pt_regs->orig_ax */
SAVE_ALL pt_regs_ax=$-ENOSYS /* save rest */
movl %esp, %eax
call do_syscall_32_irqs_on
.Lsyscall_32_done:
......
.Lirq_return:
INTERRUPT_RETURN
通过push和SAVE_ALL将当前用户态的寄存器,保存在pt_regs结构里面。
进入内核之前,保存所有的寄存器,然后调用do_syscall_32_irqs_on。它的实现如下:
static __always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned int nr = (unsigned int)regs->orig_ax;
......
if (likely(nr < IA32_NR_syscalls)) {
regs->ax = ia32_sys_call_table[nr](
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
syscall_return_slowpath(regs);
}
在这里,我们看到,将系统调用号从eax里面取出来,然后根据系统调用号,在系统调用表中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。如果仔细比对,就能发现,这些参数所对应的寄存器,和Linux的注释是一样的。
根据宏定义,#define ia32_sys_call_table sys_call_table,系统调用就是放在这个表里面。至于这个表是如何形成的,我们后面讲。
当系统调用结束之后,在entry_INT80_32之后,紧接着调用的是INTERRUPT_RETURN,我们能够找到它的定义,也就是iret。
#define INTERRUPT_RETURN iret
iret指令将原来用户态保存的现场恢复回来,包含代码段、指令指针寄存器等。这时候用户态进程恢复执行。
这里我总结一下32位的系统调用是如何执行的。
我们再来看64位的情况(x86_64下的sysdep.h文件)。
/* The Linux/x86-64 kernel expects the system call parameters in
registers according to the following table:
syscall number rax
arg 1 rdi
arg 2 rsi
arg 3 rdx
arg 4 r10
arg 5 r8
arg 6 r9
......
*/
#define DO_CALL(syscall_name, args) \
lea SYS_ify (syscall_name), %rax; \
syscall
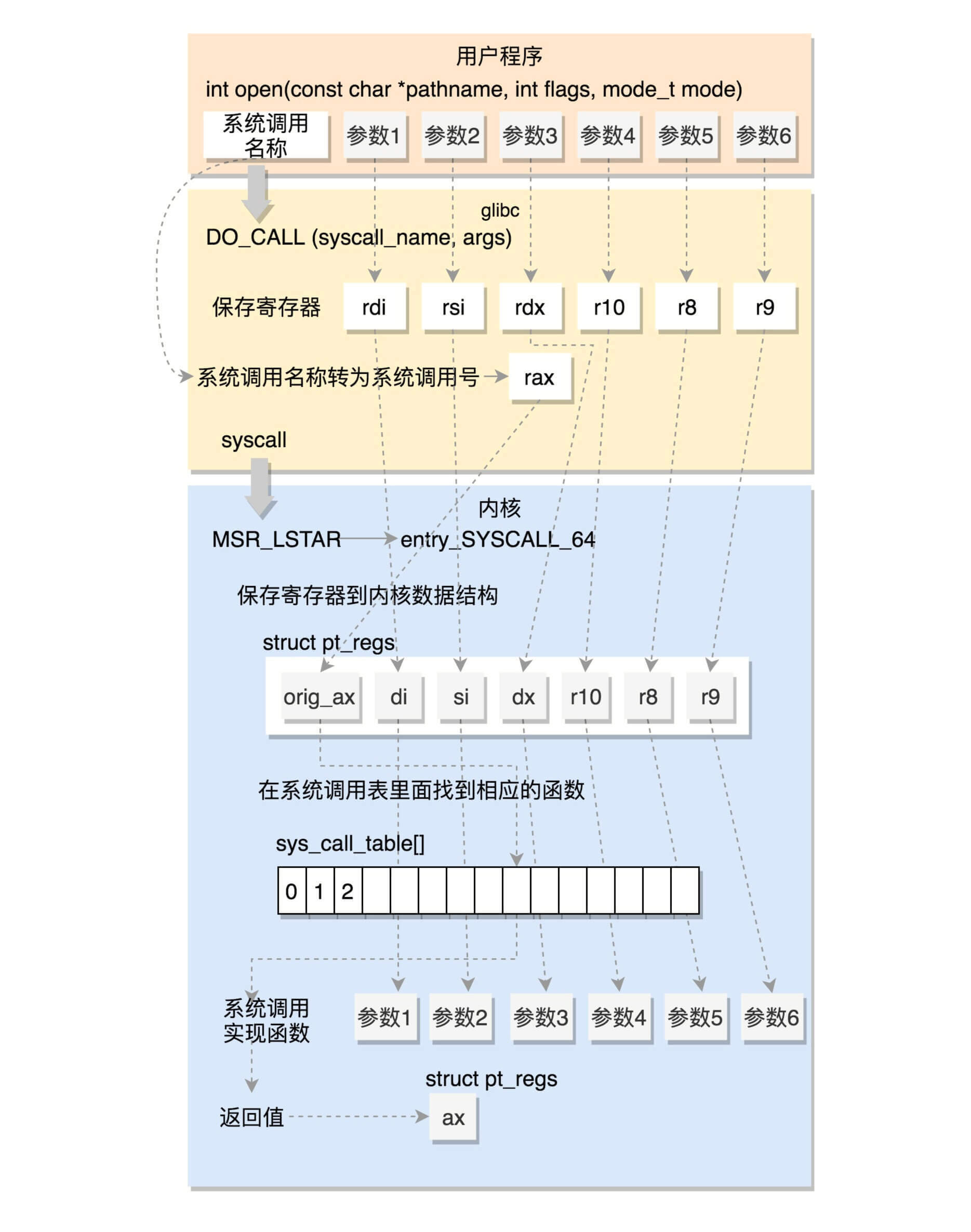
和之前一样,还是将系统调用名称转换为系统调用号,放到寄存器rax。这里是真正进行调用,不是用中断了,而是改用syscall指令了。并且,通过注释我们也可以知道,传递参数的寄存器也变了。
syscall指令还使用了一种特殊的寄存器,我们叫特殊模块寄存器(Model Specific Registers,简称MSR)。这种寄存器是CPU为了完成某些特殊控制功能为目的的寄存器,其中就有系统调用。
在系统初始化的时候,trap_init除了初始化上面的中断模式,这里面还会调用cpu_init->syscall_init。这里面有这样的代码:
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
rdmsr和wrmsr是用来读写特殊模块寄存器的。MSR_LSTAR就是这样一个特殊的寄存器,当syscall指令调用的时候,会从这个寄存器里面拿出函数地址来调用,也就是调用entry_SYSCALL_64。
在arch/x86/entry/entry_64.S中定义了entry_SYSCALL_64。
ENTRY(entry_SYSCALL_64)
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(rsp_scratch) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
pushq %rax /* pt_regs->orig_ax */
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
pushq %rdx /* pt_regs->dx */
pushq %rcx /* pt_regs->cx */
pushq $-ENOSYS /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
sub $(6*8), %rsp /* pt_regs->bp, bx, r12-15 not saved */
movq PER_CPU_VAR(current_task), %r11
testl $_TIF_WORK_SYSCALL_ENTRY|_TIF_ALLWORK_MASK, TASK_TI_flags(%r11)
jnz entry_SYSCALL64_slow_path
......
entry_SYSCALL64_slow_path:
/* IRQs are off. */
SAVE_EXTRA_REGS
movq %rsp, %rdi
call do_syscall_64 /* returns with IRQs disabled */
return_from_SYSCALL_64:
RESTORE_EXTRA_REGS
TRACE_IRQS_IRETQ
movq RCX(%rsp), %rcx
movq RIP(%rsp), %r11
movq R11(%rsp), %r11
......
syscall_return_via_sysret:
/* rcx and r11 are already restored (see code above) */
RESTORE_C_REGS_EXCEPT_RCX_R11
movq RSP(%rsp), %rsp
USERGS_SYSRET64
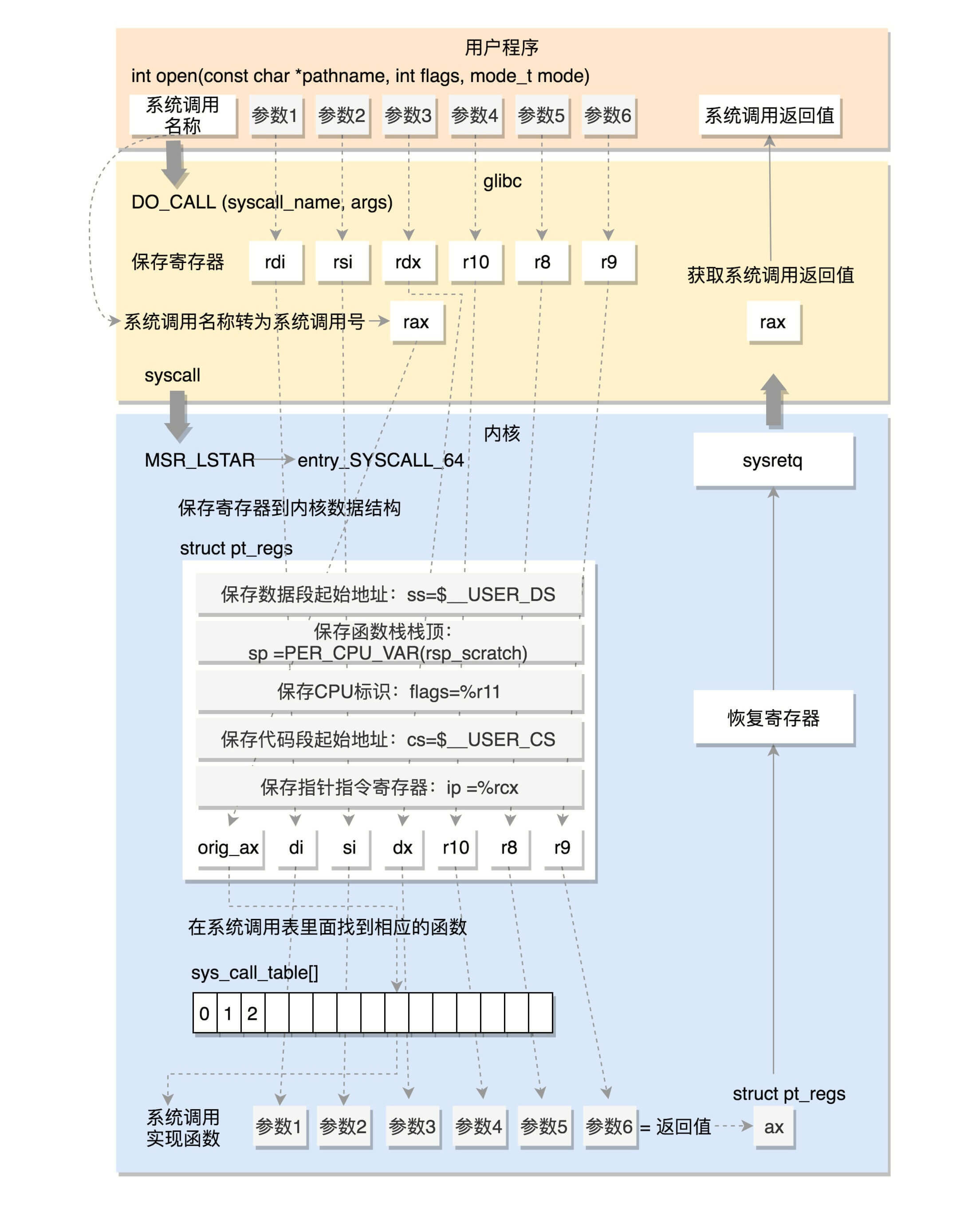
这里先保存了很多寄存器到pt_regs结构里面,例如用户态的代码段、数据段、保存参数的寄存器,然后调用entry_SYSCALL64_slow_pat->do_syscall_64。
__visible void do_syscall_64(struct pt_regs *regs)
{
struct thread_info *ti = current_thread_info();
unsigned long nr = regs->orig_ax;
......
if (likely((nr & __SYSCALL_MASK) < NR_syscalls)) {
regs->ax = sys_call_table[nr & __SYSCALL_MASK](
regs->di, regs->si, regs->dx,
regs->r10, regs->r8, regs->r9);
}
syscall_return_slowpath(regs);
}
在do_syscall_64里面,从rax里面拿出系统调用号,然后根据系统调用号,在系统调用表sys_call_table中找到相应的函数进行调用,并将寄存器中保存的参数取出来,作为函数参数。如果仔细比对,你就能发现,这些参数所对应的寄存器,和Linux的注释又是一样的。
所以,无论是32位,还是64位,都会到系统调用表sys_call_table这里来。
在研究系统调用表之前,我们看64位的系统调用返回的时候,执行的是USERGS_SYSRET64。定义如下:
#define USERGS_SYSRET64 \
swapgs; \
sysretq;
这里,返回用户态的指令变成了sysretq。
我们这里总结一下64位的系统调用是如何执行的。
前面我们重点关注了系统调用的方式,都是最终到了系统调用表,但是到底调用内核的什么函数,还没有解读。
现在我们再来看,系统调用表sys_call_table是怎么形成的呢?
32位的系统调用表定义在arch/x86/entry/syscalls/syscall_32.tbl文件里。例如open是这样定义的:
5 i386 open sys_open compat_sys_open
64位的系统调用定义在另一个文件arch/x86/entry/syscalls/syscall_64.tbl里。例如open是这样定义的:
2 common open sys_open
第一列的数字是系统调用号。可以看出,32位和64位的系统调用号是不一样的。第三列是系统调用的名字,第四列是系统调用在内核的实现函数。不过,它们都是以sys_开头。
系统调用在内核中的实现函数要有一个声明。声明往往在include/linux/syscalls.h文件中。例如sys_open是这样声明的:
asmlinkage long sys_open(const char __user *filename,
int flags, umode_t mode);
真正的实现这个系统调用,一般在一个.c文件里面,例如sys_open的实现在fs/open.c里面,但是你会发现样子很奇怪。
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
SYSCALL_DEFINE3是一个宏系统调用最多六个参数,根据参数的数目选择宏。具体是这样定义的:
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(SyS##name)))); \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)
如果我们把宏展开之后,实现如下,和声明的是一样的。
asmlinkage long sys_open(const char __user * filename, int flags, int mode)
{
long ret;
if (force_o_largefile())
flags |= O_LARGEFILE;
ret = do_sys_open(AT_FDCWD, filename, flags, mode);
asmlinkage_protect(3, ret, filename, flags, mode);
return ret;
声明和实现都好了。接下来,在编译的过程中,需要根据syscall_32.tbl和syscall_64.tbl生成自己的unistd_32.h和unistd_64.h。生成方式在arch/x86/entry/syscalls/Makefile中。
这里面会使用两个脚本,其中第一个脚本arch/x86/entry/syscalls/syscallhdr.sh,会在文件中生成#define __NR_open;第二个脚本arch/x86/entry/syscalls/syscalltbl.sh,会在文件中生成__SYSCALL(__NR_open, sys_open)。这样,unistd_32.h和unistd_64.h是对应的系统调用号和系统调用实现函数之间的对应关系。
在文件arch/x86/entry/syscall_32.c,定义了这样一个表,里面include了这个头文件,从而所有的sys_系统调用都在这个表里面了。
__visible const sys_call_ptr_t ia32_sys_call_table[__NR_syscall_compat_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_compat_max] = &sys_ni_syscall,
#include <asm/syscalls_32.h>
};
同理,在文件arch/x86/entry/syscall_64.c,定义了这样一个表,里面include了这个头文件,这样所有的sys_系统调用就都在这个表里面了。
/* System call table for x86-64. */
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
系统调用的过程还是挺复杂的吧?如果加上上一节的内核态和用户态的模式切换,就更复杂了。这里我们重点分析64位的系统调用,我将整个完整的过程画了一张图,帮你总结、梳理一下。
请你根据这一节的分析,看一下与open这个系统调用相关的文件都有哪些,在每个文件里面都做了什么?如果你要自己实现一个系统调用,能不能照着open来一个呢?
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。

评论