你好,我是黄佳。
今天我们正式进入“业务场景闯关篇”模块。我在开篇词中介绍过,在这个模块中,我会围绕电商场景下的运营环节,带你挑战5个关卡:获客关、变现关、激活关、留存关和裂变关,帮你逐步掌握机器学习的相关知识和实操技巧。今天,我们就从第一关“获客关”开始!
人们常说移动互联网的运营已经进入了下半场,几乎所有的企业都希望能用更优质的产品和更精准的服务留住用户,这就需要制定出合适的获客策略。而要做到这一点,前提就是为用户精准画像,也就是根据用户的人口统计信息和消费行为数据,给用户分组,然后推测出用户的消费习惯和价值高低。
所以,为用户分组、画像,找到不同用户的特点,进而挖掘出哪些才是最有价值的用户,是目前互联网大厂中的数据分析师和机器学习工程师常做的工作。既然如此,那么我们就在获客关,结合一个具体的电商项目,来看看怎么根据用户的基本信息和消费行为数据,给用户分组画像。
按照我们前两讲所说的机器学习“实战5步”,我们首先要做的就是,把项目的问题定义清楚。在我们这个项目中,你可以想象自己就职于一家名为“易速鲜花”的创业公司,担任这家公司的运营团队机器学习工程师。你现在要接手的第一个项目就是为公司的用户分组画像。
现在,你们的运营部门已经准备好了过往用户的基本信息和消费行为数据,你可以在这里下载获取它,然后用Excel打开,就能看到这个数据集中所包含的详细信息。

既然我们要从这份销售订单数据中,为用户分组画像,那么有一个关键的问题就是,我们以什么为依据,给用户做分组?
我们知道,用户的消费行为本身是不能直接用于数据分析的,这就需要我们把用户的行为转化成具体的数值,也就是可量化的指标,让我们对用户有更直观的认识。而且我们还可以将这些指标用在数据分析、广告精准投放、产品推荐系统等多个运营场景,来提升我们产品和服务的精准度。
这个具体的数值呢,就是RFM(Recency、Frequency、Monetary ),它是用户画像的衍生品,也是目前很多互联网厂商普遍采用的分析方式。具体来看:
通过用户消费行为的新进度、消费的总体频率,还有消费总金额这三项指标,我们可以将用户划分为不同的类别或集群,来直观地描述用户的价值。什么意思呢?简单来说就是,只要我们从用户的基本信息和消费行为数据中得出RFM值,就可以根据它对用户分组画像了。
所以,我们这个项目整体上可以分为两个阶段:第一个阶段是求出RFM值,第二个阶段就是利用RFM值,给用户分组画像,进而绘制出高价值、中等价值和低价值用户的分布情况。我们今天这节课的目标就是解决第一阶段的问题。
搞清楚问题后,现在我们来看看这份数据的整体状况,根据需要对数据进行一个初步的预处理。
由于已经完成了数据收集工作,我们现在直接用Pandas中的read_csv工具,把这个原始数据集读入到Pandas的DataFrame中,用Dataframe形式呈现出来。关于Pandas包及其导入方式,如果你感觉比较陌生,可以再回顾一下第三讲的内容。
import pandas as pd #导入Pandas
df_sales = pd.read_csv('易速鲜花订单记录.csv') #载入数据
df_sales.head() #显示头几行数据
运行这段代码后,输出如下:
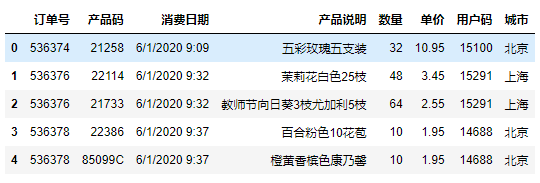
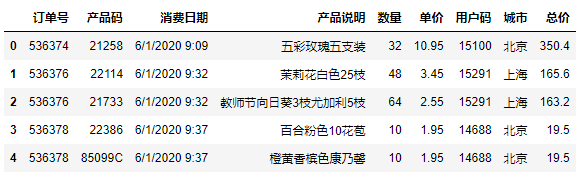
从图中,你可以看到这个数据集主要包含了订单号、产品码、消费日期,产品说明、数量、单价、用户码和城市等字段。因为我们求的是用户消费行为的新进度(R)、消费的总体频率(F),还有消费总金额(M),所以在这些信息中,我们重点关注的是以下几个数据:
为了对公司运营团队交给我们的数据集有一个宏观上的了解,下面我们先做一个整体的数据可视化,看看这个数据集所覆盖的消费日期跨度是怎样的。
我们直接来看具体的实现代码:
import matplotlib.pyplot as plt #导入Matplotlib的pyplot模块
#构建月度的订单数的DataFrame
df_sales['消费日期'] = pd.to_datetime(df_sales['消费日期']) #转化日期格式
df_orders_monthly = df_sales.set_index('消费日期')['订单号'].resample('M').nunique() #每个月的订单数量
#设定绘图的画布
ax = pd.DataFrame(df_orders_monthly.values).plot(grid=True,figsize=(12,6),legend=False)
ax.set_xlabel('月份') # X轴label
ax.set_ylabel('订单数') # Y轴Label
ax.set_title('月度订单数') # 图题
#设定X轴月份显示格式
plt.xticks(
range(len(df_orders_monthly.index)),
[x.strftime('%m.%Y') for x in df_orders_monthly.index],
rotation=45)
plt.show() # 绘图
在这段代码中,你需要注意的是,我们这里使用了Pandas的to_datetime这个API,把原始消费日期转换成了能处理的格式。而在df_orders_monthly中,则是求出了每一个月的订单数量。再往后的代码是具体的绘图工具使用,我就不过多说明了。
输出如下:
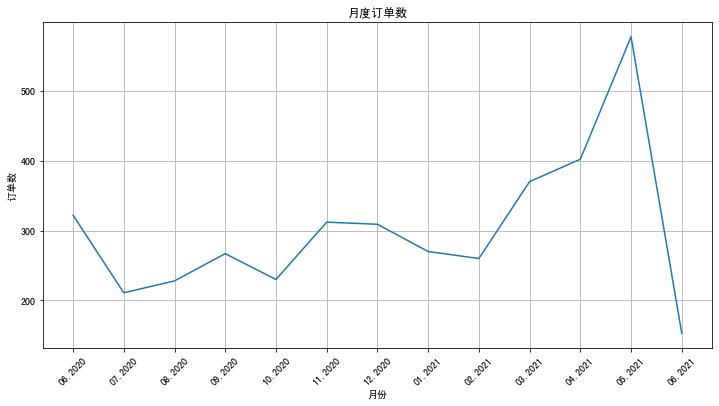
我们看到,这个数据集收集了“易速鲜花”公司一整年的订单量。所以啊,我们要求的消费额M,实际上是每个用户一整年的总消费额。
你可能已经注意到,在最后一个月,也就是2021年6月,订单量突然大幅下降。其实这是因为运营人员拉这个表的时候,正是6月的第一个礼拜。所以,6月的数据虽然不全,但并不会影响我们对用户RFM值的分析。
完成了初步可视化之后,我们来清洗一下数据。请你注意,在刚才的可视化过程中,我们已经完成了对消费日期的观察,并没有发现什么异常。所以,现在我们重点要处理的是用户码、单价和(订单中产品的)数量。
首先,我们用Pandas中的drop_duplicates方法把完全相同的重复数据行删除掉。
df_sales = df_sales.drop_duplicates() #删除重复的数据行
我之前介绍过,你还可以用DataFrame的isna().sum()函数,来统计NaN的个数。当然,如果你尝试了这个方法,会发现这个数据集中没有NaN值。
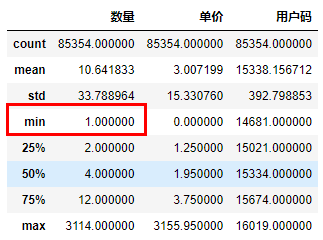
此外,对于数量、金额等类型的数据,我们还常常会使用describe方法来查看这些字段的统计信息是否有脏数据。
plain
df_sales.describe() #df_sales的统计信息
输出如下:
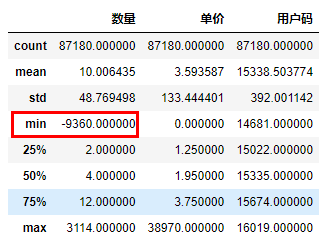
在图中你可以看到这个数据集中,共有9万多行的数据(count统计数据条目的数量),每条数据的平均采购数量是10(mean统计均值),商品平均单价是3.575元左右。
在概览中我们发现,(订单中产品的)数量的最小值(min)是一个负数(-9360),这显然是不符合逻辑的,所以我们要把这种脏数据清洗掉。具体的处理方式是,用loc属性通过字段名(也就是列名)访问数据集,同时只保留“数量”字段大于0的数据行:
df_sales = df_sales.loc[df_sales['数量'] > 0] #清洗掉数量小于等于0的数据
在DataFrame对象中,loc属性是通过行、列的名称来访问数据的,我们做数据预处理时会经常用到;还有一个常被用到的属性是iloc,它是通过行列的位置(也就是序号)来访问数据的。
由于数据行的名称往往也是数值,这两者非常容易被弄混。所以,在这里我特地给你做了一张图,来说明什么是行列名、什么是行列序号,帮你弄清楚它们的区别。
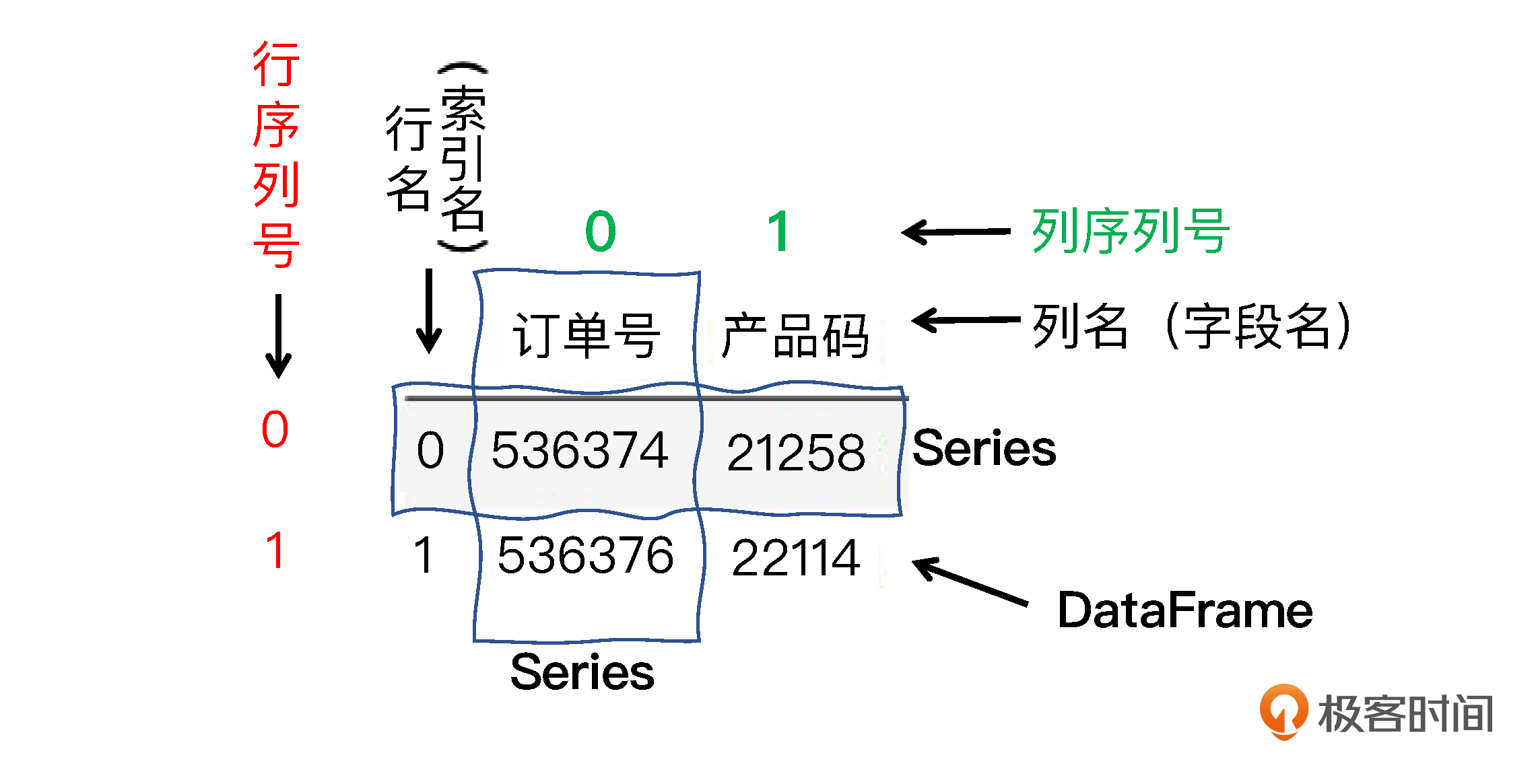
这个语句执行后,如果你再用一次describe方法,就会看到新的最小数量为1,这就对了。
到这里,我们就完成了数据清洗工作,这份数据集中已经没有可以剔除的脏数据了。接下来,我们就看看怎么从中求得RFM值。
不过在计算RFM之前,我想请你再回顾一下我们整个项目的目标。我们的目标就是建立一个机器学习模型,给用户做价值分组。而其中,RFM实际上就是我们构建模型所需的关键特征数据。
讲到这里,我想你应该很清楚了,虽说我们这节课要求出RFM的值,但实际上,我们是在完成机器学习项目中的“特征工程”环节,也就是对原始数据集中的信息进行选择、提取、合并、加工、转换,甚至是基于原始信息构建出新的、对于模型的训练更具有意义的特征。
明白了这一点,我们就可以继续往下走了。那怎么计算这个RFM值呢?
其实,这里的R值(最近一次消费的天数)和F值(消费频率),我们通过数据集中的消费日期就能得到,但是对于M值(消费金额),你会发现数据集中有采购数量,有单价,但是还没有每一笔消费的总价。
因此,我们通过一个语句对原有的数据集进行一个小小的扩展。在df_sales 这个DataFrame对象中增加一个数据列计算总价,总价等于由单价乘以数量:
df_sales['总价'] = df_sales['数量'] * df_sales['单价'] #计算每单的总价
df_sales.head() #显示头几行数据
输出如下:
现在,在这个数据集中,用户码、总价和消费日期这三个字段,给我们带来了每一个用户的R、F、M信息。其中:
不过,我们目前的这个数据集是一个订单的历史记录,并不是以用户码为主键的数据表。而R、F、M信息是和用户相关的,每一个用户都拥有一个独立的R值、F值和M值,所以,在计算RFM值之前,我们需要先构建一个用户层级表。
构建用户层级表,简单来说就是生成一个以用户码为关键字段的 Dataframe对象df_user,然后在这个Dataframe对象中,逐步加入每一个用户的新近度(R)、消费频率(F)、消费金额(M),以及最终总的分组信息。
在代码实现上,我们用Dataframe的unique() 这个API,就能创建出以用户码为关键字段的用户层级表df_user,然后我们再设定字段名,并根据用户码进行排序,最后显示出这个表,就可以了:
df_user = pd.DataFrame(df_sales['用户码'].unique()) #生成以用户码为主键的结构df_user
df_user.columns = ['用户码'] #设定字段名
df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #按用户码排序
df_user #显示df_user
请你注意,在上述语句中,reset_index(drop=True)的意思是重置索引,生成新的默认数值类型索引,并且不保留原来的索引。运行这段代码后,我们得到这样的结果:

可以看到,我们一共有980个用户的数据。有了用户层级表,现在我们依次求出RFM,让这个用户层级表的结构越来越完整。
我们知道,R值代表自用户上次消费以来的天数,它与最近一次消费的日期相关。所以,用表中最新订单的日期(拉出来这张表的日期)减去上一次消费的日期,就可以确定对应用户的R值。
下面是具体的代码实现,在每行代码中都给出了详细的注释,而且Pandas的语句也都不难理解,你可以看一看:
df_sales['消费日期'] = pd.to_datetime(df_sales['消费日期']) #转化日期格式
df_recent_buy = df_sales.groupby('用户码').消费日期.max().reset_index() #构建消费日期信息
df_recent_buy.columns = ['用户码','最近日期'] #设定字段名
df_recent_buy['R值'] = (df_recent_buy['最近日期'].max() - df_recent_buy['最近日期']).dt.days #计算最新日期与上次消费日期的天数
df_user = pd.merge(df_user, df_recent_buy[['用户码','R值']], on='用户码') #把上次消费距最新日期的天数(R值)合并至df_user结构
df_user.head() #显示df_user头几行数据
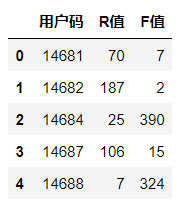
输出如下:

R值越大,说明该用户最近一次购物日距离当前日期越久,那么这样的用户就越是处于休眠状态。从表中可以看出来,编号为14682的用户已经有187天没有购物了。所以我们就可以判断这个用户呈现休眠态,很可能已经被别的购物平台所吸引了,也就是流失了。
类似地,我们还可以求出F值,并把F值添加至用户层级表:
df_frequency = df_sales.groupby('用户码').消费日期.count().reset_index() #计算每个用户消费次数,构建df_frequency对象
df_frequency.columns = ['用户码','F值'] #设定字段名称
df_user = pd.merge(df_user, df_frequency, on='用户码') #把消费频率整合至df_user结构
df_user.head() #显示头几行数据
这段代码的核心就是通过给消费日期做count()计数,来求出每一个用户的消费次数。最后,我们得到的输出结果如下:
M值很容易求出,它就是用户消费的总和:
df_revenue = df_sales.groupby('用户码').总价.sum().reset_index() #根据消费总额,构建df_revenue对象
df_revenue.columns = ['用户码','M值'] #设定字段名称
df_user = pd.merge(df_user, df_revenue, on='用户码') #把消费金额整合至df_user结构
df_user.head() #显示头几行数据
这段代码的核心是通过给用户每张订单的总价字段做sum()计数,来求出每一个用户的消费总和。最后,输出如下:
到这里,我们就求出了每一个用户的R、F、M值。不过,这只是完成了特征工程环节,在下节课,我们要根据这三个维度的值给用户分组,这就需要聚类算法大显身手了。
现在,我们来回顾一下这节课的重点。
我们这个项目的目标是为用户分组画像。要做分组画像,RFM分析是一个不错的方法,它也是目前很多互联网厂商普遍采用的分析方式。
我们今天的重点是,根据用户码、总价和消费日期这三个字段,从消费历史数据中求出每位用户的R、F、M的值,这就好像给用户贴上了一堆数字化的标签。同时,用户行为的量化,也可以视作是进一步做机器学习项目之前的特征工程。这也为我们后续给用户做聚类分组做好了准备。
理解RFM分析的精髓,并利用好RFM三个指标,是我们这个项目实战的核心价值所在。求出了RFM值,就恭喜你闯过了我们获客阶段的数据探索这一关。
虽然我把实战的具体过程讲得很细,但我更希望你理解的是“数据处理之道”, 而不是只学几个Python语句。Python语句都很简单,但是怎么灵活应用数据,是我们一开始就应该领悟的“道”,因为只有对思路的深入理解,才能让我们走得更高、更远。
好,这节课就到这里了,最后,我给你留个思考题:
RFM模型是衡量客户价值和客户创利能力的重要工具和手段,而且也被广泛应用在企业的获客、促销、客户关系管理等诸多营销、推广环节。请你谈一谈你对RFM的理解,以及这些指标可以应用于哪些业务场景。
欢迎你在留言区和我分享你的观点,如果你认为这节课的内容有收获,也欢迎把它分享给你的朋友,我们下一讲再见!

评论