你好,我是鸟窝。
WaitGroup,我们以前都多多少少学习过,或者是使用过。其实,WaitGroup很简单,就是package sync用来做任务编排的一个并发原语。它要解决的就是并发-等待的问题:现在有一个goroutine A 在检查点(checkpoint)等待一组goroutine全部完成,如果在执行任务的这些goroutine还没全部完成,那么goroutine A就会阻塞在检查点,直到所有goroutine都完成后才能继续执行。
我们来看一个使用WaitGroup的场景。
比如,我们要完成一个大的任务,需要使用并行的goroutine执行三个小任务,只有这三个小任务都完成,我们才能去执行后面的任务。如果通过轮询的方式定时询问三个小任务是否完成,会存在两个问题:一是,性能比较低,因为三个小任务可能早就完成了,却要等很长时间才被轮询到;二是,会有很多无谓的轮询,空耗CPU资源。
那么,这个时候使用WaitGroup并发原语就比较有效了,它可以阻塞等待的goroutine。等到三个小任务都完成了,再即时唤醒它们。
其实,很多操作系统和编程语言都提供了类似的并发原语。比如,Linux中的barrier、Pthread(POSIX线程)中的barrier、C++中的std::barrier、Java中的CyclicBarrier和CountDownLatch等。由此可见,这个并发原语还是一个非常基础的并发类型。所以,我们要认真掌握今天的内容,这样就可以举一反三,轻松应对其他场景下的需求了。
我们还是从WaitGroup的基本用法学起吧。
Go标准库中的WaitGroup提供了三个方法,保持了Go简洁的风格。
func (wg *WaitGroup) Add(delta int)
func (wg *WaitGroup) Done()
func (wg *WaitGroup) Wait()
我们分别看下这三个方法:
接下来,我们通过一个使用WaitGroup的例子,来看下Add、Done、Wait方法的基本用法。
在这个例子中,我们使用了以前实现的计数器struct。我们启动了10个worker,分别对计数值加一,10个worker都完成后,我们期望输出计数器的值。
// 线程安全的计数器
type Counter struct {
mu sync.Mutex
count uint64
}
// 对计数值加一
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 获取当前的计数值
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
// sleep 1秒,然后计数值加1
func worker(c *Counter, wg *sync.WaitGroup) {
defer wg.Done()
time.Sleep(time.Second)
c.Incr()
}
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10) // WaitGroup的值设置为10
for i := 0; i < 10; i++ { // 启动10个goroutine执行加1任务
go worker(&counter, &wg)
}
// 检查点,等待goroutine都完成任务
wg.Wait()
// 输出当前计数器的值
fmt.Println(counter.Count())
}
我们一起来分析下这段代码。
这就是我们使用WaitGroup编排这类任务的常用方式。而“这类任务”指的就是,需要启动多个goroutine执行任务,主goroutine需要等待子goroutine都完成后才继续执行。
熟悉了WaitGroup的基本用法后,我们再看看它具体是如何实现的吧。
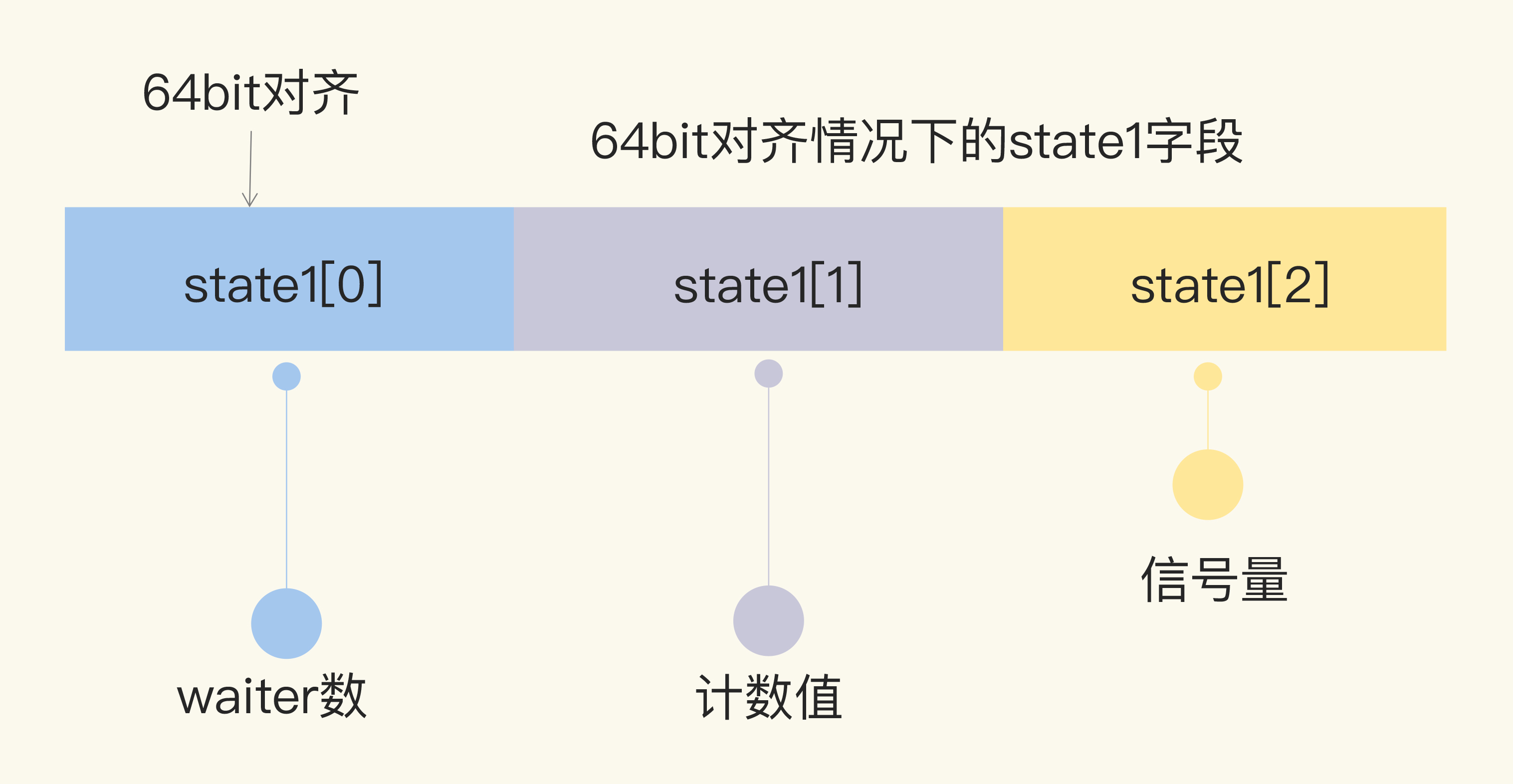
首先,我们看看WaitGroup的数据结构。它包括了一个noCopy的辅助字段,一个state1记录WaitGroup状态的数组。
WaitGroup的数据结构定义以及state信息的获取方法如下:
type WaitGroup struct {
// 避免复制使用的一个技巧,可以告诉vet工具违反了复制使用的规则
noCopy noCopy
// 64bit(8bytes)的值分成两段,高32bit是计数值,低32bit是waiter的计数
// 另外32bit是用作信号量的
// 因为64bit值的原子操作需要64bit对齐,但是32bit编译器不支持,所以数组中的元素在不同的架构中不一样,具体处理看下面的方法
// 总之,会找到对齐的那64bit作为state,其余的32bit做信号量
state1 [3]uint32
}
// 得到state的地址和信号量的地址
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// 如果地址是64bit对齐的,数组前两个元素做state,后一个元素做信号量
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
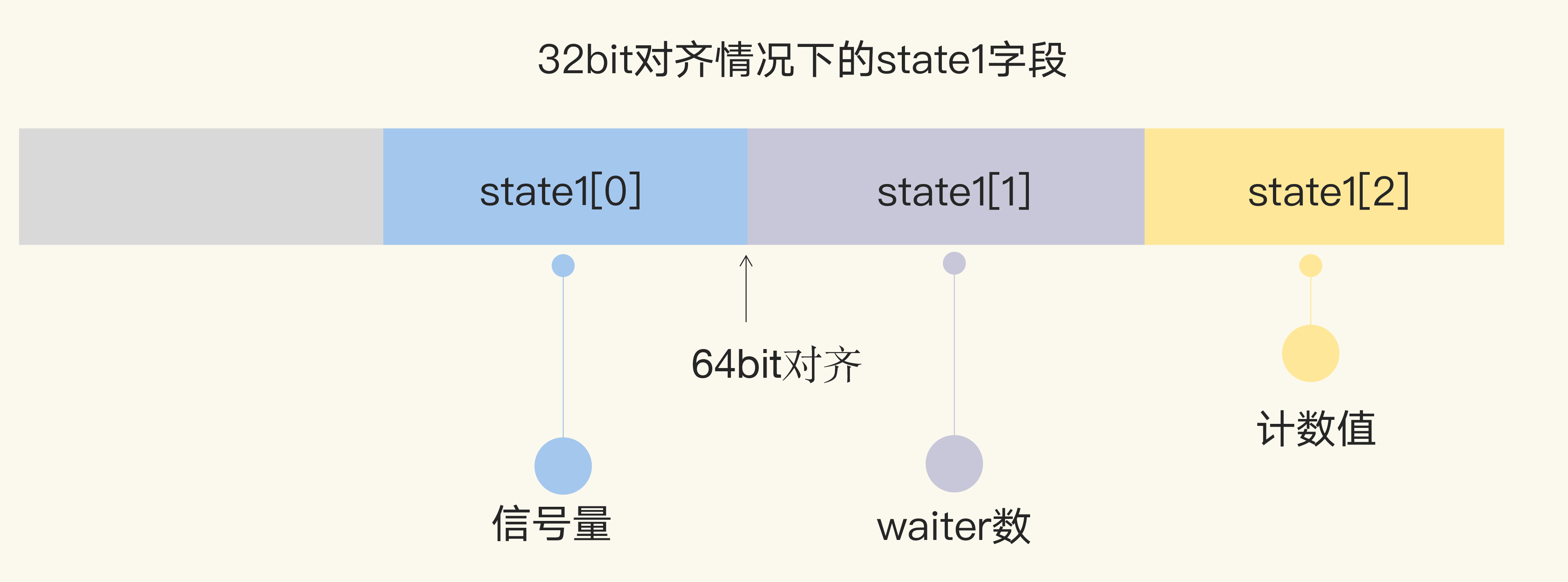
// 如果地址是32bit对齐的,数组后两个元素用来做state,它可以用来做64bit的原子操作,第一个元素32bit用来做信号量
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
因为对64位整数的原子操作要求整数的地址是64位对齐的,所以针对64位和32位环境的state字段的组成是不一样的。
在64位环境下,state1的第一个元素是waiter数,第二个元素是WaitGroup的计数值,第三个元素是信号量。
在32位环境下,如果state1不是64位对齐的地址,那么state1的第一个元素是信号量,后两个元素分别是waiter数和计数值。
然后,我们继续深入源码,看一下Add、Done和Wait这三个方法的实现。
在查看这部分源码实现时,我们会发现,除了这些方法本身的实现外,还会有一些额外的代码,主要是race检查和异常检查的代码。其中,有几个检查非常关键,如果检查不通过,会出现panic,这部分内容我会在下一小节分析WaitGroup的错误使用场景时介绍。现在,我们先专注在Add、Wait和Done本身的实现代码上。
我先为你梳理下Add方法的逻辑。Add方法主要操作的是state的计数部分。你可以为计数值增加一个delta值,内部通过原子操作把这个值加到计数值上。需要注意的是,这个delta也可以是个负数,相当于为计数值减去一个值,Done方法内部其实就是通过Add(-1)实现的。
它的实现代码如下:
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
// 高32bit是计数值v,所以把delta左移32,增加到计数上
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32) // 当前计数值
w := uint32(state) // waiter count
if v > 0 || w == 0 {
return
}
// 如果计数值v为0并且waiter的数量w不为0,那么state的值就是waiter的数量
// 将waiter的数量设置为0,因为计数值v也是0,所以它们俩的组合*statep直接设置为0即可。此时需要并唤醒所有的waiter
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
// Done方法实际就是计数器减1
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
Wait方法的实现逻辑是:不断检查state的值。如果其中的计数值变为了0,那么说明所有的任务已完成,调用者不必再等待,直接返回。如果计数值大于0,说明此时还有任务没完成,那么调用者就变成了等待者,需要加入waiter队列,并且阻塞住自己。
其主干实现代码如下:
func (wg *WaitGroup) Wait() {
statep, semap := wg.state()
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32) // 当前计数值
w := uint32(state) // waiter的数量
if v == 0 {
// 如果计数值为0, 调用这个方法的goroutine不必再等待,继续执行它后面的逻辑即可
return
}
// 否则把waiter数量加1。期间可能有并发调用Wait的情况,所以最外层使用了一个for循环
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// 阻塞休眠等待
runtime_Semacquire(semap)
// 被唤醒,不再阻塞,返回
return
}
}
}
在分析WaitGroup的Add、Done和Wait方法的实现的时候,为避免干扰,我删除了异常检查的代码。但是,这些异常检查非常有用。
我们在开发的时候,经常会遇见或看到误用WaitGroup的场景,究其原因就是没有弄明白这些检查的逻辑。所以接下来,我们就通过几个小例子,一起学习下在开发时绝对要避免的3个问题。
WaitGroup的计数器的值必须大于等于0。我们在更改这个计数值的时候,WaitGroup会先做检查,如果计数值被设置为负数,就会导致panic。
一般情况下,有两种方法会导致计数器设置为负数。
第一种方法是:调用Add的时候传递一个负数。如果你能保证当前的计数器加上这个负数后还是大于等于0的话,也没有问题,否则就会导致panic。
比如下面这段代码,计数器的初始值为10,当第一次传入-10的时候,计数值被设置为0,不会有啥问题。但是,再紧接着传入-1以后,计数值就被设置为负数了,程序就会出现panic。
func main() {
var wg sync.WaitGroup
wg.Add(10)
wg.Add(-10)//将-10作为参数调用Add,计数值被设置为0
wg.Add(-1)//将-1作为参数调用Add,如果加上-1计数值就会变为负数。这是不对的,所以会触发panic
}
第二个方法是:调用Done方法的次数过多,超过了WaitGroup的计数值。
使用WaitGroup的正确姿势是,预先确定好WaitGroup的计数值,然后调用相同次数的Done完成相应的任务。比如,在WaitGroup变量声明之后,就立即设置它的计数值,或者在goroutine启动之前增加1,然后在goroutine中调用Done。
如果你没有遵循这些规则,就很可能会导致Done方法调用的次数和计数值不一致,进而造成死锁(Done调用次数比计数值少)或者panic(Done调用次数比计数值多)。
比如下面这个例子中,多调用了一次Done方法后,会导致计数值为负,所以程序运行到这一行会出现panic。
func main() {
var wg sync.WaitGroup
wg.Add(1)
wg.Done()
wg.Done()
}
在使用WaitGroup的时候,你一定要遵循的原则就是,等所有的Add方法调用之后再调用Wait,否则就可能导致panic或者不期望的结果。
我们构造这样一个场景:只有部分的Add/Done执行完后,Wait就返回。我们看一个例子:启动四个goroutine,每个goroutine内部调用Add(1)然后调用Done(),主goroutine调用Wait等待任务完成。
func main() {
var wg sync.WaitGroup
go dosomething(100, &wg) // 启动第一个goroutine
go dosomething(110, &wg) // 启动第二个goroutine
go dosomething(120, &wg) // 启动第三个goroutine
go dosomething(130, &wg) // 启动第四个goroutine
wg.Wait() // 主goroutine等待完成
fmt.Println("Done")
}
func dosomething(millisecs time.Duration, wg *sync.WaitGroup) {
duration := millisecs * time.Millisecond
time.Sleep(duration) // 故意sleep一段时间
wg.Add(1)
fmt.Println("后台执行, duration:", duration)
wg.Done()
}
在这个例子中,我们原本设想的是,等四个goroutine都执行完毕后输出Done的信息,但是它的错误之处在于,将WaitGroup.Add方法的调用放在了子gorotuine中。等主goorutine调用Wait的时候,因为四个任务goroutine一开始都休眠,所以可能WaitGroup的Add方法还没有被调用,WaitGroup的计数还是0,所以它并没有等待四个子goroutine执行完毕才继续执行,而是立刻执行了下一步。
导致这个错误的原因是,没有遵循先完成所有的Add之后才Wait。要解决这个问题,一个方法是,预先设置计数值:
func main() {
var wg sync.WaitGroup
wg.Add(4) // 预先设定WaitGroup的计数值
go dosomething(100, &wg) // 启动第一个goroutine
go dosomething(110, &wg) // 启动第二个goroutine
go dosomething(120, &wg) // 启动第三个goroutine
go dosomething(130, &wg) // 启动第四个goroutine
wg.Wait() // 主goroutine等待
fmt.Println("Done")
}
func dosomething(millisecs time.Duration, wg *sync.WaitGroup) {
duration := millisecs * time.Millisecond
time.Sleep(duration)
fmt.Println("后台执行, duration:", duration)
wg.Done()
}
另一种方法是在启动子goroutine之前才调用Add:
func main() {
var wg sync.WaitGroup
dosomething(100, &wg) // 调用方法,把计数值加1,并启动任务goroutine
dosomething(110, &wg) // 调用方法,把计数值加1,并启动任务goroutine
dosomething(120, &wg) // 调用方法,把计数值加1,并启动任务goroutine
dosomething(130, &wg) // 调用方法,把计数值加1,并启动任务goroutine
wg.Wait() // 主goroutine等待,代码逻辑保证了四次Add(1)都已经执行完了
fmt.Println("Done")
}
func dosomething(millisecs time.Duration, wg *sync.WaitGroup) {
wg.Add(1) // 计数值加1,再启动goroutine
go func() {
duration := millisecs * time.Millisecond
time.Sleep(duration)
fmt.Println("后台执行, duration:", duration)
wg.Done()
}()
}
可见,无论是怎么修复,都要保证所有的Add方法是在Wait方法之前被调用的。
“前一个Wait还没结束就重用WaitGroup”这一点似乎不太好理解,我借用田径比赛的例子和你解释下吧。在田径比赛的百米小组赛中,需要把选手分成几组,一组选手比赛完之后,就可以进行下一组了。为了确保两组比赛时间上没有冲突,我们在模型化这个场景的时候,可以使用WaitGroup。
WaitGroup等一组比赛的所有选手都跑完后5分钟,才开始下一组比赛。下一组比赛还可以使用这个WaitGroup来控制,因为WaitGroup是可以重用的。只要WaitGroup的计数值恢复到零值的状态,那么它就可以被看作是新创建的WaitGroup,被重复使用。
但是,如果我们在WaitGroup的计数值还没有恢复到零值的时候就重用,就会导致程序panic。我们看一个例子,初始设置WaitGroup的计数值为1,启动一个goroutine先调用Done方法,接着就调用Add方法,Add方法有可能和主goroutine并发执行。
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
time.Sleep(time.Millisecond)
wg.Done() // 计数器减1
wg.Add(1) // 计数值加1
}()
wg.Wait() // 主goroutine等待,有可能和第7行并发执行
}
在这个例子中,第6行虽然让WaitGroup的计数恢复到0,但是因为第9行有个waiter在等待,如果等待Wait的goroutine,刚被唤醒就和Add调用(第7行)有并发执行的冲突,所以就会出现panic。
总结一下:WaitGroup虽然可以重用,但是是有一个前提的,那就是必须等到上一轮的Wait完成之后,才能重用WaitGroup执行下一轮的Add/Wait,如果你在Wait还没执行完的时候就调用下一轮Add方法,就有可能出现panic。
我们刚刚在学习WaitGroup的数据结构时,提到了里面有一个noCopy字段。你还记得它的作用吗?其实,它就是指示vet工具在做检查的时候,这个数据结构不能做值复制使用。更严谨地说,是不能在第一次使用之后复制使用( must not be copied after first use)。
你可能会说了,为什么要把noCopy字段单独拿出来讲呢?一方面,把noCopy字段穿插到waitgroup代码中讲解,容易干扰我们对WaitGroup整体的理解。另一方面,也是非常重要的原因,noCopy是一个通用的计数技术,其他并发原语中也会用到,所以单独介绍有助于你以后在实践中使用这个技术。
我们在第3讲学习Mutex的时候用到了vet工具。vet会对实现Locker接口的数据类型做静态检查,一旦代码中有复制使用这种数据类型的情况,就会发出警告。但是,WaitGroup同步原语不就是Add、Done和Wait方法吗?vet能检查出来吗?
其实是可以的。通过给WaitGroup添加一个noCopy字段,我们就可以为WaitGroup实现Locker接口,这样vet工具就可以做复制检查了。而且因为noCopy字段是未输出类型,所以WaitGroup不会暴露Lock/Unlock方法。
noCopy字段的类型是noCopy,它只是一个辅助的、用来帮助vet检查用的类型:
type noCopy struct{}
// Lock is a no-op used by -copylocks checker from `go vet`.
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
如果你想要自己定义的数据结构不被复制使用,或者说,不能通过vet工具检查出复制使用的报警,就可以通过嵌入noCopy这个数据类型来实现。
接下来又到了喝枸杞红枣茶的时间了。你可以稍微休息一下,心态放轻松地跟我一起围观下知名项目犯过的错,比如copy Waitgroup、Add/Wait并发执行问题、遗漏Add等Bug。
有网友在Go的issue 28123中提了以下的例子,你能发现这段代码有什么问题吗?
type TestStruct struct {
Wait sync.WaitGroup
}
func main() {
w := sync.WaitGroup{}
w.Add(1)
t := &TestStruct{
Wait: w,
}
t.Wait.Done()
fmt.Println("Finished")
}
这段代码最大的一个问题,就是第9行copy了WaitGroup的实例w。虽然这段代码能执行成功,但确实是违反了WaitGroup使用之后不要复制的规则。在项目中,我们可以通过vet工具检查出这样的错误。
Docker issue 28161 和 issue 27011 ,都是因为在重用WaitGroup的时候,没等前一次的Wait结束就Add导致的错误。Etcd issue 6534 也是重用WaitGroup的Bug,没有等前一个Wait结束就Add。
Kubernetes issue 59574 的Bug是忘记Wait之前增加计数了,这就属于我们通常认为几乎不可能出现的Bug。
即使是开发Go语言的开发者自己,在使用WaitGroup的时候,也可能会犯错。比如 issue 12813,因为defer的使用,Add方法可能在Done之后才执行,导致计数负值的panic。
学完这一讲,我们知道了使用WaitGroup容易犯的错,是不是有些手脚被束缚的感觉呢?其实大可不必,只要我们不是特别复杂地使用WaitGroup,就不用有啥心理负担。
而关于如何避免错误使用WaitGroup的情况,我们只需要尽量保证下面5点就可以了:
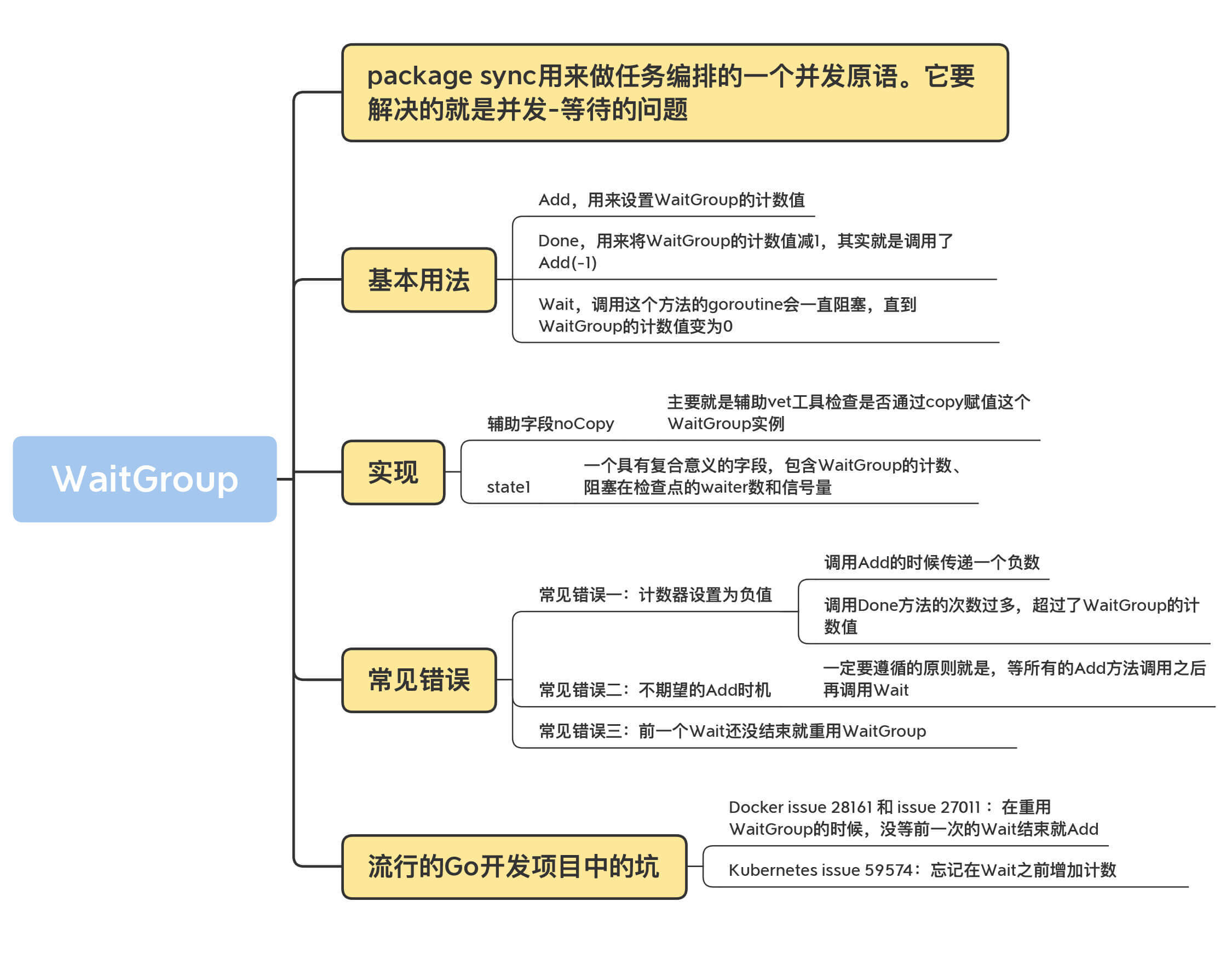
这一讲我们详细学习了WaitGroup的相关知识,这里我整理了一份关于WaitGroup的知识地图,方便你复习。
通常我们可以把WaitGroup的计数值,理解为等待要完成的waiter的数量。你可以试着扩展下WaitGroup,来查询WaitGroup的当前的计数值吗?
欢迎在留言区写下你的思考和答案,我们一起交流讨论。如果你觉得有所收获,也欢迎你把今天的内容分享给你的朋友或同事。
评论