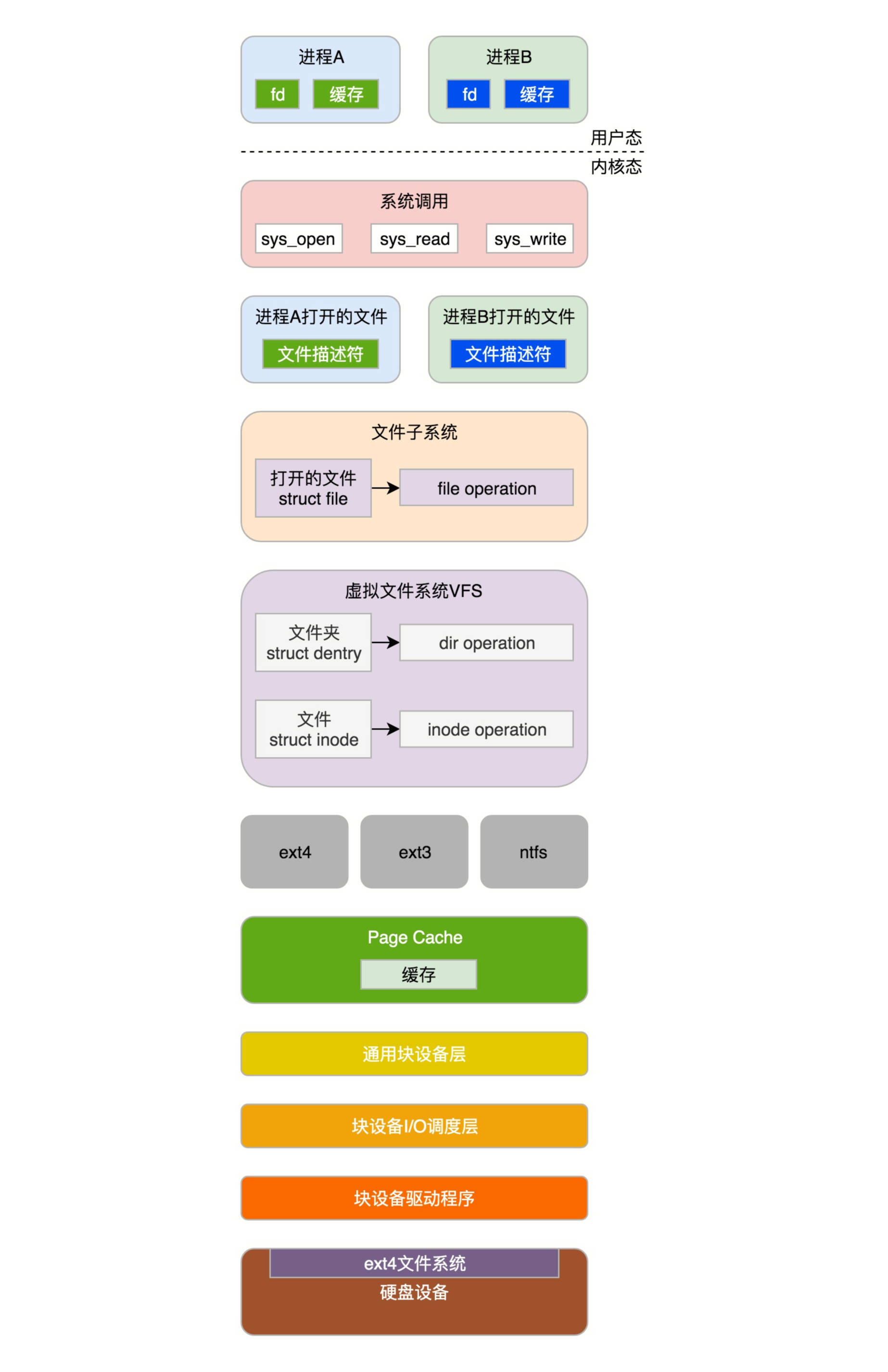
上一节,咱们的图书馆书架,也就是硬盘上的文件系统格式都搭建好了,现在我们还需要一个图书管理与借阅系统,也就是文件管理模块,不然我们怎么知道书都借给谁了呢?
进程要想往文件系统里面读写数据,需要很多层的组件一起合作。具体是怎么合作的呢?我们一起来看一看。
接下来我们逐层解析。
在这之前,有一点你需要注意。解析系统调用是了解内核架构最有力的一把钥匙,这里我们只要重点关注这几个最重要的系统调用就可以了:
想要操作文件系统,第一件事情就是挂载文件系统。
内核是不是支持某种类型的文件系统,需要我们进行注册才能知道。例如,咱们上一节解析的ext4文件系统,就需要通过register_filesystem进行注册,传入的参数是ext4_fs_type,表示注册的是ext4类型的文件系统。这里面最重要的一个成员变量就是ext4_mount。记住它,这个我们后面还会用。
register_filesystem(&ext4_fs_type);
static struct file_system_type ext4_fs_type = {
.owner = THIS_MODULE,
.name = "ext4",
.mount = ext4_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
如果一种文件系统的类型曾经在内核注册过,这就说明允许你挂载并且使用这个文件系统。
刚才我说了几个需要重点关注的系统调用,那我们就从第一个mount系统调用开始解析。mount系统调用的定义如下:
SYSCALL_DEFINE5(mount, char __user *, dev_name, char __user *, dir_name, char __user *, type, unsigned long, flags, void __user *, data)
{
......
ret = do_mount(kernel_dev, dir_name, kernel_type, flags, options);
......
}
接下来的调用链为:do_mount->do_new_mount->vfs_kern_mount。
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
......
mnt = alloc_vfsmnt(name);
......
root = mount_fs(type, flags, name, data);
......
mnt->mnt.mnt_root = root;
mnt->mnt.mnt_sb = root->d_sb;
mnt->mnt_mountpoint = mnt->mnt.mnt_root;
mnt->mnt_parent = mnt;
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts);
return &mnt->mnt;
}
vfs_kern_mount先是创建struct mount结构,每个挂载的文件系统都对应于这样一个结构。
struct mount {
struct hlist_node mnt_hash;
struct mount *mnt_parent;
struct dentry *mnt_mountpoint;
struct vfsmount mnt;
union {
struct rcu_head mnt_rcu;
struct llist_node mnt_llist;
};
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
struct list_head mnt_instance; /* mount instance on sb->s_mounts */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
......
} __randomize_layout;
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
} __randomize_layout;
其中,mnt_parent是装载点所在的父文件系统,mnt_mountpoint是装载点在父文件系统中的dentry;struct dentry表示目录,并和目录的inode关联;mnt_root是当前文件系统根目录的dentry,mnt_sb是指向超级块的指针。
接下来,我们来看调用mount_fs挂载文件系统。
struct dentry *
mount_fs(struct file_system_type *type, int flags, const char *name, void *data)
{
struct dentry *root;
struct super_block *sb;
......
root = type->mount(type, flags, name, data);
......
sb = root->d_sb;
......
}
这里调用的是ext4_fs_type的mount函数,也就是咱们上面提到的ext4_mount,从文件系统里面读取超级块。在文件系统的实现中,每个在硬盘上的结构,在内存中也对应相同格式的结构。当所有的数据结构都读到内存里面,内核就可以通过操作这些数据结构,来操作文件系统了。
可以看出来,理解各个数据结构在这里的关系,非常重要。我这里举一个例子,来解析经过mount之后,刚刚那些数据结构之间的关系。
我们假设根文件系统下面有一个目录home,有另外一个文件系统A挂载在这个目录home下面。在文件系统A的根目录下面有另外一个文件夹hello。由于文件系统A已经挂载到了目录home下面,所以我们就有了目录/home/hello,然后有另外一个文件系统B挂载在/home/hello下面。在文件系统B的根目录下面有另外一个文件夹world,在world下面有个文件夹data。由于文件系统B已经挂载到了/home/hello下面,所以我们就有了目录/home/hello/world/data。
为了维护这些关系,操作系统创建了这一系列数据结构。具体你可以看下面的图。
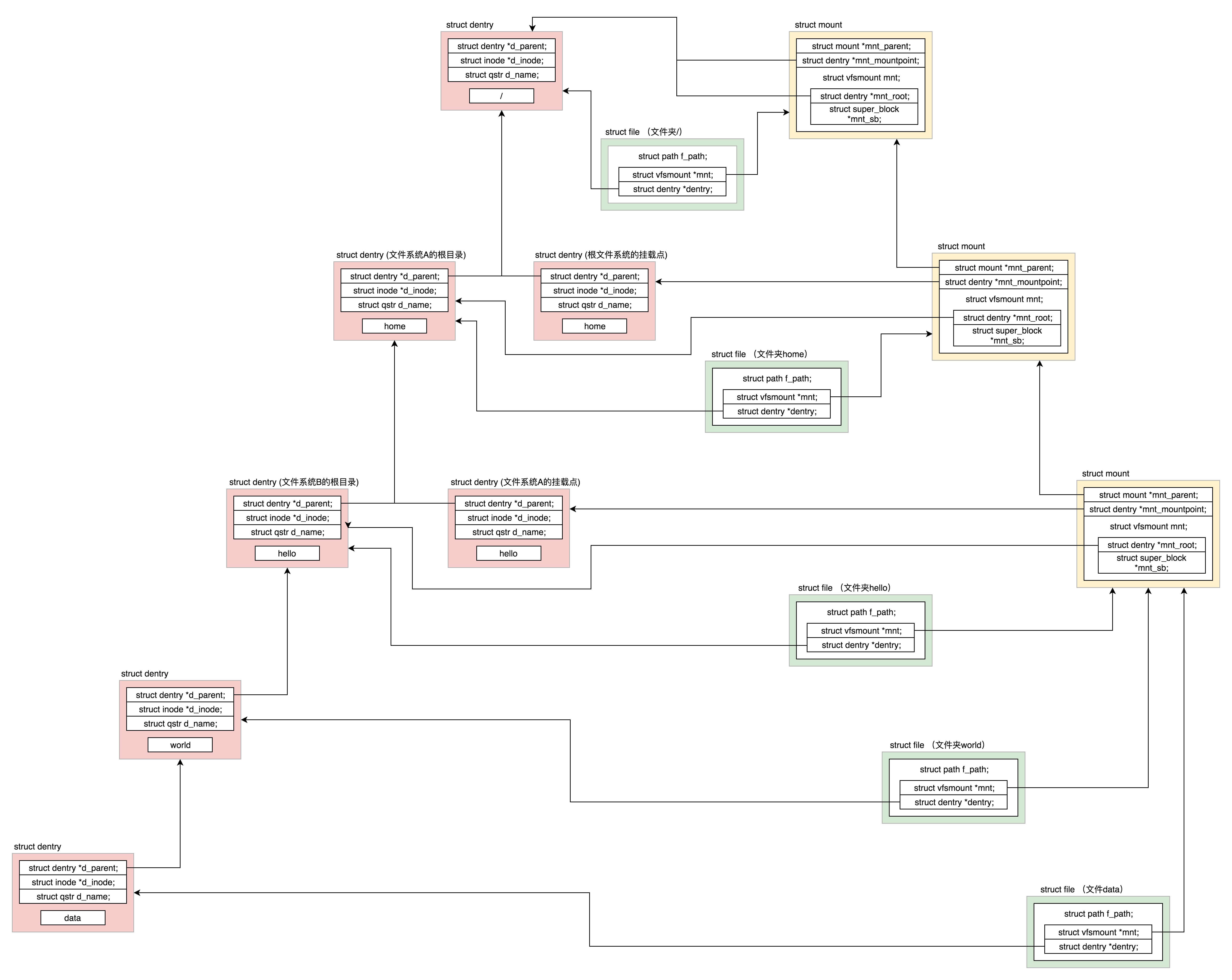
文件系统是树形关系。如果所有的文件夹都是几代单传,那就变成了一条线。你注意看图中的三条斜线。
第一条线是最左边的向左斜的dentry斜线。每一个文件和文件夹都有dentry,用于和inode关联。第二条线是最右面的向右斜的mount斜线,因为这个例子涉及两次文件系统的挂载,再加上启动的时候挂载的根文件系统,一共三个mount。第三条线是中间的向右斜的file斜线,每个打开的文件都有一个file结构,它里面有两个变量,一个指向相应的mount,一个指向相应的dentry。
我们从最上面往下看。根目录/对应一个dentry,根目录是在根文件系统上的,根文件系统是系统启动的时候挂载的,因而有一个mount结构。这个mount结构的mount point指针和mount root指针都是指向根目录的dentry。根目录对应的file的两个指针,一个指向根目录的dentry,一个指向根目录的挂载结构mount。
我们再来看第二层。下一层目录home对应了两个dentry,而且它们的parent都指向第一层的dentry。这是为什么呢?这是因为文件系统A挂载到了这个目录下。这使得这个目录有两个用处。一方面,home是根文件系统的一个挂载点;另一方面,home是文件系统A的根目录。
因为还有一次挂载,因而又有了一个mount结构。这个mount结构的mount point指针指向作为挂载点的那个dentry。mount root指针指向作为根目录的那个dentry,同时parent指针指向第一层的mount结构。home对应的file的两个指针,一个指向文件系统A根目录的dentry,一个指向文件系统A的挂载结构mount。
我们再来看第三层。目录hello又挂载了一个文件系统B,所以第三层的结构和第二层几乎一样。
接下来是第四层。目录world就是一个普通的目录。只要它的dentry的parent指针指向上一层就可以了。我们来看world对应的file结构。由于挂载点不变,还是指向第三层的mount结构。
接下来是第五层。对于文件data,是一个普通的文件,它的dentry的parent指向第四层的dentry。对于data对应的file结构,由于挂载点不变,还是指向第三层的mount结构。
接下来,我们从分析Open系统调用说起。
在系统调用的那一节,我们知道,在进程里面通过open系统调用打开文件,最终对调用到内核的系统调用实现sys_open。当时我们仅仅解析了系统调用的原理,没有接着分析下去,现在我们接着分析这个过程。
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
......
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
......
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}
要打开一个文件,首先要通过get_unused_fd_flags得到一个没有用的文件描述符。如何获取这个文件描述符呢?
在每一个进程的task_struct中,有一个指针files,类型是files_struct。
struct files_struct *files;
files_struct里面最重要的是一个文件描述符列表,每打开一个文件,就会在这个列表中分配一项,下标就是文件描述符。
struct files_struct {
......
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
对于任何一个进程,默认情况下,文件描述符0表示stdin标准输入,文件描述符1表示stdout标准输出,文件描述符2表示stderr标准错误输出。另外,再打开的文件,都会从这个列表中找一个空闲位置分配给它。
文件描述符列表的每一项都是一个指向struct file的指针,也就是说,每打开一个文件,都会有一个struct file对应。
do_sys_open中调用do_filp_open,就是创建这个struct file结构,然后fd_install(fd, f)是将文件描述符和这个结构关联起来。
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
......
set_nameidata(&nd, dfd, pathname);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
......
restore_nameidata();
return filp;
}
do_filp_open里面首先初始化了struct nameidata这个结构。我们知道,文件都是一串的路径名称,需要逐个解析。这个结构在解析和查找路径的时候提供辅助作用。
在struct nameidata里面有一个关键的成员变量struct path。
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
} __randomize_layout;
其中,struct vfsmount和文件系统的挂载有关。另一个struct dentry,除了上面说的用于标识目录之外,还可以表示文件名,还会建立文件名及其inode之间的关联。
接下来就调用path_openat,主要做了以下几件事情:
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
......
file = get_empty_filp();
......
s = path_init(nd, flags);
......
while (!(error = link_path_walk(s, nd)) &&
(error = do_last(nd, file, op, &opened)) > 0) {
......
}
terminate_walk(nd);
......
return file;
}
例如,文件“/root/hello/world/data”,link_path_walk会解析前面的路径部分“/root/hello/world”,解析完毕的时候nameidata的dentry为路径名的最后一部分的父目录“/root/hello/world”,而nameidata的filename为路径名的最后一部分“data”。
最后一部分的解析和处理,我们交给do_last。
static int do_last(struct nameidata *nd,
struct file *file, const struct open_flags *op,
int *opened)
{
......
error = lookup_fast(nd, &path, &inode, &seq);
......
error = lookup_open(nd, &path, file, op, got_write, opened);
......
error = vfs_open(&nd->path, file, current_cred());
......
}
在这里面,我们需要先查找文件路径最后一部分对应的dentry。如何查找呢?
Linux为了提高目录项对象的处理效率,设计与实现了目录项高速缓存dentry cache,简称dcache。它主要由两个数据结构组成:
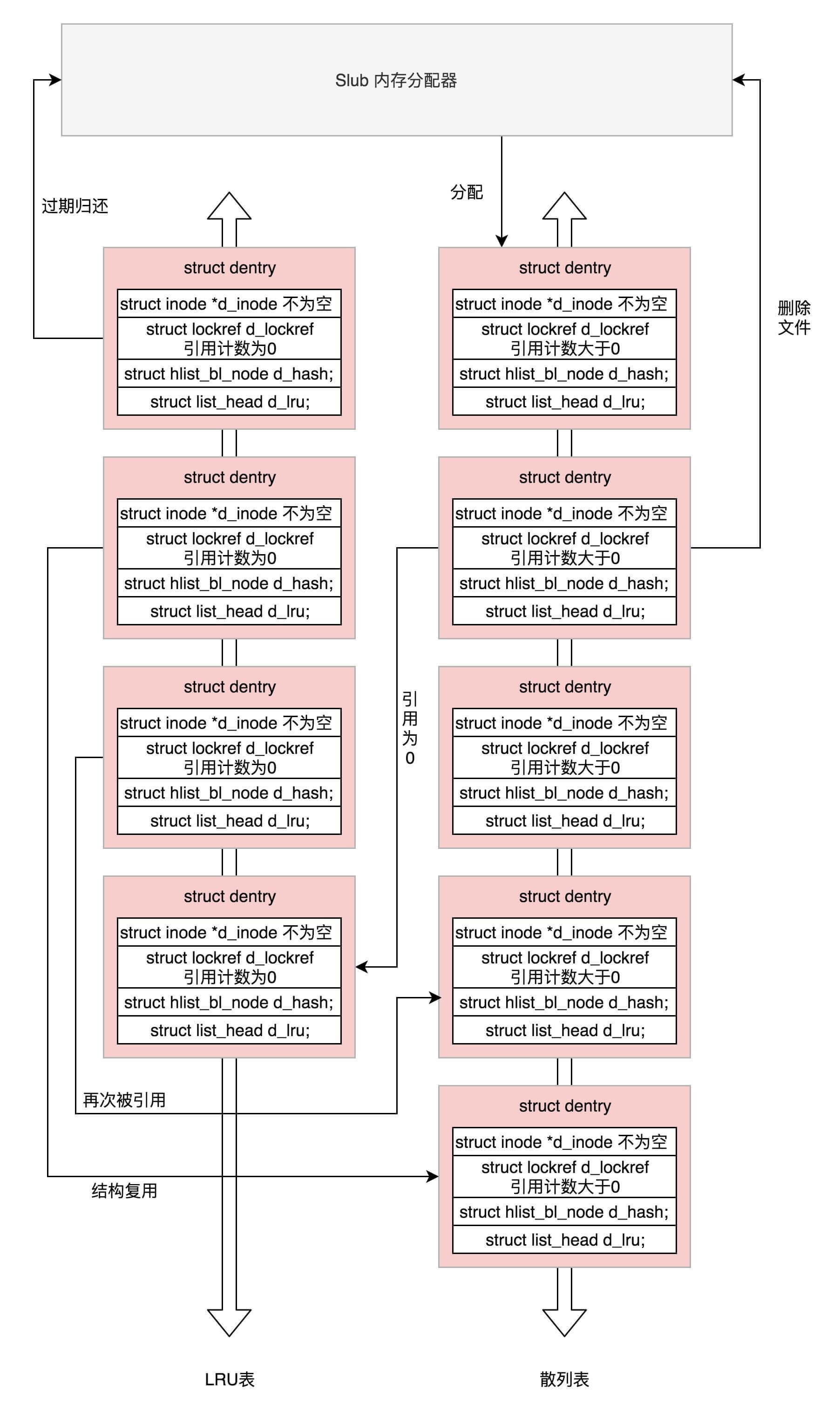
这两个列表之间会产生复杂的关系:
所以,do_last()在查找dentry的时候,当然先从缓存中查找,调用的是lookup_fast。
如果缓存中没有找到,就需要真的到文件系统里面去找了,lookup_open会创建一个新的dentry,并且调用上一级目录的Inode的inode_operations的lookup函数,对于ext4来讲,调用的是ext4_lookup,会到咱们上一节讲的文件系统里面去找inode。最终找到后将新生成的dentry赋给path变量。
static int lookup_open(struct nameidata *nd, struct path *path,
struct file *file,
const struct open_flags *op,
bool got_write, int *opened)
{
......
dentry = d_alloc_parallel(dir, &nd->last, &wq);
......
struct dentry *res = dir_inode->i_op->lookup(dir_inode, dentry,
nd->flags);
......
path->dentry = dentry;
path->mnt = nd->path.mnt;
}
const struct inode_operations ext4_dir_inode_operations = {
.create = ext4_create,
.lookup = ext4_lookup,
...
do_last()的最后一步是调用vfs_open真正打开文件。
int vfs_open(const struct path *path, struct file *file,
const struct cred *cred)
{
struct dentry *dentry = d_real(path->dentry, NULL, file->f_flags, 0);
......
file->f_path = *path;
return do_dentry_open(file, d_backing_inode(dentry), NULL, cred);
}
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *),
const struct cred *cred)
{
......
f->f_mode = OPEN_FMODE(f->f_flags) | FMODE_LSEEK |
FMODE_PREAD | FMODE_PWRITE;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
......
f->f_op = fops_get(inode->i_fop);
......
open = f->f_op->open;
......
error = open(inode, f);
......
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
return 0;
......
}
const struct file_operations ext4_file_operations = {
......
.open = ext4_file_open,
......
};
vfs_open里面最终要做的一件事情是,调用f_op->open,也就是调用ext4_file_open。另外一件重要的事情是将打开文件的所有信息,填写到struct file这个结构里面。
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
spinlock_t f_lock;
enum rw_hint f_write_hint;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
......
struct address_space *f_mapping;
errseq_t f_wb_err;
}
对于虚拟文件系统的解析就到这里了,我们可以看出,有关文件的数据结构层次多,而且很复杂,就得到了下面这张图,这张图在这个专栏最开始的时候,已经展示过一遍,到这里,你应该能明白它们之间的关系了。
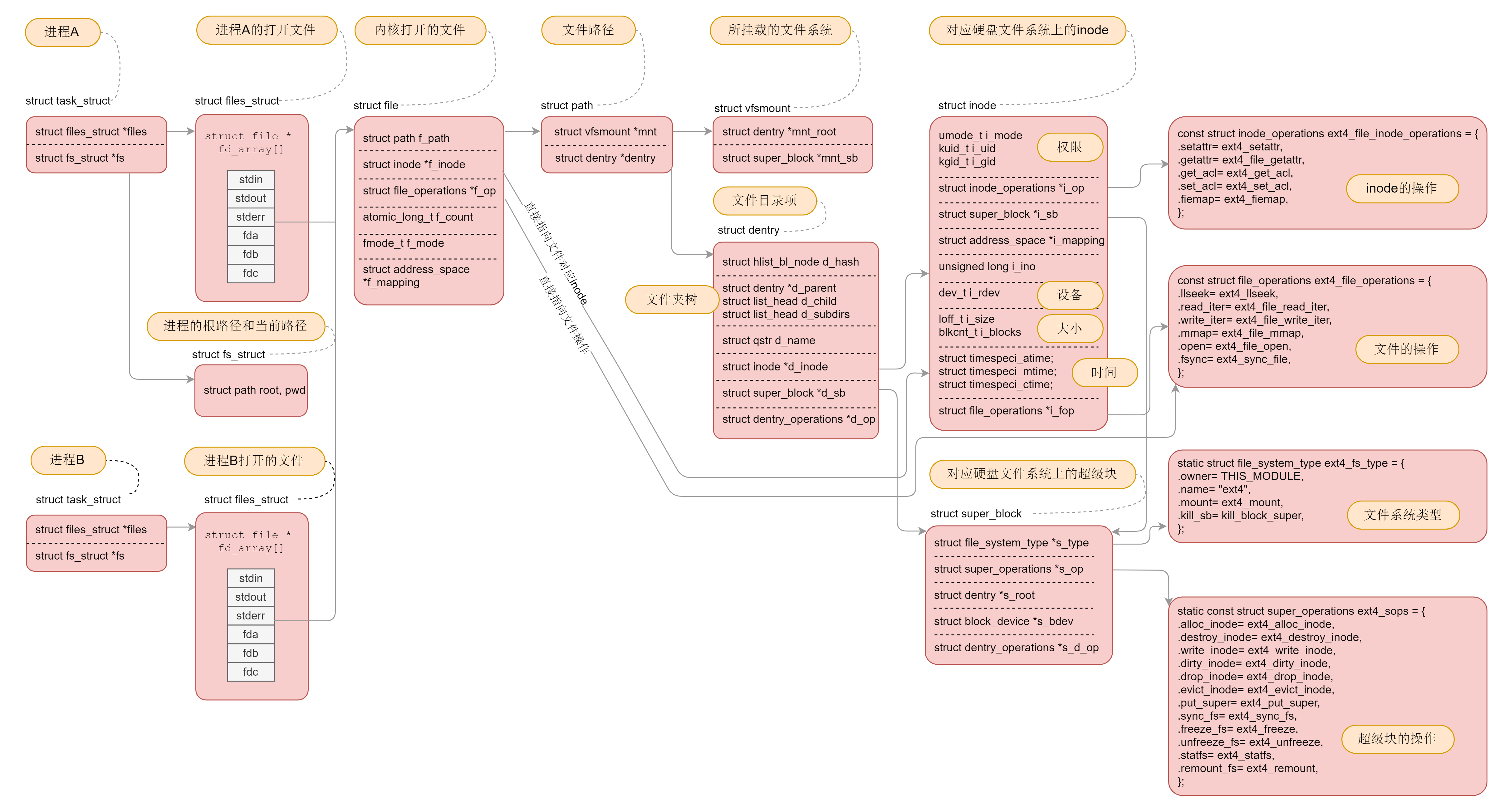
这张图十分重要,一定要掌握。因为我们后面的字符设备、块设备、管道、进程间通信、网络等等,全部都要用到这里面的知识。希望当你再次遇到它的时候,能够马上说出各个数据结构之间的关系。
这里我带你简单做一个梳理,帮助你理解记忆它。
对于每一个进程,打开的文件都有一个文件描述符,在files_struct里面会有文件描述符数组。每个一个文件描述符是这个数组的下标,里面的内容指向一个file结构,表示打开的文件。这个结构里面有这个文件对应的inode,最重要的是这个文件对应的操作file_operation。如果操作这个文件,就看这个file_operation里面的定义了。
对于每一个打开的文件,都有一个dentry对应,虽然叫作directory entry,但是不仅仅表示文件夹,也表示文件。它最重要的作用就是指向这个文件对应的inode。
如果说file结构是一个文件打开以后才创建的,dentry是放在一个dentry cache里面的,文件关闭了,他依然存在,因而他可以更长期地维护内存中的文件的表示和硬盘上文件的表示之间的关系。
inode结构就表示硬盘上的inode,包括块设备号等。
几乎每一种结构都有自己对应的operation结构,里面都是一些方法,因而当后面遇到对于某种结构进行处理的时候,如果不容易找到相应的处理函数,就先找这个operation结构,就清楚了。
上一节的总结中,我们说,同一个文件系统中,文件夹和文件的对应关系。如果跨的是文件系统,你知道如何维护这种映射关系吗?
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

评论