
你好,我是鸟窝。
上一讲我们一起体验了Mutex的使用,竟是那么简单,只有简简单单两个方法,Lock和Unlock,进入临界区之前调用Lock方法,退出临界区的时候调用Unlock方法。这个时候,你一定会有一丝好奇:“它的实现是不是也很简单呢?”
其实不是的。如果你阅读Go标准库里Mutex的源代码,并且追溯Mutex的演进历史,你会发现,从一个简单易于理解的互斥锁的实现,到一个非常复杂的数据结构,这是一个逐步完善的过程。Go开发者们做了种种努力,精心设计。我自己每次看,都会被这种匠心和精益求精的精神打动。
所以,今天我就想带着你一起去探索Mutex的实现及演进之路,希望你能和我一样体验到这种技术追求的美妙。我们从Mutex的一个简单实现开始,看看它是怎样逐步提升性能和公平性的。在这个过程中,我们可以学习如何逐步设计一个完善的同步原语,并能对复杂度、性能、结构设计的权衡考量有新的认识。经过这样一个学习,我们不仅能通透掌握Mutex,更好地使用这个工具,同时,对我们自己设计并发数据接口也非常有帮助。
那具体怎么来讲呢?我把Mutex的架构演进分成了四个阶段,下面给你画了一张图来说明。
“初版”的Mutex使用一个flag来表示锁是否被持有,实现比较简单;后来照顾到新来的goroutine,所以会让新的goroutine也尽可能地先获取到锁,这是第二个阶段,我把它叫作“给新人机会”;那么,接下来就是第三阶段“多给些机会”,照顾新来的和被唤醒的goroutine;但是这样会带来饥饿问题,所以目前又加入了饥饿的解决方案,也就是第四阶段“解决饥饿”。
有了这四个阶段,我们学习的路径就清晰了,那接下来我会从代码层面带你领略Go开发者这些大牛们是如何逐步解决这些问题的。
我们先来看怎么实现一个最简单的互斥锁。在开始之前,你可以先想一想,如果是你,你会怎么设计呢?
你可能会想到,可以通过一个flag变量,标记当前的锁是否被某个goroutine持有。如果这个flag的值是1,就代表锁已经被持有,那么,其它竞争的goroutine只能等待;如果这个flag的值是0,就可以通过CAS(compare-and-swap,或者compare-and-set)将这个flag设置为1,标识锁被当前的这个goroutine持有了。
实际上,Russ Cox在2008年提交的第一版Mutex就是这样实现的。
// CAS操作,当时还没有抽象出atomic包
func cas(val *int32, old, new int32) bool
func semacquire(*int32)
func semrelease(*int32)
// 互斥锁的结构,包含两个字段
type Mutex struct {
key int32 // 锁是否被持有的标识
sema int32 // 信号量专用,用以阻塞/唤醒goroutine
}
// 保证成功在val上增加delta的值
func xadd(val *int32, delta int32) (new int32) {
for {
v := *val
if cas(val, v, v+delta) {
return v + delta
}
}
panic("unreached")
}
// 请求锁
func (m *Mutex) Lock() {
if xadd(&m.key, 1) == 1 { //标识加1,如果等于1,成功获取到锁
return
}
semacquire(&m.sema) // 否则阻塞等待
}
func (m *Mutex) Unlock() {
if xadd(&m.key, -1) == 0 { // 将标识减去1,如果等于0,则没有其它等待者
return
}
semrelease(&m.sema) // 唤醒其它阻塞的goroutine
}
这里呢,我先简单补充介绍下刚刚提到的CAS。
CAS指令将给定的值和一个内存地址中的值进行比较,如果它们是同一个值,就使用新值替换内存地址中的值,这个操作是原子性的。那啥是原子性呢?如果你还不太理解这个概念,那么在这里只需要明确一点就行了,那就是原子性保证这个指令总是基于最新的值进行计算,如果同时有其它线程已经修改了这个值,那么,CAS会返回失败。
CAS是实现互斥锁和同步原语的基础,我们很有必要掌握它。
好了,我们继续来分析下刚才的这段代码。
虽然当时的Go语法和现在的稍微有些不同,而且标准库的布局、实现和现在的也有很大的差异,但是,这些差异不会影响我们对代码的理解,因为最核心的结构体(struct)和函数、方法的定义几乎是一样的。
Mutex 结构体包含两个字段:

调用Lock请求锁的时候,通过xadd方法进行CAS操作(第24行),xadd方法通过循环执行CAS操作直到成功,保证对key加1的操作成功完成。如果比较幸运,锁没有被别的goroutine持有,那么,Lock方法成功地将key设置为1,这个goroutine就持有了这个锁;如果锁已经被别的goroutine持有了,那么,当前的goroutine会把key加1,而且还会调用semacquire方法(第27行),使用信号量将自己休眠,等锁释放的时候,信号量会将它唤醒。
持有锁的goroutine调用Unlock释放锁时,它会将key减1(第31行)。如果当前没有其它等待这个锁的goroutine,这个方法就返回了。但是,如果还有等待此锁的其它goroutine,那么,它会调用semrelease方法(第34行),利用信号量唤醒等待锁的其它goroutine中的一个。
所以,到这里,我们就知道了,初版的Mutex利用CAS原子操作,对key这个标志量进行设置。key不仅仅标识了锁是否被goroutine所持有,还记录了当前持有和等待获取锁的goroutine的数量。
Mutex的整体设计非常简洁,学习起来一点也没有障碍。但是,注意,我要划重点了。
Unlock方法可以被任意的goroutine调用释放锁,即使是没持有这个互斥锁的goroutine,也可以进行这个操作。这是因为,Mutex本身并没有包含持有这把锁的goroutine的信息,所以,Unlock也不会对此进行检查。Mutex的这个设计一直保持至今。
这就带来了一个有趣而危险的功能。为什么这么说呢?
你看,其它goroutine可以强制释放锁,这是一个非常危险的操作,因为在临界区的goroutine可能不知道锁已经被释放了,还会继续执行临界区的业务操作,这可能会带来意想不到的结果,因为这个goroutine还以为自己持有锁呢,有可能导致data race问题。
所以,我们在使用Mutex的时候,必须要保证goroutine尽可能不去释放自己未持有的锁,一定要遵循“谁申请,谁释放”的原则。在真实的实践中,我们使用互斥锁的时候,很少在一个方法中单独申请锁,而在另外一个方法中单独释放锁,一般都会在同一个方法中获取锁和释放锁。
如果你接触过其它语言(比如Java语言)的互斥锁的实现,就会发现这一点和其它语言的互斥锁不同,所以,如果是从其它语言转到Go语言开发的同学,一定要注意。
以前,我们经常会基于性能的考虑,及时释放掉锁,所以在一些if-else分支中加上释放锁的代码,代码看起来很臃肿。而且,在重构的时候,也很容易因为误删或者是漏掉而出现死锁的现象。
type Foo struct {
mu sync.Mutex
count int
}
func (f *Foo) Bar() {
f.mu.Lock()
if f.count < 1000 {
f.count += 3
f.mu.Unlock() // 此处释放锁
return
}
f.count++
f.mu.Unlock() // 此处释放锁
return
}
从1.14版本起,Go对defer做了优化,采用更有效的内联方式,取代之前的生成defer对象到defer chain中,defer对耗时的影响微乎其微了,所以基本上修改成下面简洁的写法也没问题:
func (f *Foo) Bar() {
f.mu.Lock()
defer f.mu.Unlock()
if f.count < 1000 {
f.count += 3
return
}
f.count++
return
}
这样做的好处就是Lock/Unlock总是成对紧凑出现,不会遗漏或者多调用,代码更少。
但是,如果临界区只是方法中的一部分,为了尽快释放锁,还是应该第一时间调用Unlock,而不是一直等到方法返回时才释放。
初版的Mutex实现之后,Go开发组又对Mutex做了一些微调,比如把字段类型变成了uint32类型;调用Unlock方法会做检查;使用atomic包的同步原语执行原子操作等等,这些小的改动,都不是核心功能,你简单知道就行了,我就不详细介绍了。
但是,初版的Mutex实现有一个问题:请求锁的goroutine会排队等待获取互斥锁。虽然这貌似很公平,但是从性能上来看,却不是最优的。因为如果我们能够把锁交给正在占用CPU时间片的goroutine的话,那就不需要做上下文的切换,在高并发的情况下,可能会有更好的性能。
接下来,我们就继续探索Go开发者是怎么解决这个问题的。
Go开发者在2011年6月30日的commit中对Mutex做了一次大的调整,调整后的Mutex实现如下:
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexWaiterShift = iota
)
虽然Mutex结构体还是包含两个字段,但是第一个字段已经改成了state,它的含义也不一样了。

state是一个复合型的字段,一个字段包含多个意义,这样可以通过尽可能少的内存来实现互斥锁。这个字段的第一位(最小的一位)来表示这个锁是否被持有,第二位代表是否有唤醒的goroutine,剩余的位数代表的是等待此锁的goroutine数。所以,state这一个字段被分成了三部分,代表三个数据。
请求锁的方法Lock也变得复杂了。复杂之处不仅仅在于对字段state的操作难以理解,而且代码逻辑也变得相当复杂。
func (m *Mutex) Lock() {
// Fast path: 幸运case,能够直接获取到锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
awoke := false
for {
old := m.state
new := old | mutexLocked // 新状态加锁
if old&mutexLocked != 0 {
new = old + 1<<mutexWaiterShift //等待者数量加一
}
if awoke {
// goroutine是被唤醒的,
// 新状态清除唤醒标志
new &^= mutexWoken
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {//设置新状态
if old&mutexLocked == 0 { // 锁原状态未加锁
break
}
runtime.Semacquire(&m.sema) // 请求信号量
awoke = true
}
}
}
首先是通过CAS检测state字段中的标志(第3行),如果没有goroutine持有锁,也没有等待持有锁的gorutine,那么,当前的goroutine就很幸运,可以直接获得锁,这也是注释中的Fast path的意思。
如果不够幸运,state不是零值,那么就通过一个循环进行检查。接下来的第7行到第26行这段代码虽然只有几行,但是理解起来却要费一番功夫,因为涉及到对state不同标志位的操作。这里的位操作以及操作后的结果和数值比较,并没有明确的解释,有时候你需要根据后续的处理进行推断。所以说,如果你充分理解了这段代码,那么对最新版的Mutex也会比较容易掌握了,因为你已经清楚了这些位操作的含义。
我们先前知道,如果想要获取锁的goroutine没有机会获取到锁,就会进行休眠,但是在锁释放唤醒之后,它并不能像先前一样直接获取到锁,还是要和正在请求锁的goroutine进行竞争。这会给后来请求锁的goroutine一个机会,也让CPU中正在执行的goroutine有更多的机会获取到锁,在一定程度上提高了程序的性能。
for循环是不断尝试获取锁,如果获取不到,就通过runtime.Semacquire(&m.sema)休眠,休眠醒来之后awoke置为true,尝试争抢锁。
代码中的第10行将当前的flag设置为加锁状态,如果能成功地通过CAS把这个新值赋予state(第19行和第20行),就代表抢夺锁的操作成功了。
不过,需要注意的是,如果成功地设置了state的值,但是之前的state是有锁的状态,那么,state只是清除mutexWoken标志或者增加一个waiter而已。
请求锁的goroutine有两类,一类是新来请求锁的goroutine,另一类是被唤醒的等待请求锁的goroutine。锁的状态也有两种:加锁和未加锁。我用一张表格,来说明一下goroutine不同来源不同状态下的处理逻辑。
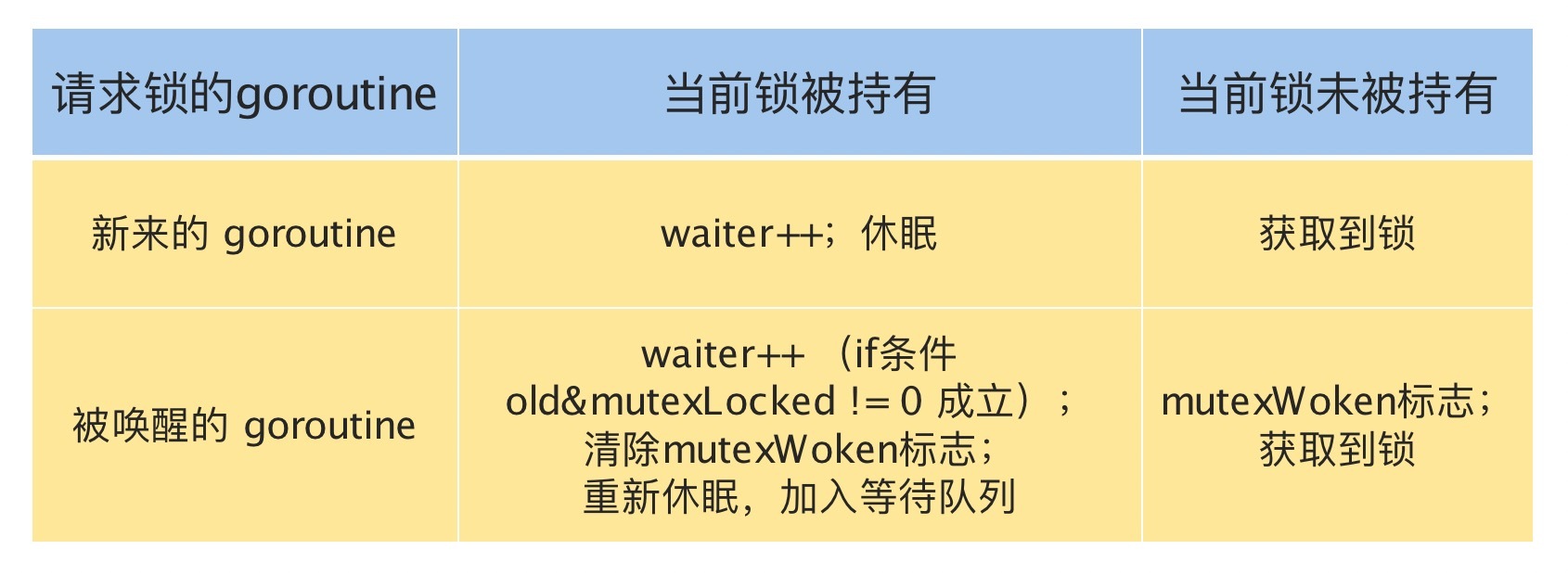
刚刚说的都是获取锁,接下来,我们再来看看释放锁。释放锁的Unlock方法也有些复杂,我们来看一下。
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked) //去掉锁标志
if (new+mutexLocked)&mutexLocked == 0 { //本来就没有加锁
panic("sync: unlock of unlocked mutex")
}
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken) != 0 { // 没有等待者,或者有唤醒的waiter,或者锁原来已加锁
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken // 新状态,准备唤醒goroutine,并设置唤醒标志
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime.Semrelease(&m.sema)
return
}
old = m.state
}
}
下面我来给你解释一下这个方法。
第3行是尝试将持有锁的标识设置为未加锁的状态,这是通过减1而不是将标志位置零的方式实现。第4到6行还会检测原来锁的状态是否已经未加锁的状态,如果是Unlock一个未加锁的Mutex会直接panic。
不过,即使将加锁置为未加锁的状态,这个方法也不能直接返回,还需要一些额外的操作,因为还可能有一些等待这个锁的goroutine(有时候我也把它们称之为waiter)需要通过信号量的方式唤醒它们中的一个。所以接下来的逻辑有两种情况。
第一种情况,如果没有其它的waiter,说明对这个锁的竞争的goroutine只有一个,那就可以直接返回了;如果这个时候有唤醒的goroutine,或者是又被别人加了锁,那么,无需我们操劳,其它goroutine自己干得都很好,当前的这个goroutine就可以放心返回了。
第二种情况,如果有等待者,并且没有唤醒的waiter,那就需要唤醒一个等待的waiter。在唤醒之前,需要将waiter数量减1,并且将mutexWoken标志设置上,这样,Unlock就可以返回了。
通过这样复杂的检查、判断和设置,我们就可以安全地将一把互斥锁释放了。
相对于初版的设计,这次的改动主要就是,新来的goroutine也有机会先获取到锁,甚至一个goroutine可能连续获取到锁,打破了先来先得的逻辑。但是,代码复杂度也显而易见。
虽然这一版的Mutex已经给新来请求锁的goroutine一些机会,让它参与竞争,没有空闲的锁或者竞争失败才加入到等待队列中。但是其实还可以进一步优化。我们接着往下看。
在2015年2月的改动中,如果新来的goroutine或者是被唤醒的goroutine首次获取不到锁,它们就会通过自旋(spin,通过循环不断尝试,spin的逻辑是在runtime实现的)的方式,尝试检查锁是否被释放。在尝试一定的自旋次数后,再执行原来的逻辑。
func (m *Mutex) Lock() {
// Fast path: 幸运之路,正好获取到锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
awoke := false
iter := 0
for { // 不管是新来的请求锁的goroutine, 还是被唤醒的goroutine,都不断尝试请求锁
old := m.state // 先保存当前锁的状态
new := old | mutexLocked // 新状态设置加锁标志
if old&mutexLocked != 0 { // 锁还没被释放
if runtime_canSpin(iter) { // 还可以自旋
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
continue // 自旋,再次尝试请求锁
}
new = old + 1<<mutexWaiterShift
}
if awoke { // 唤醒状态
if new&mutexWoken == 0 {
panic("sync: inconsistent mutex state")
}
new &^= mutexWoken // 新状态清除唤醒标记
}
if atomic.CompareAndSwapInt32(&m.state, old, new) {
if old&mutexLocked == 0 { // 旧状态锁已释放,新状态成功持有了锁,直接返回
break
}
runtime_Semacquire(&m.sema) // 阻塞等待
awoke = true // 被唤醒
iter = 0
}
}
}
这次的优化,增加了第13行到21行、第25行到第27行以及第36行。我来解释一下主要的逻辑,也就是第13行到21行。
如果可以spin的话,第9行的for循环会重新检查锁是否释放。对于临界区代码执行非常短的场景来说,这是一个非常好的优化。因为临界区的代码耗时很短,锁很快就能释放,而抢夺锁的goroutine不用通过休眠唤醒方式等待调度,直接spin几次,可能就获得了锁。
经过几次优化,Mutex的代码越来越复杂,应对高并发争抢锁的场景也更加公平。但是你有没有想过,因为新来的goroutine也参与竞争,有可能每次都会被新来的goroutine抢到获取锁的机会,在极端情况下,等待中的goroutine可能会一直获取不到锁,这就是饥饿问题。
说到这儿,我突然想到了最近看到的一种叫做鹳的鸟。如果鹳妈妈寻找食物很艰难,找到的食物只够一个幼鸟吃的,鹳妈妈就会把食物给最强壮的一只,这样一来,饥饿弱小的幼鸟总是得不到食物吃,最后就会被啄出巢去。
先前版本的Mutex遇到的也是同样的困境,“悲惨”的goroutine总是得不到锁。
Mutex不能容忍这种事情发生。所以,2016年Go 1.9中Mutex增加了饥饿模式,让锁变得更公平,不公平的等待时间限制在1毫秒,并且修复了一个大Bug:总是把唤醒的goroutine放在等待队列的尾部,会导致更加不公平的等待时间。
之后,2018年,Go开发者将fast path和slow path拆成独立的方法,以便内联,提高性能。2019年也有一个Mutex的优化,虽然没有对Mutex做修改,但是,对于Mutex唤醒后持有锁的那个waiter,调度器可以有更高的优先级去执行,这已经是很细致的性能优化了。
为了避免代码过多,这里只列出当前的Mutex实现。想要理解当前的Mutex,我们需要好好泡一杯茶,仔细地品一品了。
当然,现在的Mutex代码已经复杂得接近不可读的状态了,而且代码也非常长,删减后占了几乎三页纸。但是,作为第一个要详细介绍的同步原语,我还是希望能更清楚地剖析Mutex的实现,向你展示它的演化和为了一个貌似很小的feature不得不将代码变得非常复杂的原因。

当然,你也可以暂时略过这一段,以后慢慢品,只需要记住,Mutex绝不容忍一个goroutine被落下,永远没有机会获取锁。不抛弃不放弃是它的宗旨,而且它也尽可能地让等待较长的goroutine更有机会获取到锁。
type Mutex struct {
state int32
sema uint32
}
const (
mutexLocked = 1 << iota // mutex is locked
mutexWoken
mutexStarving // 从state字段中分出一个饥饿标记
mutexWaiterShift = iota
starvationThresholdNs = 1e6
)
func (m *Mutex) Lock() {
// Fast path: 幸运之路,一下就获取到了锁
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path:缓慢之路,尝试自旋竞争或饥饿状态下饥饿goroutine竞争
m.lockSlow()
}
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false // 此goroutine的饥饿标记
awoke := false // 唤醒标记
iter := 0 // 自旋次数
old := m.state // 当前的锁的状态
for {
// 锁是非饥饿状态,锁还没被释放,尝试自旋
if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {
if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&
atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {
awoke = true
}
runtime_doSpin()
iter++
old = m.state // 再次获取锁的状态,之后会检查是否锁被释放了
continue
}
new := old
if old&mutexStarving == 0 {
new |= mutexLocked // 非饥饿状态,加锁
}
if old&(mutexLocked|mutexStarving) != 0 {
new += 1 << mutexWaiterShift // waiter数量加1
}
if starving && old&mutexLocked != 0 {
new |= mutexStarving // 设置饥饿状态
}
if awoke {
if new&mutexWoken == 0 {
throw("sync: inconsistent mutex state")
}
new &^= mutexWoken // 新状态清除唤醒标记
}
// 成功设置新状态
if atomic.CompareAndSwapInt32(&m.state, old, new) {
// 原来锁的状态已释放,并且不是饥饿状态,正常请求到了锁,返回
if old&(mutexLocked|mutexStarving) == 0 {
break // locked the mutex with CAS
}
// 处理饥饿状态
// 如果以前就在队列里面,加入到队列头
queueLifo := waitStartTime != 0
if waitStartTime == 0 {
waitStartTime = runtime_nanotime()
}
// 阻塞等待
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
// 唤醒之后检查锁是否应该处于饥饿状态
starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs
old = m.state
// 如果锁已经处于饥饿状态,直接抢到锁,返回
if old&mutexStarving != 0 {
if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {
throw("sync: inconsistent mutex state")
}
// 有点绕,加锁并且将waiter数减1
delta := int32(mutexLocked - 1<<mutexWaiterShift)
if !starving || old>>mutexWaiterShift == 1 {
delta -= mutexStarving // 最后一个waiter或者已经不饥饿了,清除饥饿标记
}
atomic.AddInt32(&m.state, delta)
break
}
awoke = true
iter = 0
} else {
old = m.state
}
}
}
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
m.unlockSlow(new)
}
}
func (m *Mutex) unlockSlow(new int32) {
if (new+mutexLocked)&mutexLocked == 0 {
throw("sync: unlock of unlocked mutex")
}
if new&mutexStarving == 0 {
old := new
for {
if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {
return
}
new = (old - 1<<mutexWaiterShift) | mutexWoken
if atomic.CompareAndSwapInt32(&m.state, old, new) {
runtime_Semrelease(&m.sema, false, 1)
return
}
old = m.state
}
} else {
runtime_Semrelease(&m.sema, true, 1)
}
}
跟之前的实现相比,当前的Mutex最重要的变化,就是增加饥饿模式。第12行将饥饿模式的最大等待时间阈值设置成了1毫秒,这就意味着,一旦等待者等待的时间超过了这个阈值,Mutex的处理就有可能进入饥饿模式,优先让等待者先获取到锁,新来的同学主动谦让一下,给老同志一些机会。
通过加入饥饿模式,可以避免把机会全都留给新来的goroutine,保证了请求锁的goroutine获取锁的公平性,对于我们使用锁的业务代码来说,不会有业务一直等待锁不被处理。
那么,接下来的部分就是选学内容了。如果你还有精力,并且对饥饿模式很感兴趣,那就跟着我一起继续来挑战吧。如果你现在理解起来觉得有困难,也没关系,后面可以随时回来复习。
Mutex可能处于两种操作模式下:正常模式和饥饿模式。
接下来我们分析一下Mutex对饥饿模式和正常模式的处理。
请求锁时调用的Lock方法中一开始是fast path,这是一个幸运的场景,当前的goroutine幸运地获得了锁,没有竞争,直接返回,否则就进入了lockSlow方法。这样的设计,方便编译器对Lock方法进行内联,你也可以在程序开发中应用这个技巧。
正常模式下,waiter都是进入先入先出队列,被唤醒的waiter并不会直接持有锁,而是要和新来的goroutine进行竞争。新来的goroutine有先天的优势,它们正在CPU中运行,可能它们的数量还不少,所以,在高并发情况下,被唤醒的waiter可能比较悲剧地获取不到锁,这时,它会被插入到队列的前面。如果waiter获取不到锁的时间超过阈值1毫秒,那么,这个Mutex就进入到了饥饿模式。
在饥饿模式下,Mutex的拥有者将直接把锁交给队列最前面的waiter。新来的goroutine不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会spin,它会乖乖地加入到等待队列的尾部。
如果拥有Mutex的waiter发现下面两种情况的其中之一,它就会把这个Mutex转换成正常模式:
正常模式拥有更好的性能,因为即使有等待抢锁的waiter,goroutine也可以连续多次获取到锁。
饥饿模式是对公平性和性能的一种平衡,它避免了某些goroutine长时间的等待锁。在饥饿模式下,优先对待的是那些一直在等待的waiter。
接下来,我们逐步分析下Mutex代码的关键行,彻底搞清楚饥饿模式的细节。
我们从请求锁(lockSlow)的逻辑看起。
第9行对state字段又分出了一位,用来标记锁是否处于饥饿状态。现在一个state的字段被划分成了阻塞等待的waiter数量、饥饿标记、唤醒标记和持有锁的标记四个部分。
第25行记录此goroutine请求锁的初始时间,第26行标记是否处于饥饿状态,第27行标记是否是唤醒的,第28行记录spin的次数。
第31行到第40行和以前的逻辑类似,只不过加了一个不能是饥饿状态的逻辑。它会对正常状态抢夺锁的goroutine尝试spin,和以前的目的一样,就是在临界区耗时很短的情况下提高性能。
第42行到第44行,非饥饿状态下抢锁。怎么抢?就是要把state的锁的那一位,置为加锁状态,后续CAS如果成功就可能获取到了锁。
第46行到第48行,如果锁已经被持有或者锁处于饥饿状态,我们最好的归宿就是等待,所以waiter的数量加1。
第49行到第51行,如果此goroutine已经处在饥饿状态,并且锁还被持有,那么,我们需要把此Mutex设置为饥饿状态。
第52行到第57行,是清除mutexWoken标记,因为不管是获得了锁还是进入休眠,我们都需要清除mutexWoken标记。
第59行就是尝试使用CAS设置state。如果成功,第61行到第63行是检查原来的锁的状态是未加锁状态,并且也不是饥饿状态的话就成功获取了锁,返回。
第67行判断是否第一次加入到waiter队列。到这里,你应该就能明白第25行为什么不对waitStartTime进行初始化了,我们需要利用它在这里进行条件判断。
第72行将此waiter加入到队列,如果是首次,加入到队尾,先进先出。如果不是首次,那么加入到队首,这样等待最久的goroutine优先能够获取到锁。此goroutine会进行休眠。
第74行判断此goroutine是否处于饥饿状态。注意,执行这一句的时候,它已经被唤醒了。
第77行到第88行是对锁处于饥饿状态下的一些处理。
第82行设置一个标志,这个标志稍后会用来加锁,而且还会将waiter数减1。
第84行,设置标志,在没有其它的waiter或者此goroutine等待还没超过1毫秒,则会将Mutex转为正常状态。
第86行则是将这个标识应用到state字段上。
释放锁(Unlock)时调用的Unlock的fast path不用多少,所以我们主要看unlockSlow方法就行。
如果Mutex处于饥饿状态,第123行直接唤醒等待队列中的waiter。
如果Mutex处于正常状态,如果没有waiter,或者已经有在处理的情况了,那么释放就好,不做额外的处理(第112行到第114行)。
否则,waiter数减1,mutexWoken标志设置上,通过CAS更新state的值(第115行到第119行)。
“罗马不是一天建成的”,Mutex的设计也是从简单设计到复杂处理逐渐演变的。初版的Mutex设计非常简洁,充分展示了Go创始者的简单、简洁的设计哲学。但是,随着大家的使用,逐渐暴露出一些缺陷,为了弥补这些缺陷,Mutex不得不越来越复杂。
有一点值得我们学习的,同时也体现了Go创始者的哲学,就是他们强调GO语言和标准库的稳定性,新版本要向下兼容,用新的版本总能编译老的代码。Go语言从出生到现在已经10多年了,这个Mutex对外的接口却没有变化,依然向下兼容,即使现在Go出了两个版本,每个版本也会向下兼容,保持Go语言的稳定性,你也能领悟他们软件开发和设计的思想。
还有一点,你也可以观察到,为了一个程序20%的特性,你可能需要添加80%的代码,这也是程序越来越复杂的原因。所以,最开始的时候,如果能够有一个清晰而且易于扩展的设计,未来增加新特性时,也会更加方便。
最后,给你留两个小问题:
欢迎在留言区写下你的思考和答案,我们一起交流讨论。如果你觉得有所收获,也欢迎你把今天的内容分享给你的朋友或同事。
评论