上一节qemu初始化的main函数,我们解析了一个开头,得到了表示体系结构的MachineClass以及MachineState。
我们接着回到main函数,接下来初始化的是块设备,调用的是configure_blockdev。这里我们需要重点关注上面参数中的硬盘,不过我们放在存储虚拟化那一节再解析。
configure_blockdev(&bdo_queue, machine_class, snapshot);
接下来初始化的是计算虚拟化的加速模式,也即要不要使用KVM。根据参数中的配置是启用KVM。这里调用的是configure_accelerator。
configure_accelerator(current_machine, argv[0]);
void configure_accelerator(MachineState *ms, const char *progname)
{
const char *accel;
char **accel_list, **tmp;
int ret;
bool accel_initialised = false;
bool init_failed = false;
AccelClass *acc = NULL;
accel = qemu_opt_get(qemu_get_machine_opts(), "accel");
accel = "kvm";
accel_list = g_strsplit(accel, ":", 0);
for (tmp = accel_list; !accel_initialised && tmp && *tmp; tmp++) {
acc = accel_find(*tmp);
ret = accel_init_machine(acc, ms);
}
}
static AccelClass *accel_find(const char *opt_name)
{
char *class_name = g_strdup_printf(ACCEL_CLASS_NAME("%s"), opt_name);
AccelClass *ac = ACCEL_CLASS(object_class_by_name(class_name));
g_free(class_name);
return ac;
}
static int accel_init_machine(AccelClass *acc, MachineState *ms)
{
ObjectClass *oc = OBJECT_CLASS(acc);
const char *cname = object_class_get_name(oc);
AccelState *accel = ACCEL(object_new(cname));
int ret;
ms->accelerator = accel;
*(acc->allowed) = true;
ret = acc->init_machine(ms);
return ret;
}
在configure_accelerator中,我们看命令行参数里面的accel,发现是kvm,则调用accel_find根据名字,得到相应的纸面上的class,并初始化为Class类。
MachineClass是计算机体系结构的Class类,同理,AccelClass就是加速器的Class类,然后调用accel_init_machine,通过object_new,将AccelClass这个Class类实例化为AccelState,类似对于体系结构的实例是MachineState。
在accel_find中,我们会根据名字kvm,找到纸面上的class,也即kvm_accel_type,然后调用type_initialize,里面调用kvm_accel_type的class_init方法,也即kvm_accel_class_init。
static void kvm_accel_class_init(ObjectClass *oc, void *data)
{
AccelClass *ac = ACCEL_CLASS(oc);
ac->name = "KVM";
ac->init_machine = kvm_init;
ac->allowed = &kvm_allowed;
}
在kvm_accel_class_init中,我们创建AccelClass,将init_machine设置为kvm_init。在accel_init_machine中其实就调用了这个init_machine函数,也即调用kvm_init方法。
static int kvm_init(MachineState *ms)
{
MachineClass *mc = MACHINE_GET_CLASS(ms);
int soft_vcpus_limit, hard_vcpus_limit;
KVMState *s;
const KVMCapabilityInfo *missing_cap;
int ret;
int type = 0;
const char *kvm_type;
s = KVM_STATE(ms->accelerator);
s->fd = qemu_open("/dev/kvm", O_RDWR);
ret = kvm_ioctl(s, KVM_GET_API_VERSION, 0);
......
do {
ret = kvm_ioctl(s, KVM_CREATE_VM, type);
} while (ret == -EINTR);
......
s->vmfd = ret;
/* check the vcpu limits */
soft_vcpus_limit = kvm_recommended_vcpus(s);
hard_vcpus_limit = kvm_max_vcpus(s);
......
ret = kvm_arch_init(ms, s);
if (ret < 0) {
goto err;
}
if (machine_kernel_irqchip_allowed(ms)) {
kvm_irqchip_create(ms, s);
}
......
return 0;
}
这里面的操作就从用户态到内核态的KVM了。就像前面原理讲过的一样,用户态使用内核态KVM的能力,需要打开一个文件/dev/kvm,这是一个字符设备文件,打开一个字符设备文件的过程我们讲过,这里不再赘述。
static struct miscdevice kvm_dev = {
KVM_MINOR,
"kvm",
&kvm_chardev_ops,
};
static struct file_operations kvm_chardev_ops = {
.unlocked_ioctl = kvm_dev_ioctl,
.compat_ioctl = kvm_dev_ioctl,
.llseek = noop_llseek,
};
KVM这个字符设备文件定义了一个字符设备文件的操作函数kvm_chardev_ops,这里面只定义了ioctl的操作。
接下来,用户态就通过ioctl系统调用,调用到kvm_dev_ioctl这个函数。这个过程我们在字符设备那一节也讲了。
static long kvm_dev_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
long r = -EINVAL;
switch (ioctl) {
case KVM_GET_API_VERSION:
r = KVM_API_VERSION;
break;
case KVM_CREATE_VM:
r = kvm_dev_ioctl_create_vm(arg);
break;
case KVM_CHECK_EXTENSION:
r = kvm_vm_ioctl_check_extension_generic(NULL, arg);
break;
case KVM_GET_VCPU_MMAP_SIZE:
r = PAGE_SIZE; /* struct kvm_run */
break;
......
}
out:
return r;
}
我们可以看到,在用户态qemu中,调用KVM_GET_API_VERSION查看版本号,内核就有相应的分支,返回版本号,如果能够匹配上,则调用KVM_CREATE_VM创建虚拟机。
创建虚拟机,需要调用kvm_dev_ioctl_create_vm。
static int kvm_dev_ioctl_create_vm(unsigned long type)
{
int r;
struct kvm *kvm;
struct file *file;
kvm = kvm_create_vm(type);
......
r = get_unused_fd_flags(O_CLOEXEC);
......
file = anon_inode_getfile("kvm-vm", &kvm_vm_fops, kvm, O_RDWR);
......
fd_install(r, file);
return r;
}
在kvm_dev_ioctl_create_vm中,首先调用kvm_create_vm创建一个struct kvm结构。这个结构在内核里面代表一个虚拟机。
从下面结构的定义里,我们可以看到,这里面有vcpu,有mm_struct结构。这个结构本来用来管理进程的内存的。虚拟机也是一个进程,所以虚拟机的用户进程空间也是用它来表示。虚拟机里面的操作系统以及应用的进程空间不归它管。
在kvm_dev_ioctl_create_vm中,第二件事情就是创建一个文件描述符,和struct file关联起来,这个struct file的file_operations会被设置为kvm_vm_fops。
struct kvm {
struct mm_struct *mm; /* userspace tied to this vm */
struct kvm_memslots __rcu *memslots[KVM_ADDRESS_SPACE_NUM];
struct kvm_vcpu *vcpus[KVM_MAX_VCPUS];
atomic_t online_vcpus;
int created_vcpus;
int last_boosted_vcpu;
struct list_head vm_list;
struct mutex lock;
struct kvm_io_bus __rcu *buses[KVM_NR_BUSES];
......
struct kvm_vm_stat stat;
struct kvm_arch arch;
refcount_t users_count;
......
long tlbs_dirty;
struct list_head devices;
pid_t userspace_pid;
};
static struct file_operations kvm_vm_fops = {
.release = kvm_vm_release,
.unlocked_ioctl = kvm_vm_ioctl,
.llseek = noop_llseek,
};
kvm_dev_ioctl_create_vm结束之后,对于一台虚拟机而言,只是在内核中有一个数据结构,对于相应的资源还没有分配,所以我们还需要接着看。
接下来,调用net_init_clients进行网络设备的初始化。我们可以解析net参数,也会在net_init_clients中解析netdev参数。这属于网络虚拟化的部分,我们先暂时放一下。
int net_init_clients(Error **errp)
{
QTAILQ_INIT(&net_clients);
if (qemu_opts_foreach(qemu_find_opts("netdev"),
net_init_netdev, NULL, errp)) {
return -1;
}
if (qemu_opts_foreach(qemu_find_opts("nic"), net_param_nic, NULL, errp)) {
return -1;
}
if (qemu_opts_foreach(qemu_find_opts("net"), net_init_client, NULL, errp)) {
return -1;
}
return 0;
}
接下来,我们要调用machine_run_board_init。这里面调用了MachineClass的init函数。盼啊盼才到了它,这才调用了pc_init1。
void machine_run_board_init(MachineState *machine)
{
MachineClass *machine_class = MACHINE_GET_CLASS(machine);
numa_complete_configuration(machine);
if (nb_numa_nodes) {
machine_numa_finish_cpu_init(machine);
}
......
machine_class->init(machine);
}
在pc_init1里面,我们重点关注两件重要的事情,一个的CPU的虚拟化,主要调用pc_cpus_init;另外就是内存的虚拟化,主要调用pc_memory_init。这一节我们重点关注CPU的虚拟化,下一节,我们来看内存的虚拟化。
void pc_cpus_init(PCMachineState *pcms)
{
......
for (i = 0; i < smp_cpus; i++) {
pc_new_cpu(possible_cpus->cpus[i].type, possible_cpus->cpus[i].arch_id, &error_fatal);
}
}
static void pc_new_cpu(const char *typename, int64_t apic_id, Error **errp)
{
Object *cpu = NULL;
cpu = object_new(typename);
object_property_set_uint(cpu, apic_id, "apic-id", &local_err);
object_property_set_bool(cpu, true, "realized", &local_err);//调用 object_property_add_bool的时候,设置了用 device_set_realized 来设置
......
}
在pc_cpus_init中,对于每一个CPU,都调用pc_new_cpu,在这里,我们又看到了object_new,这又是一个从TypeImpl到Class类再到对象的一个过程。
这个时候,我们就要看CPU的类是怎么组织的了。
在上面的参数里面,CPU的配置是这样的:
-cpu SandyBridge,+erms,+smep,+fsgsbase,+pdpe1gb,+rdrand,+f16c,+osxsave,+dca,+pcid,+pdcm,+xtpr,+tm2,+est,+smx,+vmx,+ds_cpl,+monitor,+dtes64,+pbe,+tm,+ht,+ss,+acpi,+ds,+vme
在这里我们知道,SandyBridge是CPU的一种类型。在hw/i386/pc.c中,我们能看到这种CPU的定义。
{ "SandyBridge" "-" TYPE_X86_CPU, "min-xlevel", "0x8000000a" }
接下来,我们就来看"SandyBridge",也即TYPE_X86_CPU这种CPU的类,是一个什么样的结构。
static const TypeInfo device_type_info = {
.name = TYPE_DEVICE,
.parent = TYPE_OBJECT,
.instance_size = sizeof(DeviceState),
.instance_init = device_initfn,
.instance_post_init = device_post_init,
.instance_finalize = device_finalize,
.class_base_init = device_class_base_init,
.class_init = device_class_init,
.abstract = true,
.class_size = sizeof(DeviceClass),
};
static const TypeInfo cpu_type_info = {
.name = TYPE_CPU,
.parent = TYPE_DEVICE,
.instance_size = sizeof(CPUState),
.instance_init = cpu_common_initfn,
.instance_finalize = cpu_common_finalize,
.abstract = true,
.class_size = sizeof(CPUClass),
.class_init = cpu_class_init,
};
static const TypeInfo x86_cpu_type_info = {
.name = TYPE_X86_CPU,
.parent = TYPE_CPU,
.instance_size = sizeof(X86CPU),
.instance_init = x86_cpu_initfn,
.abstract = true,
.class_size = sizeof(X86CPUClass),
.class_init = x86_cpu_common_class_init,
};
CPU这种类的定义是有多层继承关系的。TYPE_X86_CPU的父类是TYPE_CPU,TYPE_CPU的父类是TYPE_DEVICE,TYPE_DEVICE的父类是TYPE_OBJECT。到头了。
这里面每一层都有class_init,用于从TypeImpl生产xxxClass,也有instance_init将xxxClass初始化为实例。
在TYPE_X86_CPU这一层的class_init中,也即x86_cpu_common_class_init中,设置了DeviceClass的realize函数为x86_cpu_realizefn。这个函数很重要,马上就能用到。
static void x86_cpu_common_class_init(ObjectClass *oc, void *data)
{
X86CPUClass *xcc = X86_CPU_CLASS(oc);
CPUClass *cc = CPU_CLASS(oc);
DeviceClass *dc = DEVICE_CLASS(oc);
device_class_set_parent_realize(dc, x86_cpu_realizefn,
&xcc->parent_realize);
......
}
在TYPE_DEVICE这一层的instance_init函数device_initfn,会为这个设备添加一个属性"realized",要设置这个属性,需要用函数device_set_realized。
static void device_initfn(Object *obj)
{
DeviceState *dev = DEVICE(obj);
ObjectClass *class;
Property *prop;
dev->realized = false;
object_property_add_bool(obj, "realized",
device_get_realized, device_set_realized, NULL);
......
}
我们回到pc_new_cpu函数,这里面就是通过object_property_set_bool设置这个属性为true,所以device_set_realized函数会被调用。
在device_set_realized中,DeviceClass的realize函数x86_cpu_realizefn会被调用。这里面qemu_init_vcpu会调用qemu_kvm_start_vcpu。
static void qemu_kvm_start_vcpu(CPUState *cpu)
{
char thread_name[VCPU_THREAD_NAME_SIZE];
cpu->thread = g_malloc0(sizeof(QemuThread));
cpu->halt_cond = g_malloc0(sizeof(QemuCond));
qemu_cond_init(cpu->halt_cond);
qemu_thread_create(cpu->thread, thread_name, qemu_kvm_cpu_thread_fn, cpu, QEMU_THREAD_JOINABLE);
}
在这里面,为这个vcpu创建一个线程,也即虚拟机里面的一个vcpu对应物理机上的一个线程,然后这个线程被调度到某个物理CPU上。
我们来看这个vcpu的线程执行函数。
static void *qemu_kvm_cpu_thread_fn(void *arg)
{
CPUState *cpu = arg;
int r;
rcu_register_thread();
qemu_mutex_lock_iothread();
qemu_thread_get_self(cpu->thread);
cpu->thread_id = qemu_get_thread_id();
cpu->can_do_io = 1;
current_cpu = cpu;
r = kvm_init_vcpu(cpu);
kvm_init_cpu_signals(cpu);
/* signal CPU creation */
cpu->created = true;
qemu_cond_signal(&qemu_cpu_cond);
do {
if (cpu_can_run(cpu)) {
r = kvm_cpu_exec(cpu);
}
qemu_wait_io_event(cpu);
} while (!cpu->unplug || cpu_can_run(cpu));
qemu_kvm_destroy_vcpu(cpu);
cpu->created = false;
qemu_cond_signal(&qemu_cpu_cond);
qemu_mutex_unlock_iothread();
rcu_unregister_thread();
return NULL;
}
在qemu_kvm_cpu_thread_fn中,先是kvm_init_vcpu初始化这个vcpu。
int kvm_init_vcpu(CPUState *cpu)
{
KVMState *s = kvm_state;
long mmap_size;
int ret;
......
ret = kvm_get_vcpu(s, kvm_arch_vcpu_id(cpu));
......
cpu->kvm_fd = ret;
cpu->kvm_state = s;
cpu->vcpu_dirty = true;
mmap_size = kvm_ioctl(s, KVM_GET_VCPU_MMAP_SIZE, 0);
......
cpu->kvm_run = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED, cpu->kvm_fd, 0);
......
ret = kvm_arch_init_vcpu(cpu);
err:
return ret;
}
在kvm_get_vcpu中,我们会调用kvm_vm_ioctl(s, KVM_CREATE_VCPU, (void *)vcpu_id),在内核里面创建一个vcpu。在上面创建KVM_CREATE_VM的时候,我们已经创建了一个struct file,它的file_operations被设置为kvm_vm_fops,这个内核文件也是可以响应ioctl的。
如果我们切换到内核KVM,在kvm_vm_ioctl函数中,有对于KVM_CREATE_VCPU的处理,调用的是kvm_vm_ioctl_create_vcpu。
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
void __user *argp = (void __user *)arg;
int r;
switch (ioctl) {
case KVM_CREATE_VCPU:
r = kvm_vm_ioctl_create_vcpu(kvm, arg);
break;
case KVM_SET_USER_MEMORY_REGION: {
struct kvm_userspace_memory_region kvm_userspace_mem;
if (copy_from_user(&kvm_userspace_mem, argp,
sizeof(kvm_userspace_mem)))
goto out;
r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem);
break;
}
......
case KVM_CREATE_DEVICE: {
struct kvm_create_device cd;
if (copy_from_user(&cd, argp, sizeof(cd)))
goto out;
r = kvm_ioctl_create_device(kvm, &cd);
if (copy_to_user(argp, &cd, sizeof(cd)))
goto out;
break;
}
case KVM_CHECK_EXTENSION:
r = kvm_vm_ioctl_check_extension_generic(kvm, arg);
break;
default:
r = kvm_arch_vm_ioctl(filp, ioctl, arg);
}
out:
return r;
}
在kvm_vm_ioctl_create_vcpu中,kvm_arch_vcpu_create调用kvm_x86_ops的vcpu_create函数来创建CPU。
static int kvm_vm_ioctl_create_vcpu(struct kvm *kvm, u32 id)
{
int r;
struct kvm_vcpu *vcpu;
kvm->created_vcpus++;
......
vcpu = kvm_arch_vcpu_create(kvm, id);
preempt_notifier_init(&vcpu->preempt_notifier, &kvm_preempt_ops);
r = kvm_arch_vcpu_setup(vcpu);
......
/* Now it's all set up, let userspace reach it */
kvm_get_kvm(kvm);
r = create_vcpu_fd(vcpu);
kvm->vcpus[atomic_read(&kvm->online_vcpus)] = vcpu;
......
}
struct kvm_vcpu *kvm_arch_vcpu_create(struct kvm *kvm,
unsigned int id)
{
struct kvm_vcpu *vcpu;
vcpu = kvm_x86_ops->vcpu_create(kvm, id);
return vcpu;
}
static int create_vcpu_fd(struct kvm_vcpu *vcpu)
{
return anon_inode_getfd("kvm-vcpu", &kvm_vcpu_fops, vcpu, O_RDWR | O_CLOEXEC);
}
然后,create_vcpu_fd又创建了一个struct file,它的file_operations指向kvm_vcpu_fops。从这里可以看出,KVM的内核模块是一个文件,可以通过ioctl进行操作。基于这个内核模块创建的VM也是一个文件,也可以通过ioctl进行操作。在这个VM上创建的vcpu同样是一个文件,同样可以通过ioctl进行操作。
我们回过头来看,kvm_x86_ops的vcpu_create函数。kvm_x86_ops对于不同的硬件加速虚拟化指向不同的结构,如果是vmx,则指向vmx_x86_ops;如果是svm,则指向svm_x86_ops。我们这里看vmx_x86_ops。这个结构很长,里面有非常多的操作,我们用一个看一个。
static struct kvm_x86_ops vmx_x86_ops __ro_after_init = {
......
.vcpu_create = vmx_create_vcpu,
......
}
static struct kvm_vcpu *vmx_create_vcpu(struct kvm *kvm, unsigned int id)
{
int err;
struct vcpu_vmx *vmx = kmem_cache_zalloc(kvm_vcpu_cache, GFP_KERNEL);
int cpu;
vmx->vpid = allocate_vpid();
err = kvm_vcpu_init(&vmx->vcpu, kvm, id);
vmx->guest_msrs = kmalloc(PAGE_SIZE, GFP_KERNEL);
vmx->loaded_vmcs = &vmx->vmcs01;
vmx->loaded_vmcs->vmcs = alloc_vmcs();
vmx->loaded_vmcs->shadow_vmcs = NULL;
loaded_vmcs_init(vmx->loaded_vmcs);
cpu = get_cpu();
vmx_vcpu_load(&vmx->vcpu, cpu);
vmx->vcpu.cpu = cpu;
err = vmx_vcpu_setup(vmx);
vmx_vcpu_put(&vmx->vcpu);
put_cpu();
if (enable_ept) {
if (!kvm->arch.ept_identity_map_addr)
kvm->arch.ept_identity_map_addr =
VMX_EPT_IDENTITY_PAGETABLE_ADDR;
err = init_rmode_identity_map(kvm);
}
return &vmx->vcpu;
}
vmx_create_vcpu创建用于表示vcpu的结构struct vcpu_vmx,并填写里面的内容。例如guest_msrs,咱们在讲系统调用的时候提过msr寄存器,虚拟机也需要有这样的寄存器。
enable_ept是和内存虚拟化相关的,EPT全称Extended Page Table,顾名思义,是优化内存虚拟化的,这个功能我们放到内存的那一节讲。
最最重要的就是loaded_vmcs了。VMCS是什么呢?它的全称是Virtual Machine Control Structure。它是来干什么呢?
前面咱们讲进程调度的时候讲过,为了支持进程在CPU上的切换,CPU硬件要求有一个TSS结构,用于保存进程运行时的所有寄存器的状态,进程切换的时候,需要根据TSS恢复寄存器。
虚拟机也是一个进程,也需要切换,而且切换更加的复杂,可能是两个虚拟机之间切换,也可能是虚拟机切换给内核,虚拟机因为里面还有另一个操作系统,要保存的信息比普通的进程多得多。那就需要有一个结构来保存虚拟机运行的上下文,VMCS就是是Intel实现CPU虚拟化,记录vCPU状态的一个关键数据结构。
VMCS数据结构主要包含以下信息。
接下来,对于VMCS,有两个重要的操作。
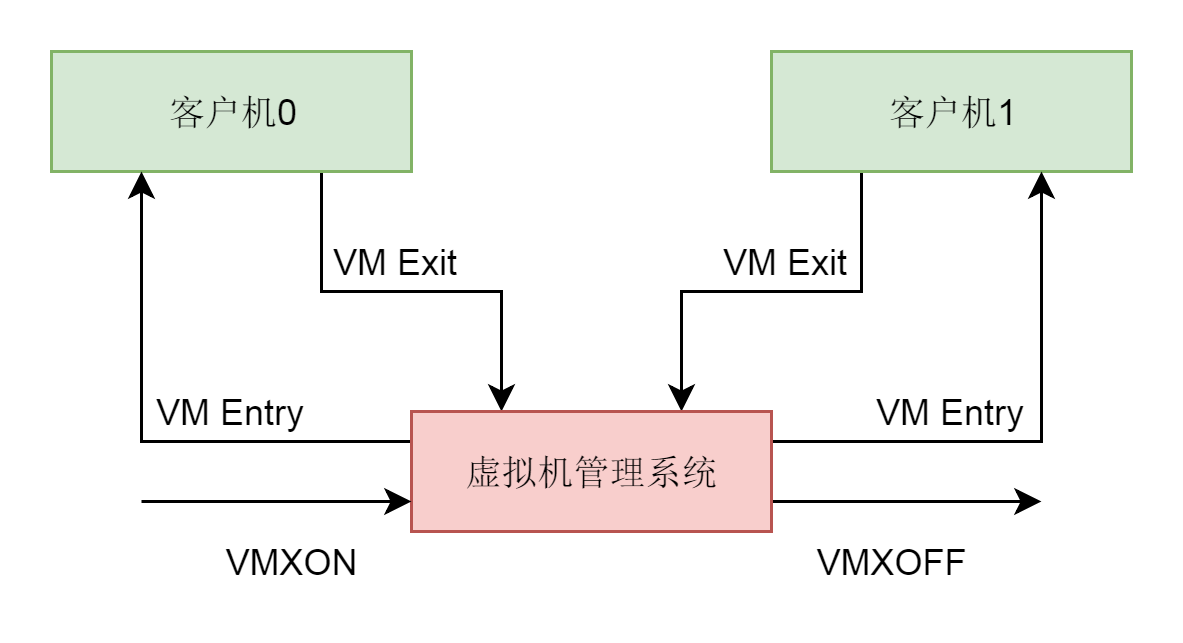
VM-Entry,我们称为从根模式切换到非根模式,也即切换到guest上,这个时候CPU上运行的是虚拟机。VM-Exit我们称为CPU从非根模式切换到根模式,也即从guest切换到宿主机。例如,当要执行一些虚拟机没有权限的敏感指令时。
为了维护这两个动作,VMCS里面还有几项内容:
至此,内核准备完毕。
我们再回到qemu的kvm_init_vcpu函数,这里面除了创建内核中的vcpu结构之外,还通过mmap将内核的vcpu结构,映射到qemu中CPUState的kvm_run中,为什么能用mmap呢,上面咱们不是说过了吗,vcpu也是一个文件。
我们再回到这个vcpu的线程函数qemu_kvm_cpu_thread_fn,他在执行kvm_init_vcpu创建vcpu之后,接下来是一个do-while循环,也即一直运行,并且通过调用kvm_cpu_exec,运行这个虚拟机。
int kvm_cpu_exec(CPUState *cpu)
{
struct kvm_run *run = cpu->kvm_run;
int ret, run_ret;
......
do {
......
run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0);
......
switch (run->exit_reason) {
case KVM_EXIT_IO:
kvm_handle_io(run->io.port, attrs,
(uint8_t *)run + run->io.data_offset,
run->io.direction,
run->io.size,
run->io.count);
break;
case KVM_EXIT_IRQ_WINDOW_OPEN:
ret = EXCP_INTERRUPT;
break;
case KVM_EXIT_SHUTDOWN:
qemu_system_reset_request(SHUTDOWN_CAUSE_GUEST_RESET);
ret = EXCP_INTERRUPT;
break;
case KVM_EXIT_UNKNOWN:
fprintf(stderr, "KVM: unknown exit, hardware reason %" PRIx64 "\n",(uint64_t)run->hw.hardware_exit_reason);
ret = -1;
break;
case KVM_EXIT_INTERNAL_ERROR:
ret = kvm_handle_internal_error(cpu, run);
break;
......
}
} while (ret == 0);
......
return ret;
}
在kvm_cpu_exec中,我们能看到一个循环,在循环中,kvm_vcpu_ioctl(KVM_RUN)运行这个虚拟机,这个时候CPU进入VM-Entry,也即进入客户机模式。
如果一直是客户机的操作系统占用这个CPU,则会一直停留在这一行运行,一旦这个调用返回了,就说明CPU进入VM-Exit退出客户机模式,将CPU交还给宿主机。在循环中,我们会对退出的原因exit_reason进行分析处理,因为有了I/O,还有了中断等,做相应的处理。处理完毕之后,再次循环,再次通过VM-Entry,进入客户机模式。如此循环,直到虚拟机正常或者异常退出。
我们来看kvm_vcpu_ioctl(KVM_RUN)在内核做了哪些事情。
上面我们也讲了,vcpu在内核也是一个文件,也是通过ioctl进行用户态和内核态通信的,在内核中,调用的是kvm_vcpu_ioctl。
static long kvm_vcpu_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm_vcpu *vcpu = filp->private_data;
void __user *argp = (void __user *)arg;
int r;
struct kvm_fpu *fpu = NULL;
struct kvm_sregs *kvm_sregs = NULL;
......
r = vcpu_load(vcpu);
switch (ioctl) {
case KVM_RUN: {
struct pid *oldpid;
r = kvm_arch_vcpu_ioctl_run(vcpu, vcpu->run);
break;
}
case KVM_GET_REGS: {
struct kvm_regs *kvm_regs;
kvm_regs = kzalloc(sizeof(struct kvm_regs), GFP_KERNEL);
r = kvm_arch_vcpu_ioctl_get_regs(vcpu, kvm_regs);
if (copy_to_user(argp, kvm_regs, sizeof(struct kvm_regs)))
goto out_free1;
break;
}
case KVM_SET_REGS: {
struct kvm_regs *kvm_regs;
kvm_regs = memdup_user(argp, sizeof(*kvm_regs));
r = kvm_arch_vcpu_ioctl_set_regs(vcpu, kvm_regs);
break;
}
......
}
kvm_arch_vcpu_ioctl_run会调用vcpu_run,这里面也是一个无限循环。
static int vcpu_run(struct kvm_vcpu *vcpu)
{
int r;
struct kvm *kvm = vcpu->kvm;
for (;;) {
if (kvm_vcpu_running(vcpu)) {
r = vcpu_enter_guest(vcpu);
} else {
r = vcpu_block(kvm, vcpu);
}
....
if (signal_pending(current)) {
r = -EINTR;
vcpu->run->exit_reason = KVM_EXIT_INTR;
++vcpu->stat.signal_exits;
break;
}
if (need_resched()) {
cond_resched();
}
}
......
return r;
}
在这个循环中,除了调用vcpu_enter_guest进入客户机模式运行之外,还有对于信号的响应signal_pending,也即一台虚拟机是可以被kill掉的,还有对于调度的响应,这台虚拟机可以被从当前的物理CPU上赶下来,换成别的虚拟机或者其他进程。
我们这里重点看vcpu_enter_guest。
static int vcpu_enter_guest(struct kvm_vcpu *vcpu)
{
r = kvm_mmu_reload(vcpu);
vcpu->mode = IN_GUEST_MODE;
kvm_load_guest_xcr0(vcpu);
......
guest_enter_irqoff();
kvm_x86_ops->run(vcpu);
vcpu->mode = OUTSIDE_GUEST_MODE;
......
kvm_put_guest_xcr0(vcpu);
kvm_x86_ops->handle_external_intr(vcpu);
++vcpu->stat.exits;
guest_exit_irqoff();
r = kvm_x86_ops->handle_exit(vcpu);
return r;
......
}
static struct kvm_x86_ops vmx_x86_ops __ro_after_init = {
......
.run = vmx_vcpu_run,
......
}
在vcpu_enter_guest中,我们会调用vmx_x86_ops 的vmx_vcpu_run函数,进入客户机模式。
static void __noclone vmx_vcpu_run(struct kvm_vcpu *vcpu)
{
struct vcpu_vmx *vmx = to_vmx(vcpu);
unsigned long debugctlmsr, cr3, cr4;
......
cr3 = __get_current_cr3_fast();
......
cr4 = cr4_read_shadow();
......
vmx->__launched = vmx->loaded_vmcs->launched;
asm(
/* Store host registers */
"push %%" _ASM_DX "; push %%" _ASM_BP ";"
"push %%" _ASM_CX " \n\t" /* placeholder for guest rcx */
"push %%" _ASM_CX " \n\t"
......
/* Load guest registers. Don't clobber flags. */
"mov %c[rax](%0), %%" _ASM_AX " \n\t"
"mov %c[rbx](%0), %%" _ASM_BX " \n\t"
"mov %c[rdx](%0), %%" _ASM_DX " \n\t"
"mov %c[rsi](%0), %%" _ASM_SI " \n\t"
"mov %c[rdi](%0), %%" _ASM_DI " \n\t"
"mov %c[rbp](%0), %%" _ASM_BP " \n\t"
#ifdef CONFIG_X86_64
"mov %c[r8](%0), %%r8 \n\t"
"mov %c[r9](%0), %%r9 \n\t"
"mov %c[r10](%0), %%r10 \n\t"
"mov %c[r11](%0), %%r11 \n\t"
"mov %c[r12](%0), %%r12 \n\t"
"mov %c[r13](%0), %%r13 \n\t"
"mov %c[r14](%0), %%r14 \n\t"
"mov %c[r15](%0), %%r15 \n\t"
#endif
"mov %c[rcx](%0), %%" _ASM_CX " \n\t" /* kills %0 (ecx) */
/* Enter guest mode */
"jne 1f \n\t"
__ex(ASM_VMX_VMLAUNCH) "\n\t"
"jmp 2f \n\t"
"1: " __ex(ASM_VMX_VMRESUME) "\n\t"
"2: "
/* Save guest registers, load host registers, keep flags */
"mov %0, %c[wordsize](%%" _ASM_SP ") \n\t"
"pop %0 \n\t"
"mov %%" _ASM_AX ", %c[rax](%0) \n\t"
"mov %%" _ASM_BX ", %c[rbx](%0) \n\t"
__ASM_SIZE(pop) " %c[rcx](%0) \n\t"
"mov %%" _ASM_DX ", %c[rdx](%0) \n\t"
"mov %%" _ASM_SI ", %c[rsi](%0) \n\t"
"mov %%" _ASM_DI ", %c[rdi](%0) \n\t"
"mov %%" _ASM_BP ", %c[rbp](%0) \n\t"
#ifdef CONFIG_X86_64
"mov %%r8, %c[r8](%0) \n\t"
"mov %%r9, %c[r9](%0) \n\t"
"mov %%r10, %c[r10](%0) \n\t"
"mov %%r11, %c[r11](%0) \n\t"
"mov %%r12, %c[r12](%0) \n\t"
"mov %%r13, %c[r13](%0) \n\t"
"mov %%r14, %c[r14](%0) \n\t"
"mov %%r15, %c[r15](%0) \n\t"
#endif
"mov %%cr2, %%" _ASM_AX " \n\t"
"mov %%" _ASM_AX ", %c[cr2](%0) \n\t"
"pop %%" _ASM_BP "; pop %%" _ASM_DX " \n\t"
"setbe %c[fail](%0) \n\t"
".pushsection .rodata \n\t"
".global vmx_return \n\t"
"vmx_return: " _ASM_PTR " 2b \n\t"
......
);
......
vmx->loaded_vmcs->launched = 1;
vmx->exit_reason = vmcs_read32(VM_EXIT_REASON);
......
}
在vmx_vcpu_run中,出现了汇编语言的代码,比较难看懂,但是没有关系呀,里面有注释呀,我们可以沿着注释来看。
至此,CPU虚拟化就解析完了。
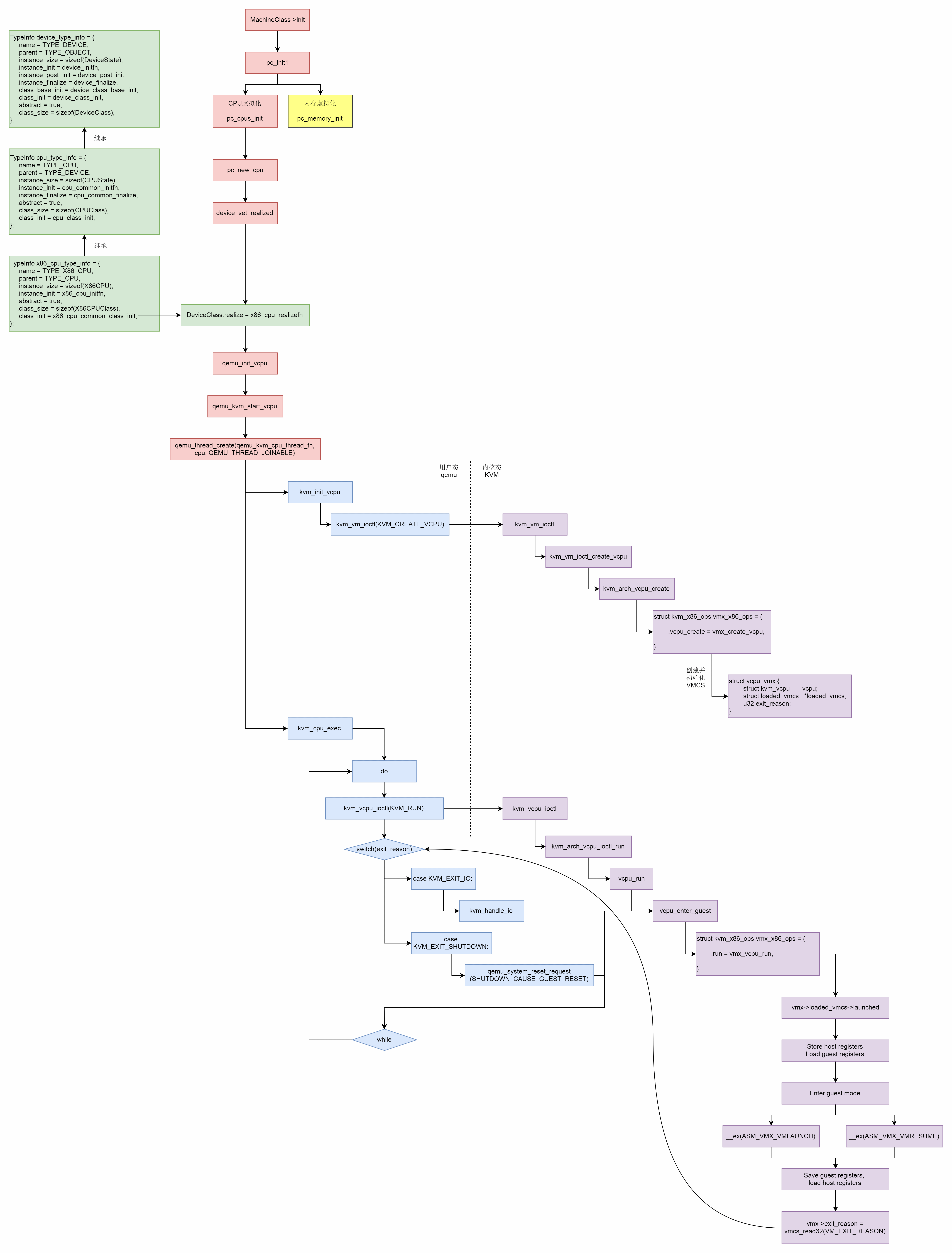
CPU的虚拟化过程还是很复杂的,我画了一张图总结了一下。
在咱们上面操作KVM的过程中,出现了好几次文件系统。不愧是“Linux中一切皆文件”。那你能否整理一下这些文件系统之间的关系呢?
欢迎留言和我分享你的疑惑和见解,也欢迎收藏本节内容,反复研读。你也可以把今天的内容分享给你的朋友,和他一起学习和进步。

评论