
你好,我是鸟窝。
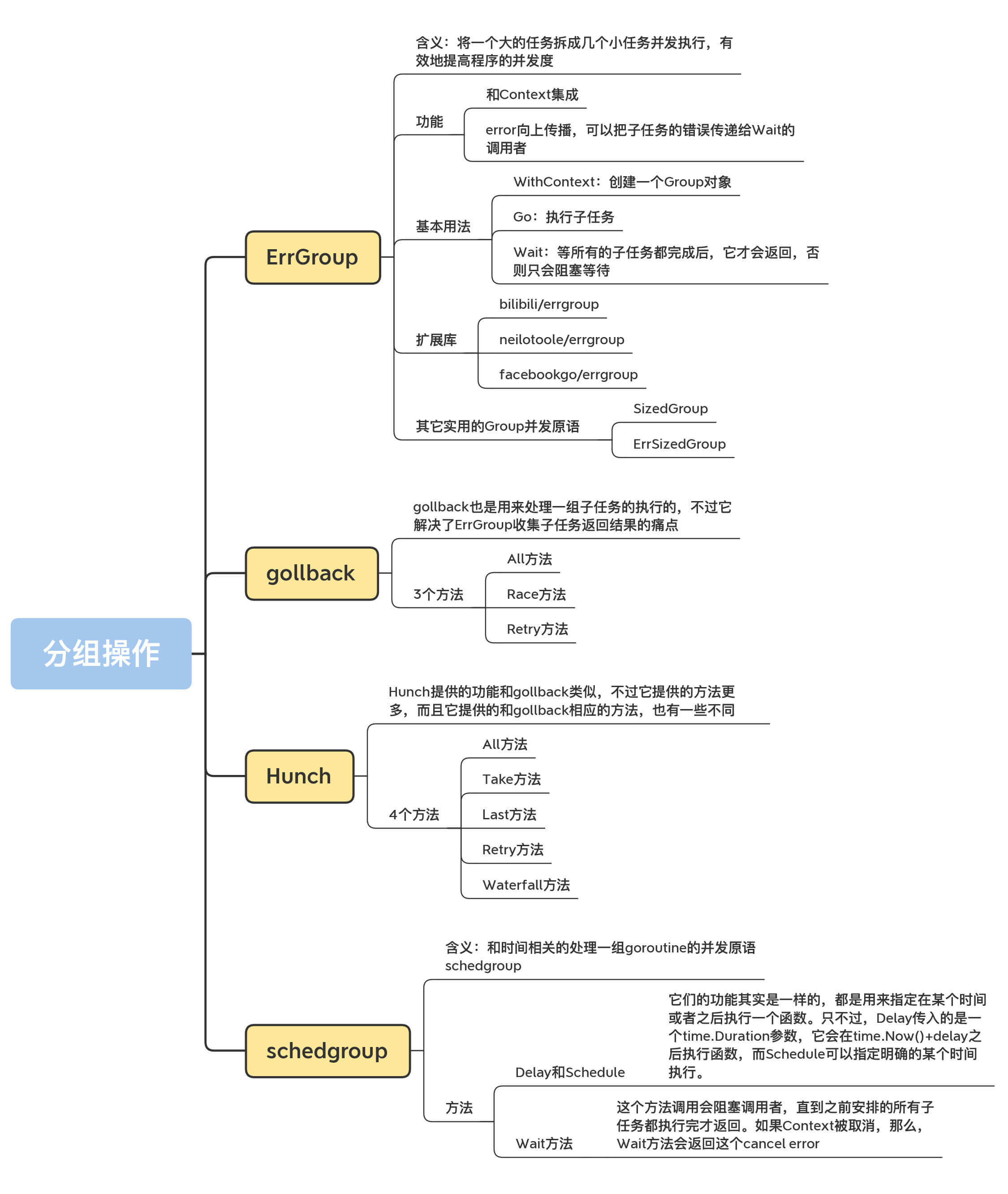
共享资源保护、任务编排和消息传递是Go并发编程中常见的场景,而分组执行一批相同的或类似的任务则是任务编排中一类情形,所以,这节课,我专门来介绍一下分组编排的一些常用场景和并发原语,包括ErrGroup、gollback、Hunch和schedgroup。
我们先来学习一类非常常用的并发原语,那就是ErrGroup。
ErrGroup是Go官方提供的一个同步扩展库。我们经常会碰到需要将一个通用的父任务拆成几个小任务并发执行的场景,其实,将一个大的任务拆成几个小任务并发执行,可以有效地提高程序的并发度。就像你在厨房做饭一样,你可以在蒸米饭的同时炒几个小菜,米饭蒸好了,菜同时也做好了,很快就能吃到可口的饭菜。
ErrGroup就是用来应对这种场景的。它和WaitGroup有些类似,但是它提供功能更加丰富:
接下来,我来给你介绍一下ErrGroup的基本用法和几种应用场景。
golang.org/x/sync/errgroup包下定义了一个Group struct,它就是我们要介绍的ErrGroup并发原语,底层也是基于WaitGroup实现的。
在使用ErrGroup时,我们要用到三个方法,分别是WithContext、Go和Wait。
1.WithContext
在创建一个Group对象时,需要使用WithContext方法:
func WithContext(ctx context.Context) (*Group, context.Context)
这个方法返回一个Group实例,同时还会返回一个使用context.WithCancel(ctx)生成的新Context。一旦有一个子任务返回错误,或者是Wait调用返回,这个新Context就会被cancel。
Group的零值也是合法的,只不过,你就没有一个可以监控是否cancel的Context了。
注意,如果传递给WithContext的ctx参数,是一个可以cancel的Context的话,那么,它被cancel的时候,并不会终止正在执行的子任务。
2.Go
我们再来学习下执行子任务的Go方法:
func (g *Group) Go(f func() error)
传入的子任务函数f是类型为func() error的函数,如果任务执行成功,就返回nil,否则就返回error,并且会cancel 那个新的Context。
一个任务可以分成好多个子任务,而且,可能有多个子任务执行失败返回error,不过,Wait方法只会返回第一个错误,所以,如果想返回所有的错误,需要特别的处理,我先留个小悬念,一会儿再讲。
3.Wait
类似WaitGroup,Group也有Wait方法,等所有的子任务都完成后,它才会返回,否则只会阻塞等待。如果有多个子任务返回错误,它只会返回第一个出现的错误,如果所有的子任务都执行成功,就返回nil:
func (g *Group) Wait() error
好了,知道了基本用法,下面我来给你介绍几个例子,帮助你全面地掌握ErrGroup的使用方法和应用场景。
先来看一个简单的例子。在这个例子中,启动了三个子任务,其中,子任务2会返回执行失败,其它两个执行成功。在三个子任务都执行后,group.Wait才会返回第2个子任务的错误。
package main
import (
"errors"
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
var g errgroup.Group
// 启动第一个子任务,它执行成功
g.Go(func() error {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
return nil
})
// 启动第二个子任务,它执行失败
g.Go(func() error {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
return errors.New("failed to exec #2")
})
// 启动第三个子任务,它执行成功
g.Go(func() error {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
return nil
})
// 等待三个任务都完成
if err := g.Wait(); err == nil {
fmt.Println("Successfully exec all")
} else {
fmt.Println("failed:", err)
}
}
如果执行下面的这个程序,会显示三个任务都执行了,而Wait返回了子任务2的错误:
Group只能返回子任务的第一个错误,后续的错误都会被丢弃。但是,有时候我们需要知道每个任务的执行情况。怎么办呢?这个时候,我们就可以用稍微有点曲折的方式去实现。我们使用一个result slice保存子任务的执行结果,这样,通过查询result,就可以知道每一个子任务的结果了。
下面的这个例子,就是使用result记录每个子任务成功或失败的结果。其实,你不仅可以使用result记录error信息,还可以用它记录计算结果。
package main
import (
"errors"
"fmt"
"time"
"golang.org/x/sync/errgroup"
)
func main() {
var g errgroup.Group
var result = make([]error, 3)
// 启动第一个子任务,它执行成功
g.Go(func() error {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
result[0] = nil // 保存成功或者失败的结果
return nil
})
// 启动第二个子任务,它执行失败
g.Go(func() error {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
result[1] = errors.New("failed to exec #2") // 保存成功或者失败的结果
return result[1]
})
// 启动第三个子任务,它执行成功
g.Go(func() error {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
result[2] = nil // 保存成功或者失败的结果
return nil
})
if err := g.Wait(); err == nil {
fmt.Printf("Successfully exec all. result: %v\n", result)
} else {
fmt.Printf("failed: %v\n", result)
}
}
Go官方文档中还提供了一个pipeline的例子。这个例子是说,由一个子任务遍历文件夹下的文件,然后把遍历出的文件交给20个goroutine,让这些goroutine并行计算文件的md5。
这个例子中的计算逻辑你不需要重点掌握,我来把这个例子简化一下(如果你想看原始的代码,可以看这里):
package main
import (
......
"golang.org/x/sync/errgroup"
)
// 一个多阶段的pipeline.使用有限的goroutine计算每个文件的md5值.
func main() {
m, err := MD5All(context.Background(), ".")
if err != nil {
log.Fatal(err)
}
for k, sum := range m {
fmt.Printf("%s:\t%x\n", k, sum)
}
}
type result struct {
path string
sum [md5.Size]byte
}
// 遍历根目录下所有的文件和子文件夹,计算它们的md5的值.
func MD5All(ctx context.Context, root string) (map[string][md5.Size]byte, error) {
g, ctx := errgroup.WithContext(ctx)
paths := make(chan string) // 文件路径channel
g.Go(func() error {
defer close(paths) // 遍历完关闭paths chan
return filepath.Walk(root, func(path string, info os.FileInfo, err error) error {
...... //将文件路径放入到paths
return nil
})
})
// 启动20个goroutine执行计算md5的任务,计算的文件由上一阶段的文件遍历子任务生成.
c := make(chan result)
const numDigesters = 20
for i := 0; i < numDigesters; i++ {
g.Go(func() error {
for path := range paths { // 遍历直到paths chan被关闭
...... // 计算path的md5值,放入到c中
}
return nil
})
}
go func() {
g.Wait() // 20个goroutine以及遍历文件的goroutine都执行完
close(c) // 关闭收集结果的chan
}()
m := make(map[string][md5.Size]byte)
for r := range c { // 将md5结果从chan中读取到map中,直到c被关闭才退出
m[r.path] = r.sum
}
// 再次调用Wait,依然可以得到group的error信息
if err := g.Wait(); err != nil {
return nil, err
}
return m, nil
}
通过这个例子,你可以学习到多阶段pipeline的实现(这个例子是遍历文件夹和计算md5两个阶段),还可以学习到如何控制执行子任务的goroutine数量。
很多公司都在使用ErrGroup处理并发子任务,比如Facebook、bilibili等公司的一些项目,但是,这些公司在使用的时候,发现了一些不方便的地方,或者说,官方的ErrGroup的功能还不够丰富。所以,他们都对ErrGroup进行了扩展。接下来呢,我就带你看看几个扩展库。
如果我们无限制地直接调用ErrGroup的Go方法,就可能会创建出非常多的goroutine,太多的goroutine会带来调度和GC的压力,而且也会占用更多的内存资源。就像go#34457指出的那样,当前Go运行时创建的g对象只会增长和重用,不会回收,所以在高并发的情况下,也要尽可能减少goroutine的使用。
常用的一个手段就是使用worker pool(goroutine pool),或者是类似containerd/stargz-snapshotter的方案,使用前面我们讲的信号量,信号量的资源的数量就是可以并行的goroutine的数量。但是在这一讲,我来介绍一些其它的手段,比如下面介绍的bilibili实现的errgroup。
bilibili实现了一个扩展的ErrGroup,可以使用一个固定数量的goroutine处理子任务。如果不设置goroutine的数量,那么每个子任务都会比较“放肆地”创建一个goroutine并发执行。
这个链接里的文档已经很详细地介绍了它的几个扩展功能,所以我就不通过示例的方式来进行讲解了。
除了可以控制并发goroutine的数量,它还提供了2个功能:
但是,有一点不太好的地方就是,一旦你设置了并发数,超过并发数的子任务需要等到调用者调用Wait之后才会执行,而不是只要goroutine空闲下来,就去执行。如果不注意这一点的话,可能会出现子任务不能及时处理的情况,这是这个库可以优化的一点。
另外,这个库其实是有一个并发问题的。在高并发的情况下,如果任务数大于设定的goroutine的数量,并且这些任务被集中加入到Group中,这个库的处理方式是把子任务加入到一个数组中,但是,这个数组不是线程安全的,有并发问题,问题就在于,下面图片中的标记为96行的那一行,这一行对slice的append操作不是线程安全的:
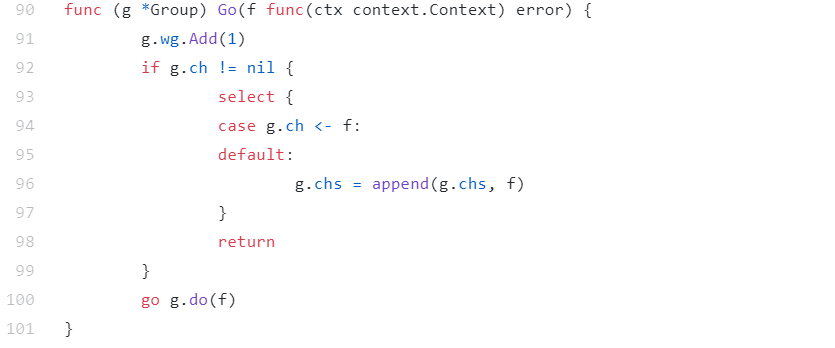
我们可以写一个简单的程序来测试这个问题:
package main
import (
"context"
"fmt"
"sync/atomic"
"time"
"github.com/bilibili/kratos/pkg/sync/errgroup"
)
func main() {
var g errgroup.Group
g.GOMAXPROCS(1) // 只使用一个goroutine处理子任务
var count int64
g.Go(func(ctx context.Context) error {
time.Sleep(time.Second) //睡眠5秒,把这个goroutine占住
return nil
})
total := 10000
for i := 0; i < total; i++ { // 并发一万个goroutine执行子任务,理论上这些子任务都会加入到Group的待处理列表中
go func() {
g.Go(func(ctx context.Context) error {
atomic.AddInt64(&count, 1)
return nil
})
}()
}
// 等待所有的子任务完成。理论上10001个子任务都会被完成
if err := g.Wait(); err != nil {
panic(err)
}
got := atomic.LoadInt64(&count)
if got != int64(total) {
panic(fmt.Sprintf("expect %d but got %d", total, got))
}
}
运行这个程序的话,你就会发现死锁问题,因为我们的测试程序是一个简单的命令行工具,程序退出的时候,Go runtime能检测到死锁问题。如果是一直运行的服务器程序,死锁问题有可能是检测不出来的,程序一直会hang在Wait的调用上。
neilotoole/errgroup是今年年中新出现的一个ErrGroup扩展库,它可以直接替换官方的ErrGroup,方法都一样,原有功能也一样,只不过增加了可以控制并发goroutine的功能。它的方法集如下:
type Group
func WithContext(ctx context.Context) (*Group, context.Context)
func WithContextN(ctx context.Context, numG, qSize int) (*Group, context.Context)
func (g *Group) Go(f func() error)
func (g *Group) Wait() error
新增加的方法WithContextN,可以设置并发的goroutine数,以及等待处理的子任务队列的大小。当队列满的时候,如果调用Go方法,就会被阻塞,直到子任务可以放入到队列中才返回。如果你传给这两个参数的值不是正整数,它就会使用runtime.NumCPU代替你传入的参数。
当然,你也可以把bilibili的recover功能扩展到这个库中,以避免子任务的panic导致程序崩溃。
Facebook提供的这个ErrGroup,其实并不是对Go扩展库ErrGroup的扩展,而是对标准库WaitGroup的扩展。不过,因为它们的名字一样,处理的场景也类似,所以我把它也列在了这里。
标准库的WaitGroup只提供了Add、Done、Wait方法,而且Wait方法也没有返回子goroutine的error。而Facebook提供的ErrGroup提供的Wait方法可以返回error,而且可以包含多个error。子任务在调用Done之前,可以把自己的error信息设置给ErrGroup。接着,Wait在返回的时候,就会把这些error信息返回给调用者。
我们来看下Group的方法:
type Group
func (g *Group) Add(delta int)
func (g *Group) Done()
func (g *Group) Error(e error)
func (g *Group) Wait() error
关于Wait方法,我刚刚已经介绍了它和标准库WaitGroup的不同,我就不多说了。这里还有一个不同的方法,就是Error方法,
我举个例子演示一下Error的使用方法。
在下面的这个例子中,第26行的子goroutine设置了error信息,第39行会把这个error信息输出出来。
package main
import (
"errors"
"fmt"
"time"
"github.com/facebookgo/errgroup"
)
func main() {
var g errgroup.Group
g.Add(3)
// 启动第一个子任务,它执行成功
go func() {
time.Sleep(5 * time.Second)
fmt.Println("exec #1")
g.Done()
}()
// 启动第二个子任务,它执行失败
go func() {
time.Sleep(10 * time.Second)
fmt.Println("exec #2")
g.Error(errors.New("failed to exec #2"))
g.Done()
}()
// 启动第三个子任务,它执行成功
go func() {
time.Sleep(15 * time.Second)
fmt.Println("exec #3")
g.Done()
}()
// 等待所有的goroutine完成,并检查error
if err := g.Wait(); err == nil {
fmt.Println("Successfully exec all")
} else {
fmt.Println("failed:", err)
}
}
关于ErrGroup,你掌握这些就足够了,接下来,我再介绍几种有趣而实用的Group并发原语。这些并发原语都是控制一组子goroutine执行的面向特定场景的并发原语,当你遇见这些特定场景时,就可以参考这些库。
go-pkgz/syncs提供了两个Group并发原语,分别是SizedGroup和ErrSizedGroup。
SizedGroup内部是使用信号量和WaitGroup实现的,它通过信号量控制并发的goroutine数量,或者是不控制goroutine数量,只控制子任务并发执行时候的数量(通过)。
它的代码实现非常简洁,你可以到它的代码库中了解它的具体实现,你一看就明白了,我就不多说了。下面我重点说说它的功能。
默认情况下,SizedGroup控制的是子任务的并发数量,而不是goroutine的数量。在这种方式下,每次调用Go方法都不会被阻塞,而是新建一个goroutine去执行。
如果想控制goroutine的数量,你可以使用syncs.Preemptive设置这个并发原语的可选项。如果设置了这个可选项,但在调用Go方法的时候没有可用的goroutine,那么调用者就会等待,直到有goroutine可以处理这个子任务才返回,这个控制在内部是使用信号量实现的。
我们来看一个使用SizedGroup的例子:
package main
import (
"context"
"fmt"
"sync/atomic"
"time"
"github.com/go-pkgz/syncs"
)
func main() {
// 设置goroutine数是10
swg := syncs.NewSizedGroup(10)
// swg := syncs.NewSizedGroup(10, syncs.Preemptive)
var c uint32
// 执行1000个子任务,只会有10个goroutine去执行
for i := 0; i < 1000; i++ {
swg.Go(func(ctx context.Context) {
time.Sleep(5 * time.Millisecond)
atomic.AddUint32(&c, 1)
})
}
// 等待任务完成
swg.Wait()
// 输出结果
fmt.Println(c)
}
ErrSizedGroup为SizedGroup提供了error处理的功能,它的功能和Go官方扩展库的功能一样,就是等待子任务完成并返回第一个出现的error。不过,它还提供了额外的功能,我来介绍一下。
第一个额外的功能,就是可以控制并发的goroutine数量,这和SizedGroup的功能一样。
第二个功能是,如果设置了termOnError,子任务出现第一个错误的时候会cancel Context,而且后续的Go调用会直接返回,Wait调用者会得到这个错误,这相当于是遇到错误快速返回。如果没有设置termOnError,Wait会返回所有的子任务的错误。
不过,ErrSizedGroup和SizedGroup设计得不太一致的地方是,SizedGroup可以把Context传递给子任务,这样可以通过cancel让子任务中断执行,但是ErrSizedGroup却没有实现。我认为,这是一个值得加强的地方。
总体来说,syncs包提供的并发原语的质量和功能还是非常赞的。不过,目前的star只有十几个,这和它的功能严重不匹配,我建议你star这个项目,支持一下作者。
好了,关于ErrGroup,你掌握这些就足够了,下面我再来给你介绍一些非ErrGroup的并发原语,它们用来编排子任务。
gollback也是用来处理一组子任务的执行的,不过它解决了ErrGroup收集子任务返回结果的痛点。使用ErrGroup时,如果你要收到子任务的结果和错误,你需要定义额外的变量收集执行结果和错误,但是这个库可以提供更便利的方式。
我刚刚在说官方扩展库ErrGroup的时候,举了一些例子(返回第一个错误的例子和返回所有子任务错误的例子),在例子中,如果想得到每一个子任务的结果或者error,我们需要额外提供一个result slice进行收集。使用gollback的话,就不需要这些额外的处理了,因为它的方法会把结果和error信息都返回。
接下来,我们看一下它提供的三个方法,分别是All、Race和Retry。
All方法
All方法的签名如下:
func All(ctx context.Context, fns ...AsyncFunc) ([]interface{}, []error)
它会等待所有的异步函数(AsyncFunc)都执行完才返回,而且返回结果的顺序和传入的函数的顺序保持一致。第一个返回参数是子任务的执行结果,第二个参数是子任务执行时的错误信息。
其中,异步函数的定义如下:
type AsyncFunc func(ctx context.Context) (interface{}, error)
可以看到,ctx会被传递给子任务。如果你cancel这个ctx,可以取消子任务。
我们来看一个使用All方法的例子:
package main
import (
"context"
"errors"
"fmt"
"github.com/vardius/gollback"
"time"
)
func main() {
rs, errs := gollback.All( // 调用All方法
context.Background(),
func(ctx context.Context) (interface{}, error) {
time.Sleep(3 * time.Second)
return 1, nil // 第一个任务没有错误,返回1
},
func(ctx context.Context) (interface{}, error) {
return nil, errors.New("failed") // 第二个任务返回一个错误
},
func(ctx context.Context) (interface{}, error) {
return 3, nil // 第三个任务没有错误,返回3
},
)
fmt.Println(rs) // 输出子任务的结果
fmt.Println(errs) // 输出子任务的错误信息
}
Race方法
Race方法跟All方法类似,只不过,在使用Race方法的时候,只要一个异步函数执行没有错误,就立马返回,而不会返回所有的子任务信息。如果所有的子任务都没有成功,就会返回最后一个error信息。
Race方法签名如下:
func Race(ctx context.Context, fns ...AsyncFunc) (interface{}, error)
如果有一个正常的子任务的结果返回,Race会把传入到其它子任务的Context cancel掉,这样子任务就可以中断自己的执行。
Race的使用方法也跟All方法类似,我就不再举例子了,你可以把All方法的例子中的All替换成Race方式测试下。
Retry方法
Retry不是执行一组子任务,而是执行一个子任务。如果子任务执行失败,它会尝试一定的次数,如果一直不成功 ,就会返回失败错误 ,如果执行成功,它会立即返回。如果retires等于0,它会永远尝试,直到成功。
func Retry(ctx context.Context, retires int, fn AsyncFunc) (interface{}, error)
再来看一个使用Retry的例子:
package main
import (
"context"
"errors"
"fmt"
"github.com/vardius/gollback"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// 尝试5次,或者超时返回
res, err := gollback.Retry(ctx, 5, func(ctx context.Context) (interface{}, error) {
return nil, errors.New("failed")
})
fmt.Println(res) // 输出结果
fmt.Println(err) // 输出错误信息
}
Hunch提供的功能和gollback类似,不过它提供的方法更多,而且它提供的和gollback相应的方法,也有一些不同。我来一一介绍下。
它定义了执行子任务的函数,这和gollback的AyncFunc是一样的,它的定义如下:
type Executable func(context.Context) (interface{}, error)
All方法
All方法的签名如下:
func All(parentCtx context.Context, execs ...Executable) ([]interface{}, error)
它会传入一组可执行的函数(子任务),返回子任务的执行结果。和gollback的All方法不一样的是,一旦一个子任务出现错误,它就会返回错误信息,执行结果(第一个返回参数)为nil。
Take方法
Take方法的签名如下:
func Take(parentCtx context.Context, num int, execs ...Executable) ([]interface{}, error)
你可以指定num参数,只要有num个子任务正常执行完没有错误,这个方法就会返回这几个子任务的结果。一旦一个子任务出现错误,它就会返回错误信息,执行结果(第一个返回参数)为nil。
Last方法
Last方法的签名如下:
func Last(parentCtx context.Context, num int, execs ...Executable) ([]interface{}, error)
它只返回最后num个正常执行的、没有错误的子任务的结果。一旦一个子任务出现错误,它就会返回错误信息,执行结果(第一个返回参数)为nil。
比如num等于1,那么,它只会返回最后一个无错的子任务的结果。
Retry方法
Retry方法的签名如下:
func Retry(parentCtx context.Context, retries int, fn Executable) (interface{}, error)
它的功能和gollback的Retry方法的功能一样,如果子任务执行出错,就会不断尝试,直到成功或者是达到重试上限。如果达到重试上限,就会返回错误。如果retries等于0,它会不断尝试。
Waterfall方法
Waterfall方法签名如下:
func Waterfall(parentCtx context.Context, execs ...ExecutableInSequence) (interface{}, error)
它其实是一个pipeline的处理方式,所有的子任务都是串行执行的,前一个子任务的执行结果会被当作参数传给下一个子任务,直到所有的任务都完成,返回最后的执行结果。一旦一个子任务出现错误,它就会返回错误信息,执行结果(第一个返回参数)为nil。
gollback和Hunch是属于同一类的并发原语,对一组子任务的执行结果,可以选择一个结果或者多个结果,这也是现在热门的微服务常用的服务治理的方法。
接下来,我再介绍一个和时间相关的处理一组goroutine的并发原语schedgroup。
schedgroup是Matt Layher开发的worker pool,可以指定任务在某个时间或者某个时间之后执行。Matt Layher也是一个知名的Gopher,经常在一些会议上分享一些他的Go开发经验,他在GopherCon Europe 2020大会上专门介绍了这个并发原语:schedgroup: a timer-based goroutine concurrency primitive ,课下你可以点开这个链接看一下,下面我来给你介绍一些重点。
这个并发原语包含的方法如下:
type Group
func New(ctx context.Context) *Group
func (g *Group) Delay(delay time.Duration, fn func())
func (g *Group) Schedule(when time.Time, fn func())
func (g *Group) Wait() error
我来介绍下这些方法。
先说Delay和Schedule。
它们的功能其实是一样的,都是用来指定在某个时间或者之后执行一个函数。只不过,Delay传入的是一个time.Duration参数,它会在time.Now()+delay之后执行函数,而Schedule可以指定明确的某个时间执行。
再来说说Wait方法。
这个方法调用会阻塞调用者,直到之前安排的所有子任务都执行完才返回。如果Context被取消,那么,Wait方法会返回这个cancel error。
在使用Wait方法的时候,有2点需要注意一下。
第一点是,如果调用了Wait方法,你就不能再调用它的Delay和Schedule方法,否则会panic。
第二点是,Wait方法只能调用一次,如果多次调用的话,就会panic。
你可能认为,简单地使用timer就可以实现这个功能。其实,如果只有几个子任务,使用timer不是问题,但一旦有大量的子任务,而且还要能够cancel,那么,使用timer的话,CPU资源消耗就比较大了。所以,schedgroup在实现的时候,就使用container/heap,按照子任务的执行时间进行排序,这样可以避免使用大量的timer,从而提高性能。
我们来看一个使用schedgroup的例子,下面代码会依次输出1、2、3:
sg := schedgroup.New(context.Background())
// 设置子任务分别在100、200、300之后执行
for i := 0; i < 3; i++ {
n := i + 1
sg.Delay(time.Duration(n)*100*time.Millisecond, func() {
log.Println(n) //输出任务编号
})
}
// 等待所有的子任务都完成
if err := sg.Wait(); err != nil {
log.Fatalf("failed to wait: %v", err)
}
这节课,我给你介绍了几种常见的处理一组子任务的并发原语,包括ErrGroup、gollback、Hunch、schedgroup,等等。这些常见的业务场景共性处理方式的总结,你可以把它们加入到你的知识库中,等以后遇到相同的业务场景时,你就可以考虑使用这些并发原语。
当然,类似的并发原语还有别的,比如go-waitgroup等,而且,我相信还会有新的并发原语不断出现。所以,你不仅仅要掌握这些并发原语,而且还要通过学习这些并发原语,学会构造新的并发原语来处理应对你的特有场景,实现代码重用和业务逻辑简化。
这节课,我讲的官方扩展库ErrGroup没有实现可以取消子任务的功能,请你课下可以自己去实现一个子任务可取消的ErrGroup。
欢迎在留言区写下你的思考和答案,我们一起交流讨论。如果你觉得有所收获,也欢迎你把今天的内容分享给你的朋友或同事。
评论