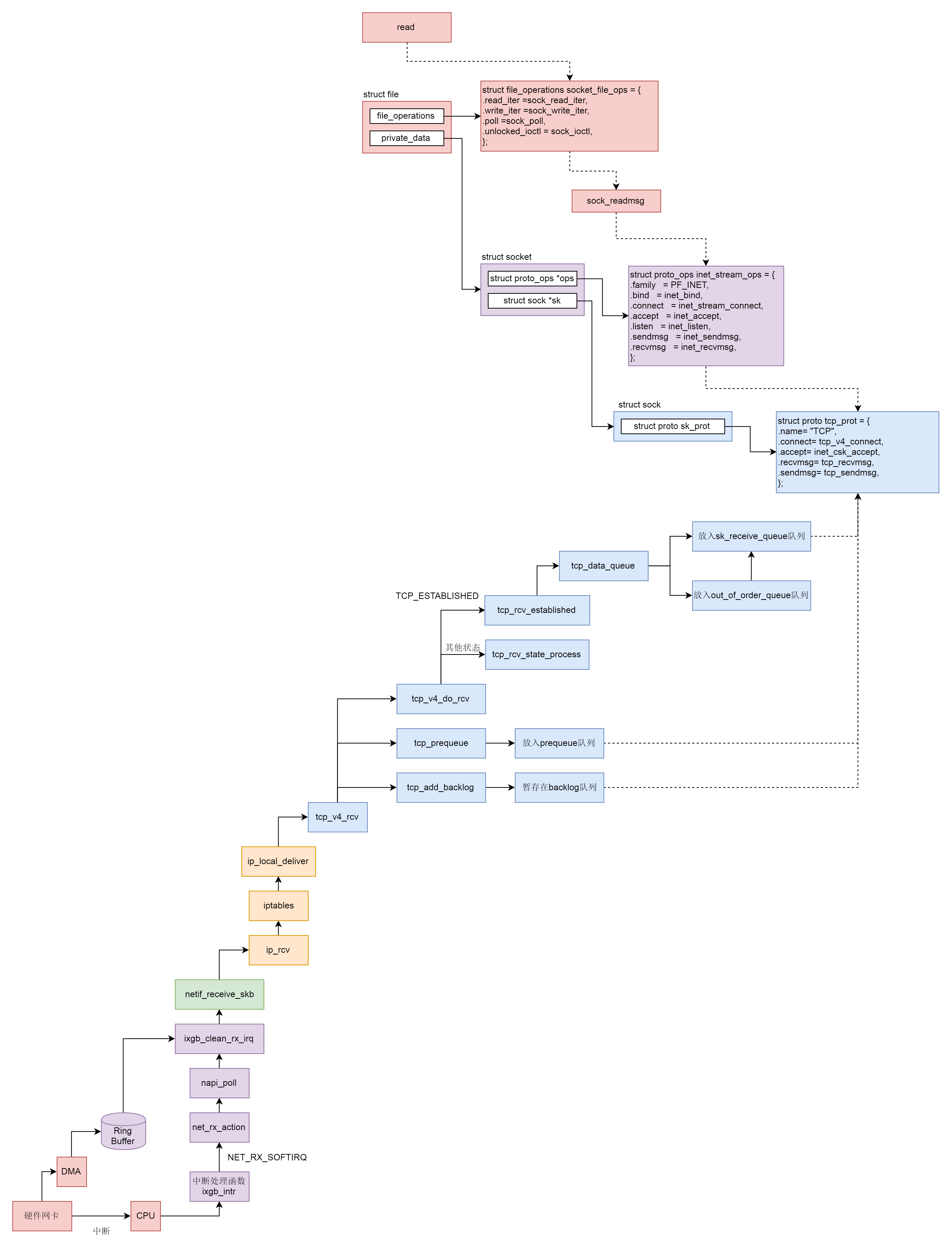
上一节,我们解析了网络包接收的上半部分,从硬件网卡到IP层。这一节,我们接着来解析TCP层和Socket层都做了哪些事情。
从tcp_v4_rcv函数开始,我们的处理逻辑就从IP层到了TCP层。
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret;
......
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
......
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin + skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th);
TCP_SKB_CB(skb)->tcp_tw_isn = 0;
TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph);
TCP_SKB_CB(skb)->sacked = 0;
lookup:
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, &refcounted);
process:
if (sk->sk_state == TCP_TIME_WAIT)
goto do_time_wait;
if (sk->sk_state == TCP_NEW_SYN_RECV) {
......
}
......
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
skb->dev = NULL;
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
......
if (!sock_owned_by_user(sk)) {
if (!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
} else if (tcp_add_backlog(sk, skb)) {
goto discard_and_relse;
}
......
}
在tcp_v4_rcv中,得到TCP的头之后,我们可以开始处理TCP层的事情。因为TCP层是分状态的,状态被维护在数据结构struct sock里面,因而我们要根据IP地址以及TCP头里面的内容,在tcp_hashinfo中找到这个包对应的struct sock,从而得到这个包对应的连接的状态。
接下来,我们就根据不同的状态做不同的处理,例如,上面代码中的TCP_LISTEN、TCP_NEW_SYN_RECV状态属于连接建立过程中。这个我们在讲三次握手的时候讲过了。再如,TCP_TIME_WAIT状态是连接结束的时候的状态,这个我们暂时可以不用看。
接下来,我们来分析最主流的网络包的接收过程,这里面涉及三个队列:
为什么接收网络包的过程,需要在这三个队列里面倒腾过来、倒腾过去呢?这是因为,同样一个网络包要在三个主体之间交接。
第一个主体是软中断的处理过程。如果你没忘记的话,我们在执行tcp_v4_rcv函数的时候,依然处于软中断的处理逻辑里,所以必然会占用这个软中断。
第二个主体就是用户态进程。如果用户态触发系统调用read读取网络包,也要从队列里面找。
第三个主体就是内核协议栈。哪怕用户进程没有调用read,读取网络包,当网络包来的时候,也得有一个地方收着呀。
这时候,我们就能够了解上面代码中sock_owned_by_user的意思了,其实就是说,当前这个sock是不是正有一个用户态进程等着读数据呢,如果没有,内核协议栈也调用tcp_add_backlog,暂存在backlog队列中,并且抓紧离开软中断的处理过程。
如果有一个用户态进程等待读取数据呢?我们先调用tcp_prequeue,也即赶紧放入prequeue队列,并且离开软中断的处理过程。在这个函数里面,我们会看到对于sysctl_tcp_low_latency的判断,也即是不是要低时延地处理网络包。
如果把sysctl_tcp_low_latency设置为0,那就要放在prequeue队列中暂存,这样不用等待网络包处理完毕,就可以离开软中断的处理过程,但是会造成比较长的时延。如果把sysctl_tcp_low_latency设置为1,我们还是调用tcp_v4_do_rcv。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
......
tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len);
return 0;
}
......
if (tcp_rcv_state_process(sk, skb)) {
......
}
return 0;
......
}
在tcp_v4_do_rcv中,分两种情况,一种情况是连接已经建立,处于TCP_ESTABLISHED状态,调用tcp_rcv_established。另一种情况,就是其他的状态,调用tcp_rcv_state_process。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
case TCP_CLOSE:
......
case TCP_LISTEN:
......
case TCP_SYN_SENT:
......
}
......
switch (sk->sk_state) {
case TCP_SYN_RECV:
......
case TCP_FIN_WAIT1:
......
case TCP_CLOSING:
......
case TCP_LAST_ACK:
......
}
/* step 7: process the segment text */
switch (sk->sk_state) {
case TCP_CLOSE_WAIT:
case TCP_CLOSING:
case TCP_LAST_ACK:
......
case TCP_FIN_WAIT1:
case TCP_FIN_WAIT2:
......
case TCP_ESTABLISHED:
......
}
}
在tcp_rcv_state_process中,如果我们对着TCP的状态图进行比对,能看到,对于TCP所有状态的处理,其中和连接建立相关的状态,咱们已经分析过,所以我们重点关注连接状态下的工作模式。
在连接状态下,我们会调用tcp_rcv_established。在这个函数里面,我们会调用tcp_data_queue,将其放入sk_receive_queue队列进行处理。
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
bool fragstolen = false;
......
if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
if (tcp_receive_window(tp) == 0)
goto out_of_window;
/* Ok. In sequence. In window. */
if (tp->ucopy.task == current &&
tp->copied_seq == tp->rcv_nxt && tp->ucopy.len &&
sock_owned_by_user(sk) && !tp->urg_data) {
int chunk = min_t(unsigned int, skb->len,
tp->ucopy.len);
__set_current_state(TASK_RUNNING);
if (!skb_copy_datagram_msg(skb, 0, tp->ucopy.msg, chunk)) {
tp->ucopy.len -= chunk;
tp->copied_seq += chunk;
eaten = (chunk == skb->len);
tcp_rcv_space_adjust(sk);
}
}
if (eaten <= 0) {
queue_and_out:
......
eaten = tcp_queue_rcv(sk, skb, 0, &fragstolen);
}
tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq);
......
if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) {
tcp_ofo_queue(sk);
......
}
......
return;
}
if (!after(TCP_SKB_CB(skb)->end_seq, tp->rcv_nxt)) {
/* A retransmit, 2nd most common case. Force an immediate ack. */
tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq);
out_of_window:
tcp_enter_quickack_mode(sk);
inet_csk_schedule_ack(sk);
drop:
tcp_drop(sk, skb);
return;
}
/* Out of window. F.e. zero window probe. */
if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt + tcp_receive_window(tp)))
goto out_of_window;
tcp_enter_quickack_mode(sk);
if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) {
/* Partial packet, seq < rcv_next < end_seq */
tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, tp->rcv_nxt);
/* If window is closed, drop tail of packet. But after
* remembering D-SACK for its head made in previous line.
*/
if (!tcp_receive_window(tp))
goto out_of_window;
goto queue_and_out;
}
tcp_data_queue_ofo(sk, skb);
}
在tcp_data_queue中,对于收到的网络包,我们要分情况进行处理。
第一种情况,seq == tp->rcv_nxt,说明来的网络包正是我服务端期望的下一个网络包。这个时候我们判断sock_owned_by_user,也即用户进程也是正在等待读取,这种情况下,就直接skb_copy_datagram_msg,将网络包拷贝给用户进程就可以了。
如果用户进程没有正在等待读取,或者因为内存原因没有能够拷贝成功,tcp_queue_rcv里面还是将网络包放入sk_receive_queue队列。
接下来,tcp_rcv_nxt_update将tp->rcv_nxt设置为end_seq,也即当前的网络包接收成功后,更新下一个期待的网络包。
这个时候,我们还会判断一下另一个队列,out_of_order_queue,也看看乱序队列的情况,看看乱序队列里面的包,会不会因为这个新的网络包的到来,也能放入到sk_receive_queue队列中。
例如,客户端发送的网络包序号为5、6、7、8、9。在5还没有到达的时候,服务端的rcv_nxt应该是5,也即期望下一个网络包是5。但是由于中间网络通路的问题,5、6还没到达服务端,7、8已经到达了服务端了,这就出现了乱序。
乱序的包不能进入sk_receive_queue队列。因为一旦进入到这个队列,意味着可以发送给用户进程。然而,按照TCP的定义,用户进程应该是按顺序收到包的,没有排好序,就不能给用户进程。所以,7、8不能进入sk_receive_queue队列,只能暂时放在out_of_order_queue乱序队列中。
当5、6到达的时候,5、6先进入sk_receive_queue队列。这个时候我们再来看out_of_order_queue乱序队列中的7、8,发现能够接上。于是,7、8也能进入sk_receive_queue队列了。tcp_ofo_queue函数就是做这个事情的。
至此第一种情况处理完毕。
第二种情况,end_seq不大于rcv_nxt,也即服务端期望网络包5。但是,来了一个网络包3,怎样才会出现这种情况呢?肯定是服务端早就收到了网络包3,但是ACK没有到达客户端,中途丢了,那客户端就认为网络包3没有发送成功,于是又发送了一遍,这种情况下,要赶紧给客户端再发送一次ACK,表示早就收到了。
第三种情况,seq不小于rcv_nxt + tcp_receive_window。这说明客户端发送得太猛了。本来seq肯定应该在接收窗口里面的,这样服务端才来得及处理,结果现在超出了接收窗口,说明客户端一下子把服务端给塞满了。
这种情况下,服务端不能再接收数据包了,只能发送ACK了,在ACK中会将接收窗口为0的情况告知客户端,客户端就知道不能再发送了。这个时候双方只能交互窗口探测数据包,直到服务端因为用户进程把数据读走了,空出接收窗口,才能在ACK里面再次告诉客户端,又有窗口了,又能发送数据包了。
第四种情况,seq小于rcv_nxt,但是end_seq大于rcv_nxt,这说明从seq到rcv_nxt这部分网络包原来的ACK客户端没有收到,所以重新发送了一次,从rcv_nxt到end_seq时新发送的,可以放入sk_receive_queue队列。
当前四种情况都排除掉了,说明网络包一定是一个乱序包了。这里有点儿难理解,我们还是用上面那个乱序的例子仔细分析一下rcv_nxt=5。
我们假设tcp_receive_window也是5,也即超过10服务端就接收不了了。当前来的这个网络包既不在rcv_nxt之前(不是3这种),也不在rcv_nxt + tcp_receive_window之后(不是11这种),说明这正在我们期望的接收窗口里面,但是又不是rcv_nxt(不是我们马上期望的网络包5),这正是上面的例子中网络包7、8的情况。
对于网络包7、8,我们只好调用tcp_data_queue_ofo进入out_of_order_queue乱序队列,但是没有关系,当网络包5、6到来的时候,我们会走第一种情况,把7、8拿出来放到sk_receive_queue队列中。
至此,网络协议栈的处理过程就结束了。
当接收的网络包进入各种队列之后,接下来我们就要等待用户进程去读取它们了。
读取一个socket,就像读取一个文件一样,读取socket的文件描述符,通过read系统调用。
read系统调用对于一个文件描述符的操作,大致过程都是类似的,在文件系统那一节,我们已经详细解析过。最终它会调用到用来表示一个打开文件的结构stuct file指向的file_operations操作。
对于socket来讲,它的file_operations定义如下:
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
按照文件系统的读取流程,调用的是sock_read_iter。
static ssize_t sock_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
struct file *file = iocb->ki_filp;
struct socket *sock = file->private_data;
struct msghdr msg = {.msg_iter = *to,
.msg_iocb = iocb};
ssize_t res;
if (file->f_flags & O_NONBLOCK)
msg.msg_flags = MSG_DONTWAIT;
......
res = sock_recvmsg(sock, &msg, msg.msg_flags);
*to = msg.msg_iter;
return res;
}
在sock_read_iter中,通过VFS中的struct file,将创建好的socket结构拿出来,然后调用sock_recvmsg,sock_recvmsg会调用sock_recvmsg_nosec。
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg, int flags)
{
return sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);
}
这里调用了socket的ops的recvmsg,这个我们遇到好几次了。根据inet_stream_ops的定义,这里调用的是inet_recvmsg。
int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size,
int flags)
{
struct sock *sk = sock->sk;
int addr_len = 0;
int err;
......
err = sk->sk_prot->recvmsg(sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
......
}
这里面,从socket结构,我们可以得到更底层的sock结构,然后调用sk_prot的recvmsg方法。这个同样遇到好几次了,根据tcp_prot的定义,调用的是tcp_recvmsg。
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
struct tcp_sock *tp = tcp_sk(sk);
int copied = 0;
u32 peek_seq;
u32 *seq;
unsigned long used;
int err;
int target; /* Read at least this many bytes */
long timeo;
struct task_struct *user_recv = NULL;
struct sk_buff *skb, *last;
.....
do {
u32 offset;
......
/* Next get a buffer. */
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
offset = *seq - TCP_SKB_CB(skb)->seq;
if (offset < skb->len)
goto found_ok_skb;
......
}
......
if (!sysctl_tcp_low_latency && tp->ucopy.task == user_recv) {
/* Install new reader */
if (!user_recv && !(flags & (MSG_TRUNC | MSG_PEEK))) {
user_recv = current;
tp->ucopy.task = user_recv;
tp->ucopy.msg = msg;
}
tp->ucopy.len = len;
/* Look: we have the following (pseudo)queues:
*
* 1. packets in flight
* 2. backlog
* 3. prequeue
* 4. receive_queue
*
* Each queue can be processed only if the next ones
* are empty.
*/
if (!skb_queue_empty(&tp->ucopy.prequeue))
goto do_prequeue;
}
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else {
sk_wait_data(sk, &timeo, last);
}
if (user_recv) {
int chunk;
chunk = len - tp->ucopy.len;
if (chunk != 0) {
len -= chunk;
copied += chunk;
}
if (tp->rcv_nxt == tp->copied_seq &&
!skb_queue_empty(&tp->ucopy.prequeue)) {
do_prequeue:
tcp_prequeue_process(sk);
chunk = len - tp->ucopy.len;
if (chunk != 0) {
len -= chunk;
copied += chunk;
}
}
}
continue;
found_ok_skb:
/* Ok so how much can we use? */
used = skb->len - offset;
if (len < used)
used = len;
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
......
}
*seq += used;
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
......
} while (len > 0);
......
}
tcp_recvmsg这个函数比较长,里面逻辑也很复杂,好在里面有一段注释概括了这里面的逻辑。注释里面提到了三个队列,receive_queue队列、prequeue队列和backlog队列。这里面,我们需要把前一个队列处理完毕,才处理后一个队列。
tcp_recvmsg的整个逻辑也是这样执行的:这里面有一个while循环,不断地读取网络包。
这里,我们会先处理sk_receive_queue队列。如果找到了网络包,就跳到found_ok_skb这里。这里会调用skb_copy_datagram_msg,将网络包拷贝到用户进程中,然后直接进入下一层循环。
直到sk_receive_queue队列处理完毕,我们才到了sysctl_tcp_low_latency判断。如果不需要低时延,则会有prequeue队列。于是,我们能就跳到do_prequeue这里,调用tcp_prequeue_process进行处理。
如果sysctl_tcp_low_latency设置为1,也即没有prequeue队列,或者prequeue队列为空,则需要处理backlog队列,在release_sock函数中处理。
release_sock会调用__release_sock,这里面会依次处理队列中的网络包。
void release_sock(struct sock *sk)
{
......
if (sk->sk_backlog.tail)
__release_sock(sk);
......
}
static void __release_sock(struct sock *sk)
__releases(&sk->sk_lock.slock)
__acquires(&sk->sk_lock.slock)
{
struct sk_buff *skb, *next;
while ((skb = sk->sk_backlog.head) != NULL) {
sk->sk_backlog.head = sk->sk_backlog.tail = NULL;
do {
next = skb->next;
prefetch(next);
skb->next = NULL;
sk_backlog_rcv(sk, skb);
cond_resched();
skb = next;
} while (skb != NULL);
}
......
}
最后,哪里都没有网络包,我们只好调用sk_wait_data,继续等待在哪里,等待网络包的到来。
至此,网络包的接收过程到此结束。
这一节我们讲完了接收网络包,我们来从头串一下,整个过程可以分成以下几个层次。
至此内核接收网络包的过程到此结束,接下来就是用户态读取网络包的过程,这个过程分成几个层次。
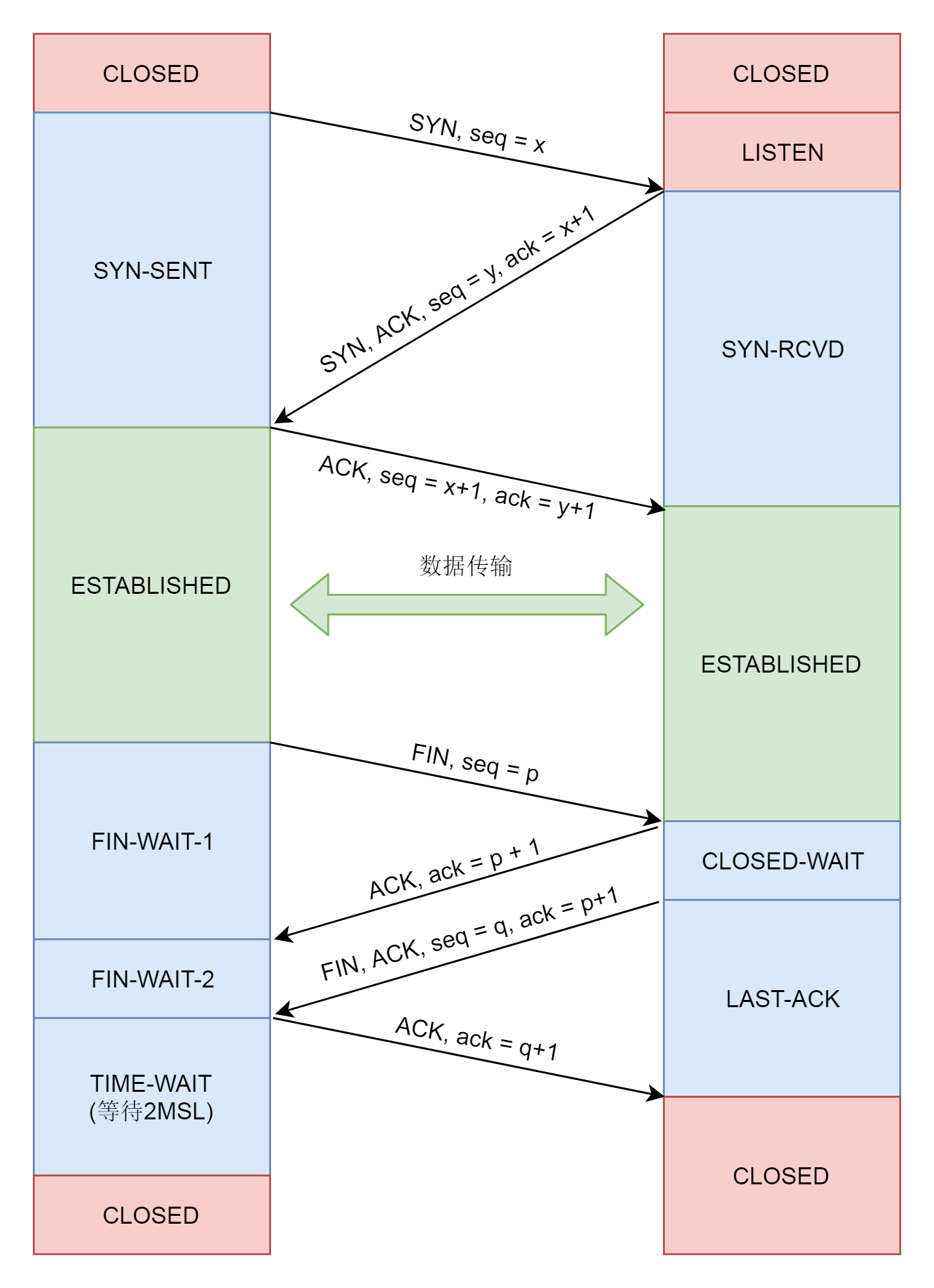
对于TCP协议、三次握手、发送和接收的连接维护、拥塞控制、滑动窗口,我们都解析过了。唯独四次挥手我们没有解析,对应的代码你应该知道在什么地方了,你可以自己试着解析一下四次挥手的过程。
欢迎留言和我分享你的疑惑和见解 ,也欢迎可以收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

评论