在前面的几篇文章中,我介绍了GUI自动化测试的数据驱动测试、页面对象(Page Object)模型、业务流程封装,以及测试数据相关的内容。
今天这篇文章,我将从页面对象自动生成、GUI测试数据自动生成、无头浏览器三个方面展开,这也是GUI测试中三个比较有意思的知识点。
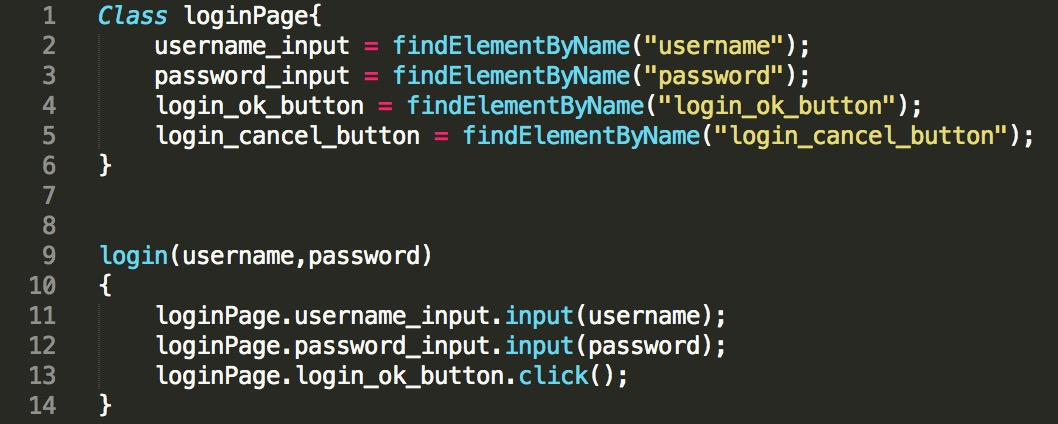
在前面的文章中,我已经介绍过页面对象(Page Object)模型的概念。页面对象模型,是以Web页面为单位来封装页面上的控件以及控件的部分操作,而测试用例基于页面对象完成具体操作。最典型的模式就是:XXXPage.YYYComponent.ZZZOperation。
基于页面对象模型的伪代码示例,如图1所示。
如果你在实际项目中已经用过页面对象模型,你会发现开发和维护页面对象的类(Page Class),是一件很耗费时间和体力的事儿。
那么,什么方法能够解决这个问题呢?答案就是,页面对象自动生成技术,它非常适用于需要维护大量页面对象的中大型GUI自动化测试项目。
页面对象自动生成技术,属于典型的“自动化你的自动化”的应用场景。它的基本思路是,你不用再手工维护Page Class了,只需要提供Web的URL,它就会自动帮你生成这个页面上所有控件的定位信息,并自动生成Page Class。
但是,需要注意的是,那些依赖于数据的动态页面对象也会被包含在自动生成的Page Class里,而这种动态页面对象通常不应该包含在Page Class里,所以,往往需要以手工的方式删除。
目前,很多商用自动化工具,比如UFT,已经支持页面对象自动生成功能了,同时还能够对Page Class进行版本管理。
但是,开源的自动化方案,页面对象自动生成功能一般需要自己开发,并且需要与你所用的自动化测试框架深度绑定。目前,中小企业很少有自己去实现这一功能的。
不过,有个好消息是,目前国内应用还不算多、免费的Katalon Studio,已经提供了类似的页面对象库管理功能,如果感兴趣的话,你可以去试用一下。
GUI测试数据自动生成,指的由机器自动生成测试用例的输入数据。
乍一听上去是不是感觉有点玄乎?机器不可能理解你的业务逻辑,怎么可能自动生成测试数据呢?
你的这个想法完全合理,并且也是完全正确的。所以,我在这里说的“测试数据自动生成”,仅仅局限于以下两种情况:
根据GUI输入数据类型,以及对应的自定义规则库自动生成测试输入数据。 比如,GUI界面上有一个“书名”输入框,它的数据类型是string。
那么,基于数据类型就可以自动生成诸如 Null、SQL注入、超长字符串、非英语字符等测试数据。
同时,根据自定义规则库,还可以根据具体规则生成各种测试数据。这个自定义规则库里面的规则,往往反映了具体的业务逻辑。比如,对于“书名”,就会有书名不能大于多少个字符、一些典型的书名(比如,英文书名、中文书名等)等等业务方面的要求,那么就可以根据这些业务要求来生成测试数据。
根据自定义规则生成测试数据的核心思想,与安全扫描软件AppScan基于攻击规则库自动生成和执行安全测试的方式,有异曲同工之处。
对于需要组合多个测试输入数据的场景,测试数据自动生成可以自动完成多个测试数据的笛卡尔积组合,然后再以人工的方式剔除掉非法的数据组合。
但是,这种方式并不一定是最高效的。对于输入参数比较多,且数据之间合法组合比较少或者难以明确的情况,先自动化生成笛卡尔积组合,再删除非法组合,效率往往还不如人为组合来得高。所以,在这个场景下是否要用测试数据自动生成方法,还需要具体问题具体分析。
更常见的用法是,先手动选择部分输入数据进行笛卡尔积,并删除不合法的部分;然后,在此基础上,再人为添加更多业务上有意义的输入数据组合。
比如,输入数据有A、B、C、D、E、F六个参数,你可以先选取最典型的几个参数生成笛卡尔积,假设这里选取A、B和C;然后,在生成的笛卡尔积中删除业务上不合法的组合;最后,再结合D、E和F的一些典型取值,构成更多的测试输入数据组合。
无头浏览器,即Headless Browser,是一种没有界面的浏览器。
什么?浏览器没有界面,还叫什么浏览器啊?别急,我将为你一一道来。
无头浏览器,其实是一个特殊的浏览器,你可以把它简单地想象成是运行在内存中的浏览器。它拥有完整的浏览器内核,包括JavaScript解析引擎、渲染引擎等。
与普通浏览器最大的不同是,无头浏览器执行过程中看不到运行的界面,但是你依然可以用GUI测试框架的截图功能截取它执行中的页面。
无头浏览器的主要应用场景,包括GUI自动化测试、页面监控以及网络爬虫这三种。在GUI测试过程中,使用无头浏览器的好处主要体现在四个方面:
测试执行速度更快。 相对于普通浏览器来说,无头浏览器无需加载CSS以及渲染页面,在测试用例的执行速度上有很大的优势。
减少对测试执行的干扰。 可以减少操作系统以及其他软件(比如杀毒软件等)不可预期的弹出框,对浏览器测试的干扰。
简化测试执行环境的搭建。 对于大量测试用例的执行而言,可以减少对大规模Selenium Grid集群的依赖,GUI测试可以直接运行在无界面的服务器上。
在单机环境实现测试的并发执行。 可以在单机上很方便地运行多个无头浏览器,实现测试用例的并发执行。
但是,无头浏览器并不完美,它最大的缺点是,不能完全模拟真实的用户行为,而且由于没有实际完成页面的渲染,所以不太适用于需要对于页面布局进行验证的场景。同时,业界也一直缺乏理想的无头浏览器方案。
在Google发布Headless Chrome之前,PhantomJS是业界主流的无头浏览器解决方案。但是,这个项目的维护一直以来做得都不够好,已知未解决的缺陷数量多达1800多个,虽然支持主流的Webkit浏览器内核,但是依赖的Chrome版本太低。所以,无头浏览器一直难以在GUI自动化测试中大规模应用。
但好消息是,2017年Google发布了Headless Chrome,以及与之配套的Puppeteer框架,Puppeteer不仅支持最新版本的Chrome,而且得到Google官方的支持,这使得无头浏览器可以在实际项目中得到更好的应用。
也正是这个原因,PhantomJS的创建者Ariya Hidayat停止了它的后续维护,Headless Chrome成了无头浏览器的首选方案。
那什么是Puppeteer呢?Puppeteer是一个Node库,提供了高级别的API封装,这些API会通过Chrome DevTools Protocol与Headless Chrome的交互达到自动化操作的目的。
Puppeteer也是由Google开发的,所以它可以很好地支持Headless Chrome以及后续Chrome的版本更新。
如果你也迫不及待地想要尝试把Headless Chrome应用到自己的GUI测试中,那还等什么,赶紧下载并开始吧。
我分别介绍了无头浏览器、页面对象自动生成,以及GUI测试数据自动生成,这三个GUI测试中比较有意思的知识点,包括它们的概念、应用场景等内容。
对于页面对象自动生成,商用测试软件已经实现了这个功能。但是,如果你选择开源测试框架,就需要自己实现这个功能了。
GUI测试数据自动生成,主要是基于测试输入数据的类型以及对应的自定义规则库实现的,并且对于多个测试输入数据,可以基于笛卡尔积来自动组合出完整的测试用例集合。
对于无头浏览器,你可以把它简单地想象成运行在内存中的浏览器,它拥有完整的浏览器内核。与普通浏览器最大的不同是,它在执行过程中看不到运行的界面。目前,Headless Chrome结合Puppeteer是最先进的无头浏览器方案,如果感兴趣,你可以下载试用。
在你的工作中,还有哪些好的方法和实践可以提高GUI自动化测试的效率吗?
欢迎你给我留言。