
经过前面几大模块的学习,你已经完全掌握了HTTP的所有知识,那么接下来请收拾一下行囊,整理一下装备,跟我一起去探索HTTP之外的广阔天地。
现在的互联网非常发达,用户越来越多,网速越来越快,HTTPS的安全加密、HTTP/2的多路复用等特性都对Web服务器提出了非常高的要求。一个好的Web服务器必须要具备稳定、快速、易扩展、易维护等特性,才能够让网站“立于不败之地”。
那么,在搭建网站的时候,应该选择什么样的服务器软件呢?
在开头的几讲里我也提到过,Web服务器就那么几款,目前市面上主流的只有两个:Apache和Nginx,两者合计占据了近90%的市场份额。
今天我要说的就是其中的Nginx,它是Web服务器的“后起之秀”,虽然比Apache小了10岁,但增长速度十分迅猛,已经达到了与Apache“平起平坐”的地位,而在“Top Million”网站中更是超过了Apache,拥有超过50%的用户(参考数据)。
在这里必须要说一下Nginx的正确发音,它应该读成“Engine X”,但我个人感觉“X”念起来太“拗口”,还是比较倾向于读做“Engine ks”,这也与UNIX、Linux的发音一致。
作为一个Web服务器,Nginx的功能非常完善,完美支持HTTP/1、HTTPS和HTTP/2,而且还在不断进步。当前的主线版本已经发展到了1.17,正在进行HTTP/3的研发,或许一年之后就能在Nginx上跑HTTP/3了。
Nginx也是我个人的主要研究领域,我也写过相关的书,按理来说今天的课程应该是“手拿把攥”,但真正动笔的时候还是有些犹豫的:很多要点都已经在书里写过了,这次的专栏如果再重复相同的内容就不免有“骗稿费”的嫌疑,应该有些“不一样的东西”。
所以我决定抛开书本,换个角度,结合HTTP协议来讲Nginx,带你窥视一下HTTP处理的内幕,看看Web服务器的工作原理。
你也许听说过,Nginx是个“轻量级”的Web服务器,那么这个所谓的“轻量级”是什么意思呢?
“轻量级”是相对于“重量级”而言的。“重量级”就是指服务器进程很“重”,占用很多资源,当处理HTTP请求时会消耗大量的CPU和内存,受到这些资源的限制很难提高性能。
而Nginx作为“轻量级”的服务器,它的CPU、内存占用都非常少,同样的资源配置下就能够为更多的用户提供服务,其奥秘在于它独特的工作模式。
在Nginx之前,Web服务器的工作模式大多是“Per-Process”或者“Per-Thread”,对每一个请求使用单独的进程或者线程处理。这就存在创建进程或线程的成本,还会有进程、线程“上下文切换”的额外开销。如果请求数量很多,CPU就会在多个进程、线程之间切换时“疲于奔命”,平白地浪费了计算时间。
Nginx则完全不同,“一反惯例”地没有使用多线程,而是使用了“进程池+单线程”的工作模式。
Nginx在启动的时候会预先创建好固定数量的worker进程,在之后的运行过程中不会再fork出新进程,这就是进程池,而且可以自动把进程“绑定”到独立的CPU上,这样就完全消除了进程创建和切换的成本,能够充分利用多核CPU的计算能力。
在进程池之上,还有一个“master”进程,专门用来管理进程池。它的作用有点像是supervisor(一个用Python编写的进程管理工具),用来监控进程,自动恢复发生异常的worker,保持进程池的稳定和服务能力。
不过master进程完全是Nginx自行用C语言实现的,这就摆脱了外部的依赖,简化了Nginx的部署和配置。
如果你用Java、C等语言写过程序,一定很熟悉“多线程”的概念,使用多线程能够很容易实现并发处理。
但多线程也有一些缺点,除了刚才说到的“上下文切换”成本,还有编程模型复杂、数据竞争、同步等问题,写出正确、快速的多线程程序并不是一件容易的事情。
所以Nginx就选择了单线程的方式,带来的好处就是开发简单,没有互斥锁的成本,减少系统消耗。
那么,疑问也就产生了:为什么单线程的Nginx,处理能力却能够超越其他多线程的服务器呢?
这要归功于Nginx利用了Linux内核里的一件“神兵利器”,I/O多路复用接口,“大名鼎鼎”的epoll。
“多路复用”这个词我们已经在之前的HTTP/2、HTTP/3里遇到过好几次,如果你理解了那里的“多路复用”,那么面对Nginx的epoll“多路复用”也就好办了。
Web服务器从根本上来说是“I/O密集型”而不是“CPU密集型”,处理能力的关键在于网络收发而不是CPU计算(这里暂时不考虑HTTPS的加解密),而网络I/O会因为各式各样的原因不得不等待,比如数据还没到达、对端没有响应、缓冲区满发不出去等等。
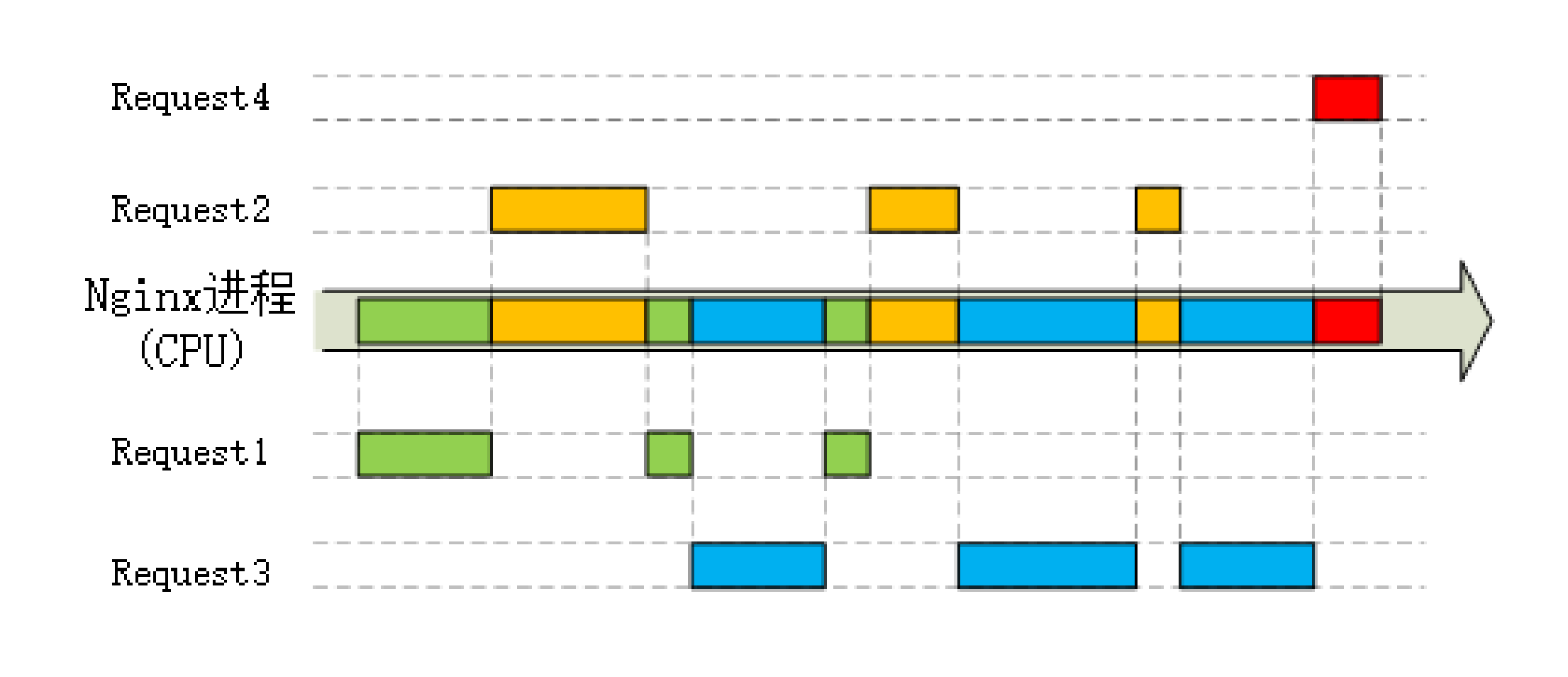
这种情形就有点像是HTTP里的“队头阻塞”。对于一般的单线程来说CPU就会“停下来”,造成浪费。而多线程的解决思路有点类似“并发连接”,虽然有的线程可能阻塞,但由于多个线程并行,总体上看阻塞的情况就不会太严重了。
Nginx里使用的epoll,就好像是HTTP/2里的“多路复用”技术,它把多个HTTP请求处理打散成碎片,都“复用”到一个单线程里,不按照先来后到的顺序处理,而是只当连接上真正可读、可写的时候才处理,如果可能发生阻塞就立刻切换出去,处理其他的请求。
通过这种方式,Nginx就完全消除了I/O阻塞,把CPU利用得“满满当当”,又因为网络收发并不会消耗太多CPU计算能力,也不需要切换进程、线程,所以整体的CPU负载是相当低的。
这里我画了一张Nginx“I/O多路复用”的示意图,你可以看到,它的形式与HTTP/2的流非常相似,每个请求处理单独来看是分散、阻塞的,但因为都复用到了一个线程里,所以资源的利用率非常高。
epoll还有一个特点,大量的连接管理工作都是在操作系统内核里做的,这就减轻了应用程序的负担,所以Nginx可以为每个连接只分配很小的内存维护状态,即使有几万、几十万的并发连接也只会消耗几百M内存,而其他的Web服务器这个时候早就“Memory not enough”了。
有了“进程池”和“I/O多路复用”,Nginx是如何处理HTTP请求的呢?
Nginx在内部也采用的是“化整为零”的思路,把整个Web服务器分解成了多个“功能模块”,就好像是乐高积木,可以在配置文件里任意拼接搭建,从而实现了高度的灵活性和扩展性。
Nginx的HTTP处理有四大类模块:
因为upstream模块和balance模块实现的是代理功能,Nginx作为“中间人”,运行机制比较复杂,所以我今天只讲handler模块和filter模块。
不知道你有没有了解过“设计模式”这方面的知识,其中有一个非常有用的模式叫做“职责链”。它就好像是工厂里的流水线,原料从一头流入,线上有许多工人会进行各种加工处理,最后从另一头出来的就是完整的产品。
Nginx里的handler模块和filter模块就是按照“职责链”模式设计和组织的,HTTP请求报文就是“原材料”,各种模块就是工厂里的工人,走完模块构成的“流水线”,出来的就是处理完成的响应报文。
下面的这张图显示了Nginx的“流水线”,在Nginx里的术语叫“阶段式处理”(Phases),一共有11个阶段,每个阶段里又有许多各司其职的模块。
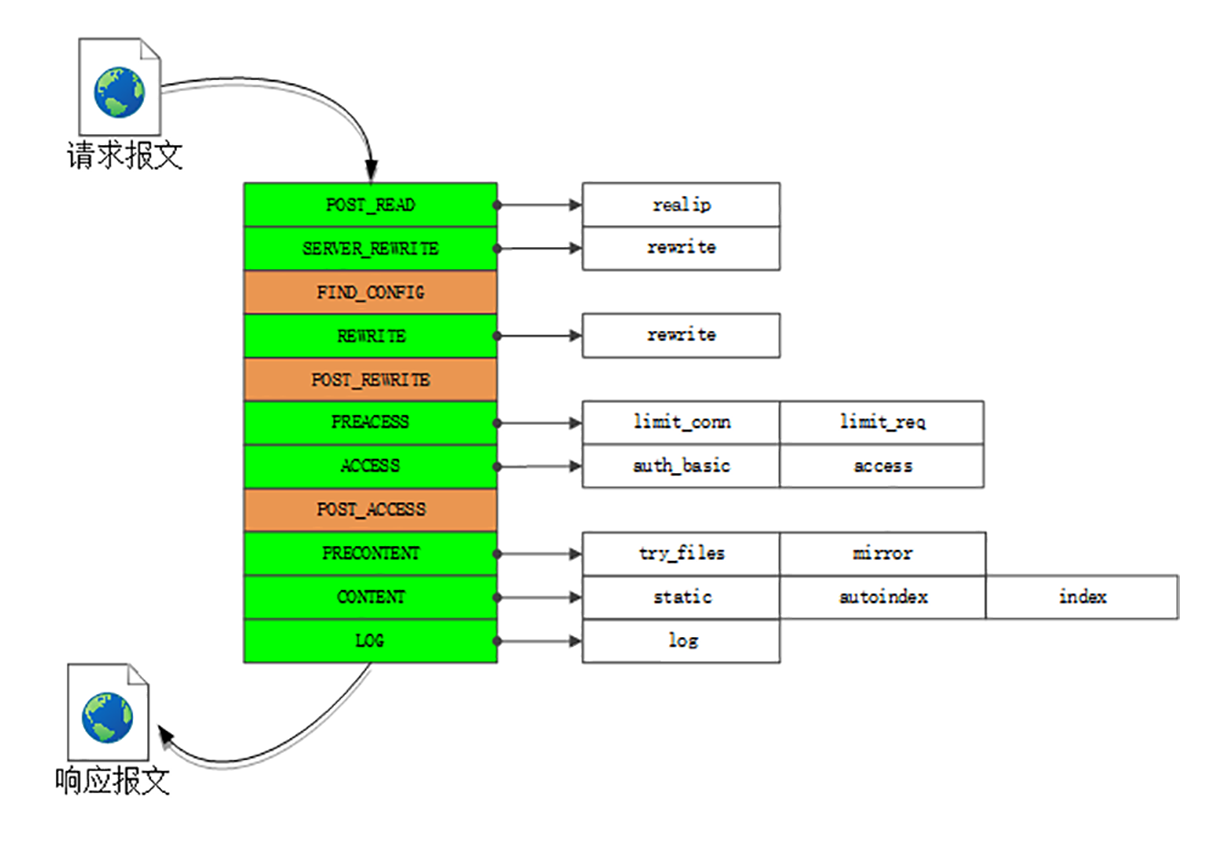
我简单列几个与我们的课程相关的模块吧:
在这张图里,你还可以看到limit_conn、limit_req、access、log等其他模块,它们实现的是限流限速、访问控制、日志等功能,不在HTTP协议规定之内,但对于运行在现实世界的Web服务器却是必备的。
如果你有C语言基础,感兴趣的话可以下载Nginx的源码,在代码级别仔细看看HTTP的处理过程。
欢迎你把自己的学习体会写在留言区,与我和其他同学一起讨论。如果你觉得有所收获,也欢迎把文章分享给你的朋友。

评论