上一节,我们讲了虚拟空间的布局。接下来,我们需要知道,如何将其映射成为物理地址呢?
你可能已经想到了,咱们前面讲x86 CPU的时候,讲过分段机制,咱们规划虚拟空间的时候,也是将空间分成多个段进行保存。
那就直接用分段机制呗。我们来看看分段机制的原理。
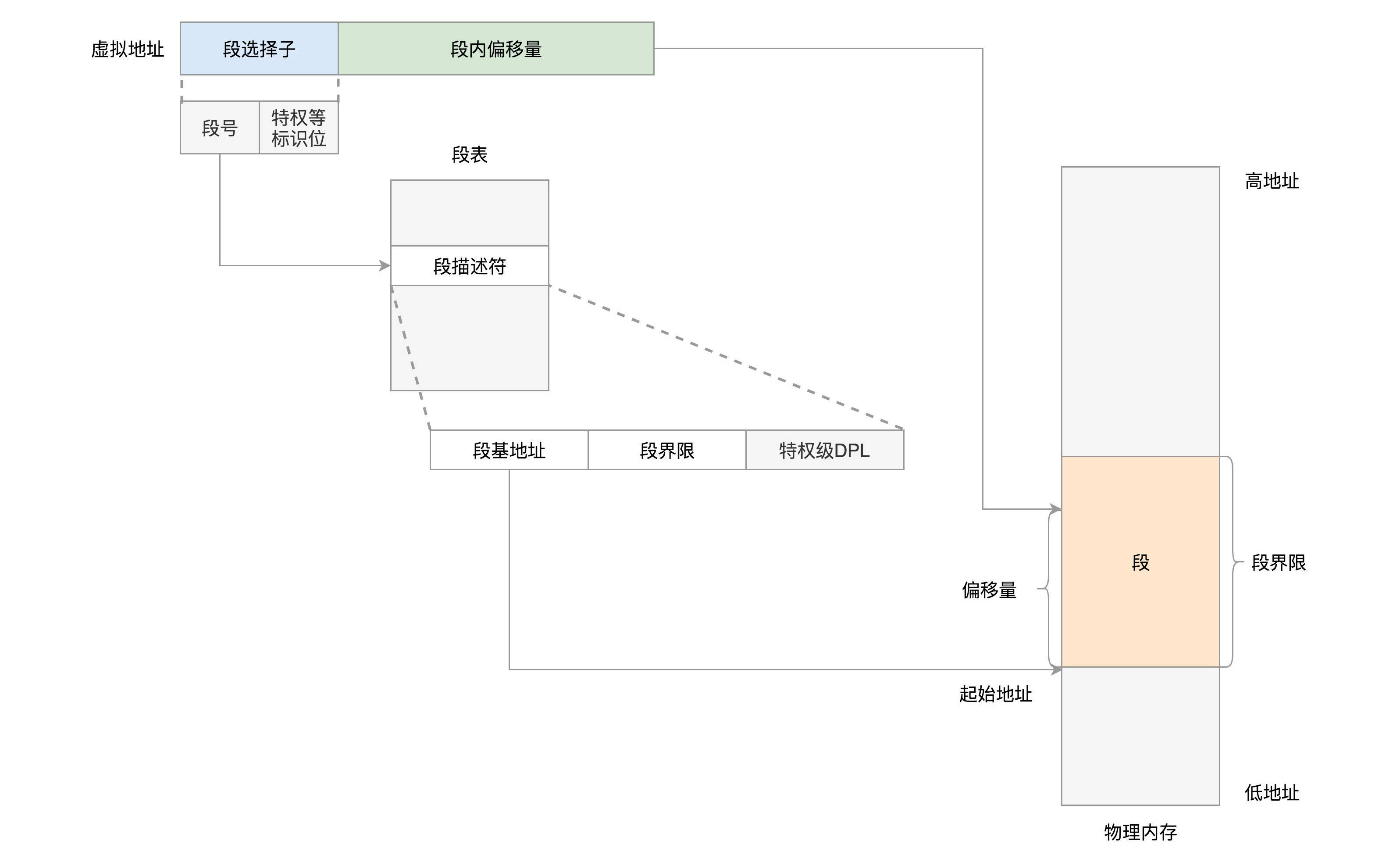
分段机制下的虚拟地址由两部分组成,段选择子和段内偏移量。段选择子就保存在咱们前面讲过的段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。虚拟地址中的段内偏移量应该位于0和段界限之间。如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
例如,我们将上面的虚拟空间分成以下4个段,用0~3来编号。每个段在段表中有一个项,在物理空间中,段的排列如下图的右边所示。
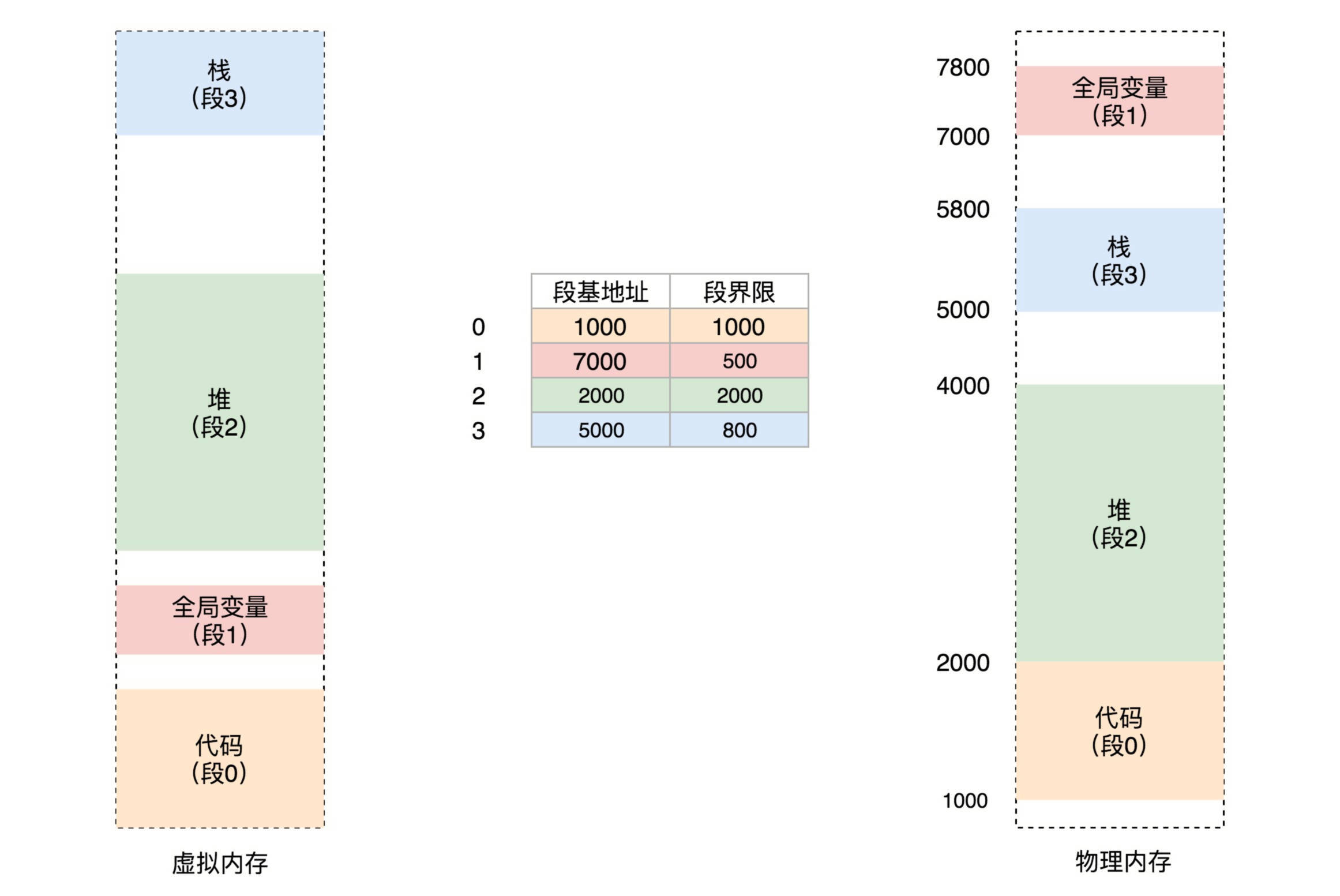
如果要访问段2中偏移量600的虚拟地址,我们可以计算出物理地址为,段2基地址2000 + 偏移量600 = 2600。
多好的机制啊!我们来看看Linux是如何使用这个机制的。
在Linux里面,段表全称段描述符表(segment descriptors),放在全局描述符表GDT(Global Descriptor Table)里面,会有下面的宏来初始化段描述符表里面的表项。
#define GDT_ENTRY_INIT(flags, base, limit) { { { \
.a = ((limit) & 0xffff) | (((base) & 0xffff) << 16), \
.b = (((base) & 0xff0000) >> 16) | (((flags) & 0xf0ff) << 8) | \
((limit) & 0xf0000) | ((base) & 0xff000000), \
} } }
一个段表项由段基地址base、段界限limit,还有一些标识符组成。
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
#ifdef CONFIG_X86_64
[GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),
#else
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
......
#endif
} };
EXPORT_PER_CPU_SYMBOL_GPL(gdt_page);
这里面对于64位的和32位的,都定义了内核代码段、内核数据段、用户代码段和用户数据段。
另外,还会定义下面四个段选择子,指向上面的段描述符表项。这四个段选择子看着是不是有点眼熟?咱们讲内核初始化的时候,启动第一个用户态的进程,就是将这四个值赋值给段寄存器。
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS*8)
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8)
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8 + 3)
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8 + 3)
通过分析,我们发现,所有的段的起始地址都是一样的,都是0。这算哪门子分段嘛!所以,在Linux操作系统中,并没有使用到全部的分段功能。那分段是不是完全没有用处呢?分段可以做权限审核,例如用户态DPL是3,内核态DPL是0。当用户态试图访问内核态的时候,会因为权限不足而报错。
其实Linux倾向于另外一种从虚拟地址到物理地址的转换方式,称为分页(Paging)。
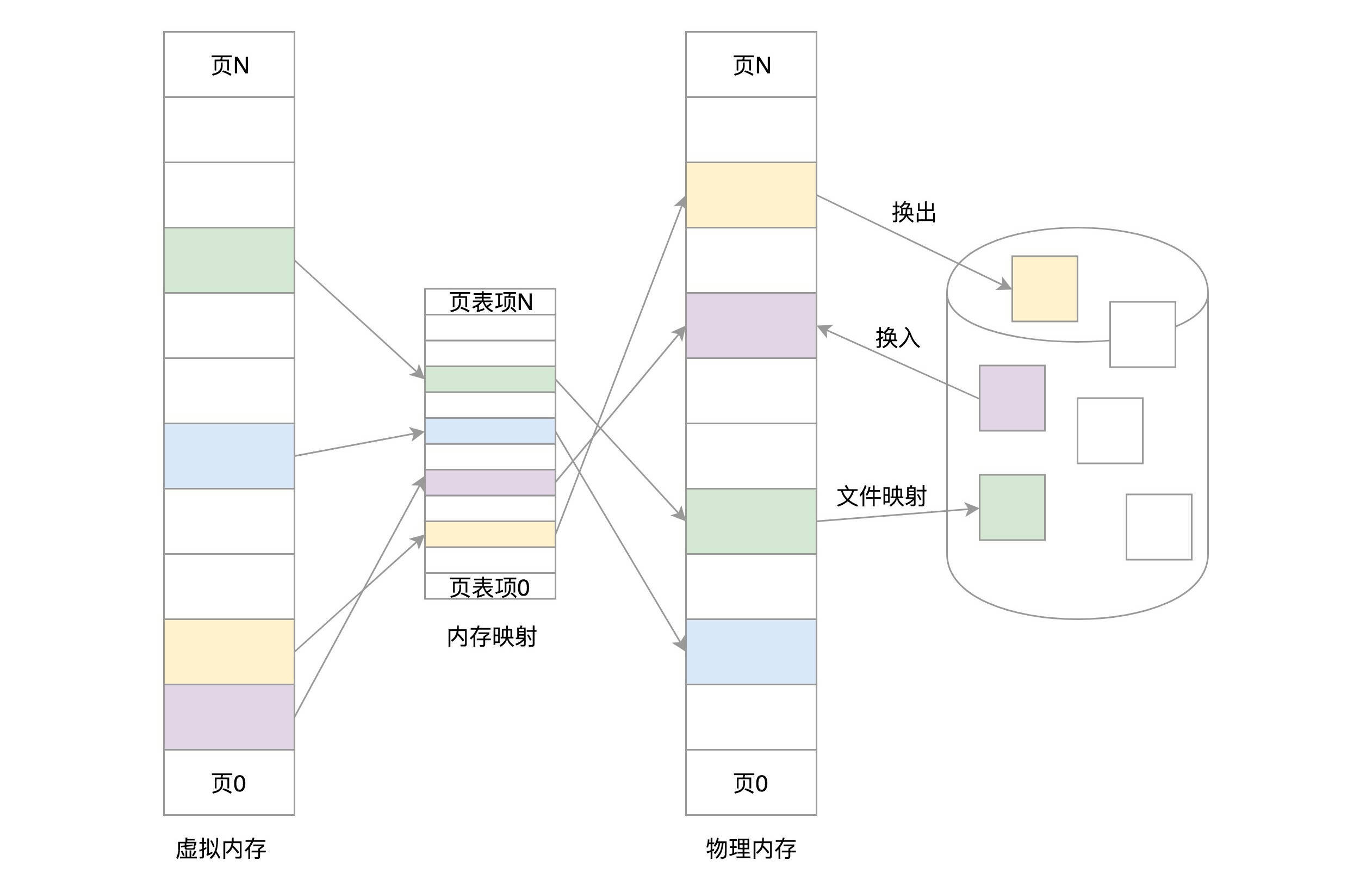
对于物理内存,操作系统把它分成一块一块大小相同的页,这样更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为换出。一旦需要的时候,再加载进来,叫做换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率。
这个换入和换出都是以页为单位的。页面的大小一般为4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址,再加上在页内的偏移量,组成线性地址,就能对于内存中的每个位置进行访问了。
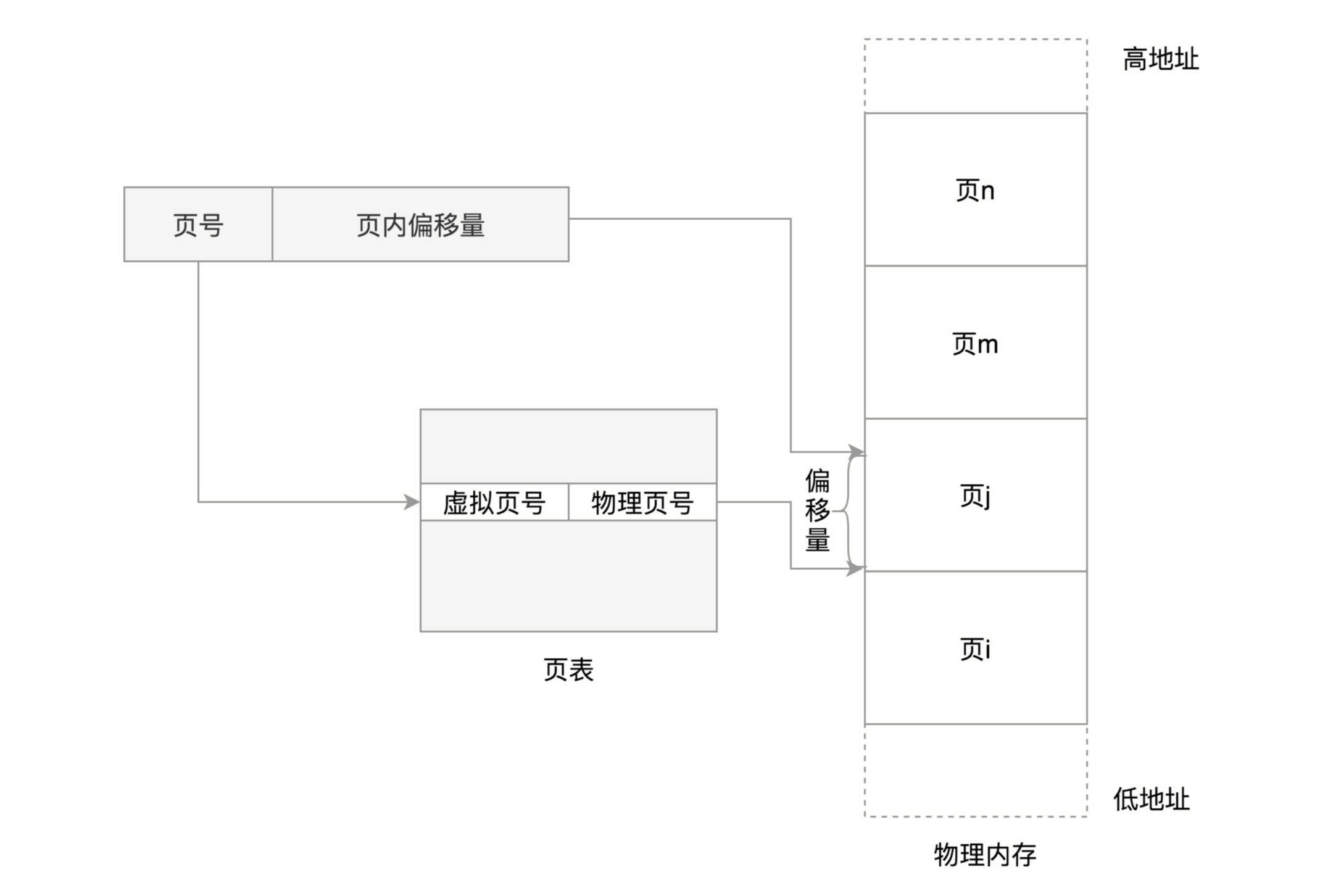
虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址。这个基地址与页内偏移的组合就形成了物理内存地址。
下面的图,举了一个简单的页表的例子,虚拟内存中的页通过页表映射为了物理内存中的页。
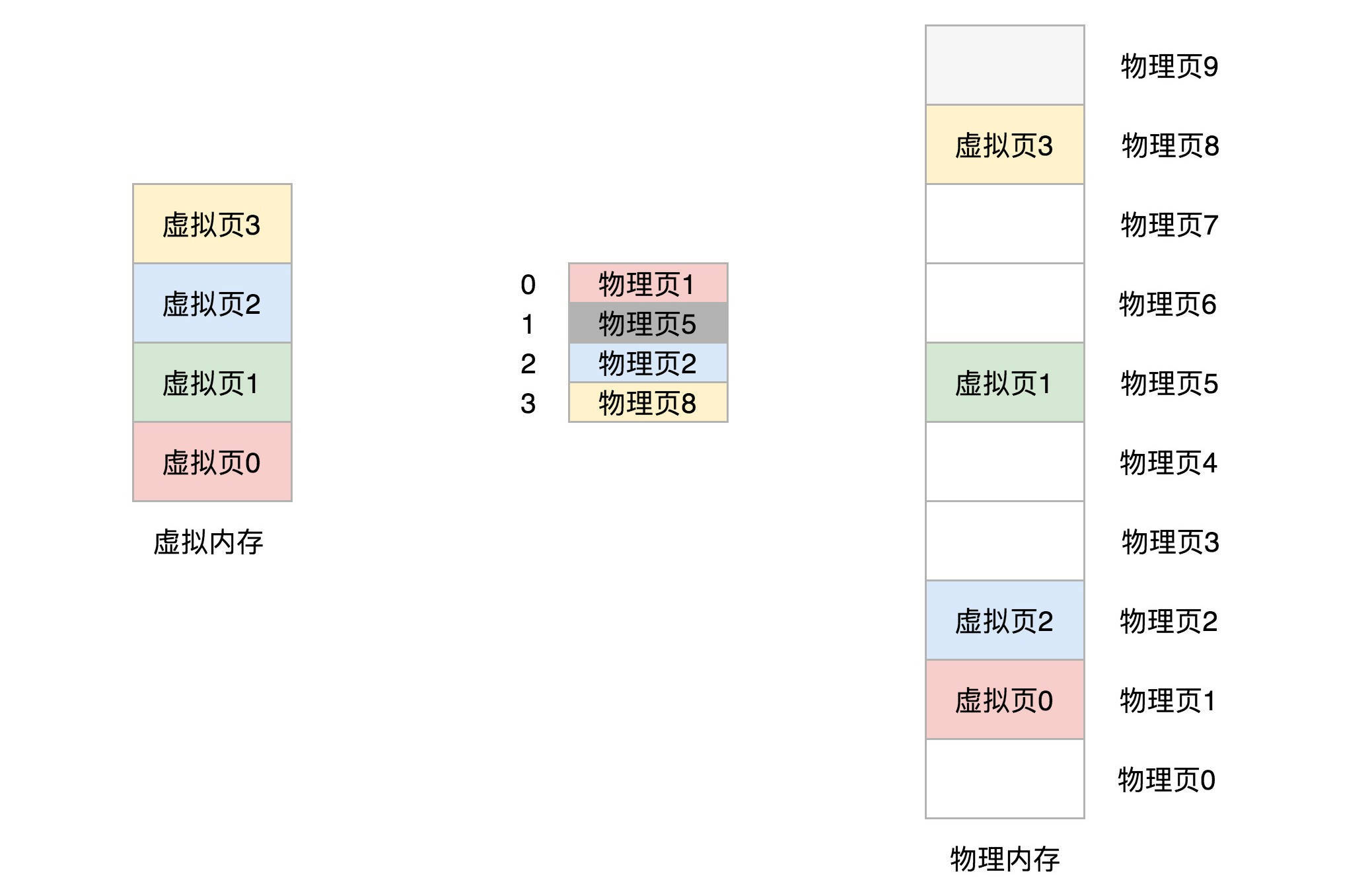
32位环境下,虚拟地址空间共4GB。如果分成4KB一个页,那就是1M个页。每个页表项需要4个字节来存储,那么整个4GB空间的映射就需要4MB的内存来存储映射表。如果每个进程都有自己的映射表,100个进程就需要400MB的内存。对于内核来讲,有点大了 。
页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。
那怎么办呢?我们可以试着将页表再分页,4G的空间需要4M的页表来存储映射。我们把这4M分成1K(1024)个4K,每个4K又能放在一页里面,这样1K个4K就是1K个页,这1K个页也需要一个表进行管理,我们称为页目录表,这个页目录表里面有1K项,每项4个字节,页目录表大小也是4K。
页目录有1K项,用10位就可以表示访问页目录的哪一项。这一项其实对应的是一整页的页表项,也即4K的页表项。每个页表项也是4个字节,因而一整页的页表项是1K个。再用10位就可以表示访问页表项的哪一项,页表项中的一项对应的就是一个页,是存放数据的页,这个页的大小是4K,用12位可以定位这个页内的任何一个位置。
这样加起来正好32位,也就是用前10位定位到页目录表中的一项。将这一项对应的页表取出来共1k项,再用中间10位定位到页表中的一项,将这一项对应的存放数据的页取出来,再用最后12位定位到页中的具体位置访问数据。
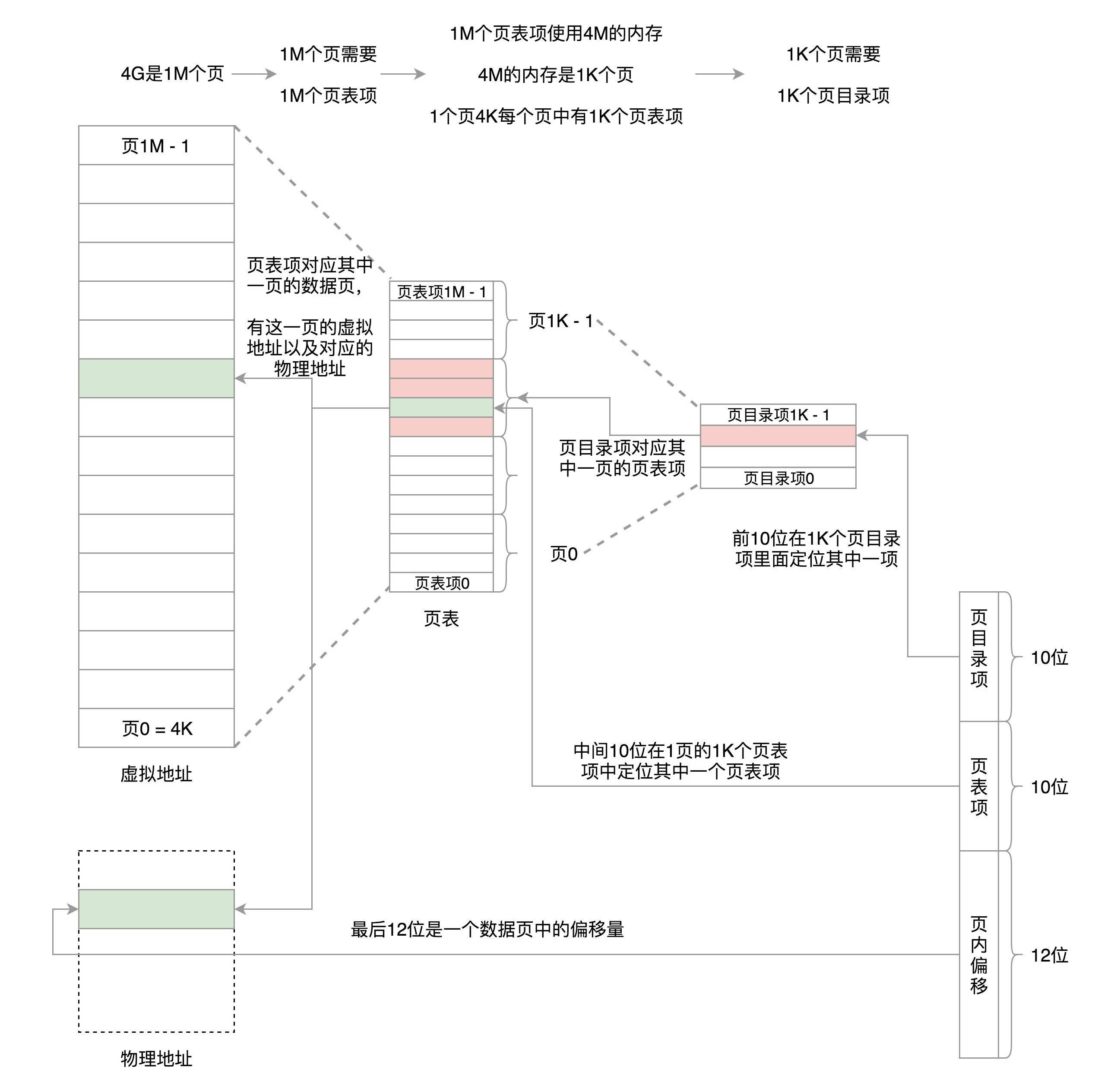
你可能会问,如果这样的话,映射4GB地址空间就需要4MB+4KB的内存,这样不是更大了吗? 当然如果页是满的,当时是更大了,但是,我们往往不会为一个进程分配那么多内存。
比如说,上面图中,我们假设只给这个进程分配了一个数据页。如果只使用页表,也需要完整的1M个页表项共4M的内存,但是如果使用了页目录,页目录需要1K个全部分配,占用内存4K,但是里面只有一项使用了。到了页表项,只需要分配能够管理那个数据页的页表项页就可以了,也就是说,最多4K,这样内存就节省多了。
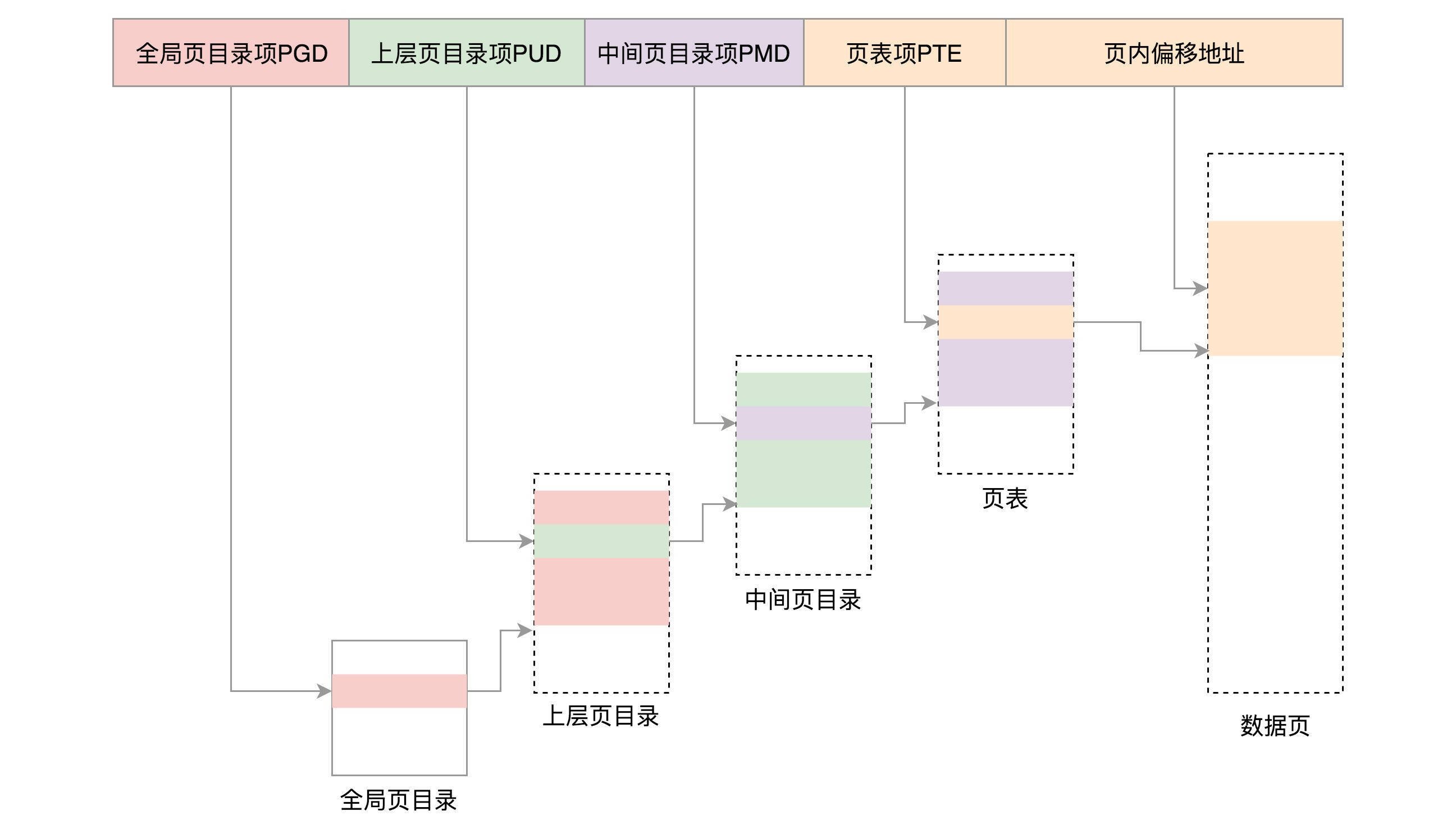
当然对于64位的系统,两级肯定不够了,就变成了四级目录,分别是全局页目录项PGD(Page Global Directory)、上层页目录项PUD(Page Upper Directory)、中间页目录项PMD(Page Middle Directory)和页表项PTE(Page Table Entry)。
这一节我们讲了分段机制、分页机制以及从虚拟地址到物理地址的映射方式。总结一下这两节,我们可以把内存管理系统精细化为下面三件事情:
第一,虚拟内存空间的管理,将虚拟内存分成大小相等的页;
第二,物理内存的管理,将物理内存分成大小相等的页;
第三,内存映射,将虚拟内存页和物理内存页映射起来,并且在内存紧张的时候可以换出到硬盘中。
这一节我们说一个页的大小为4K,有时候我们需要为应用配置大页(HugePage)。请你查一下大页的大小及配置方法,咱们后面会用到。
欢迎留言和我分享你的疑惑和见解,也欢迎你收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习、进步。

评论