
你好,我是刘超。
本周我们结束了“JVM性能监测及调优”的学习,这一期答疑课堂我精选了模块四中 11 位同学的留言,进行集中解答,希望也能对你有所帮助。另外,我想为坚持跟到现在的同学点个赞,期待我们能有更多的技术交流,共同成长。
很多同学都问到了类似“黑夜里的猫"问到的问题,所以我来集中回复一下。JVM的内存模型只是一个规范,方法区也是一个规范,一个逻辑分区,并不是一个物理空间,我们这里说的字符串常量放在堆内存空间中,是指实际的物理空间。

文灏的问题和上一个类似,一同回复一下。元空间是属于方法区的,方法区只是一个逻辑分区,而元空间是具体实现。所以类的元数据是存放在元空间,逻辑上属于方法区。

Liam同学,目前Hotspot虚拟机暂时不支持栈上分配对象。W.LI同学的留言值得参考,所以这里一同贴出来了。


非常赞,Region这块,Jxin同学讲解得很到位。这里我再总结下CMS和G1的一些知识点。
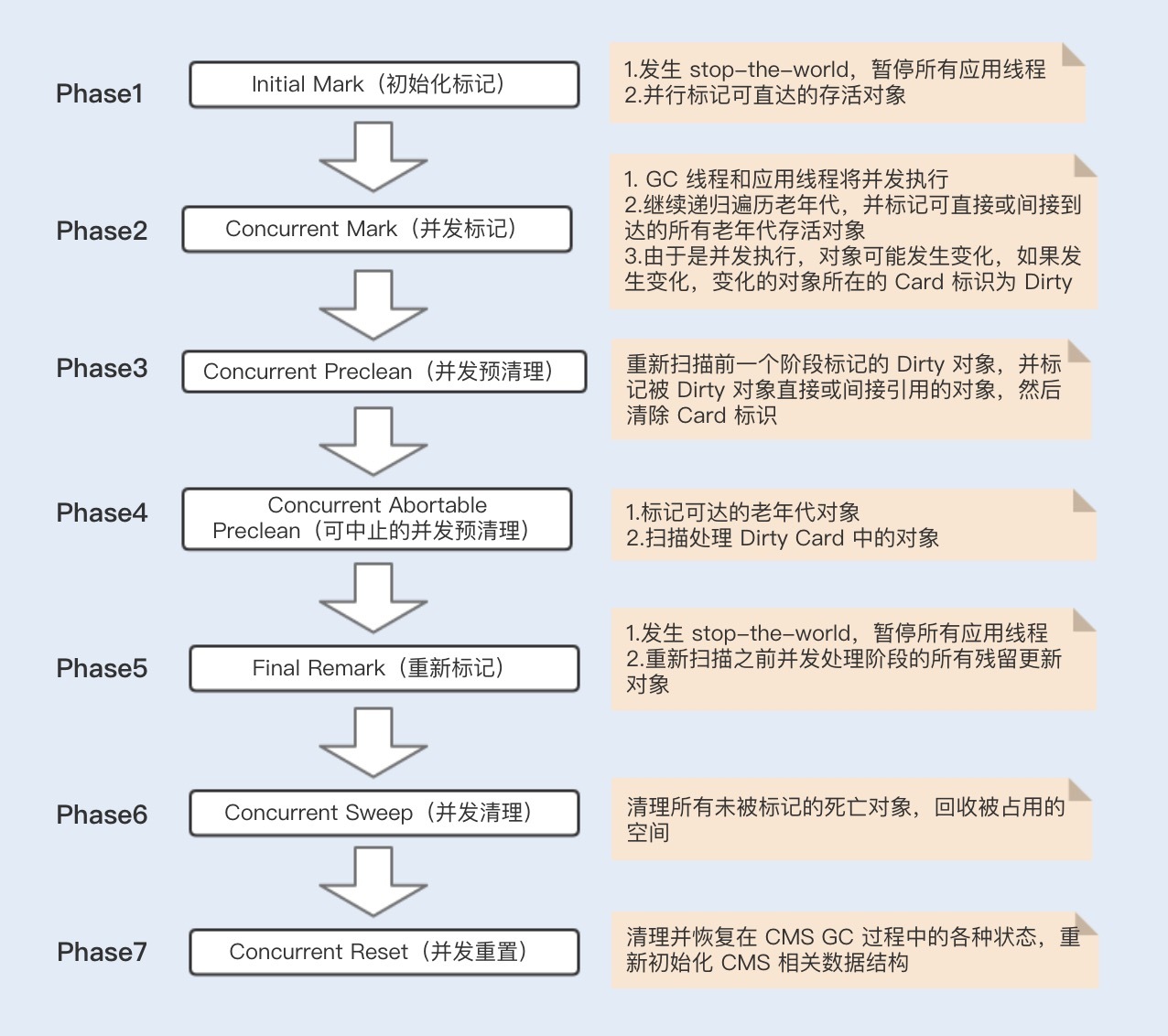
CMS垃圾收集器是基于标记清除算法实现的,目前主要用于老年代垃圾回收。CMS收集器的GC周期主要由7个阶段组成,其中有两个阶段会发生stop-the-world,其它阶段都是并发执行的。
G1垃圾收集器是基于标记整理算法实现的,是一个分代垃圾收集器,既负责年轻代,也负责老年代的垃圾回收。
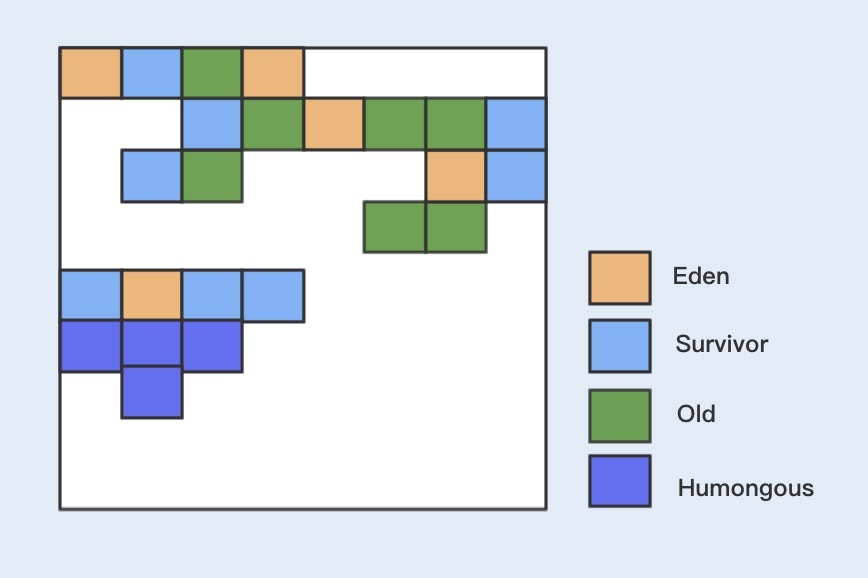
跟之前各个分代使用连续的虚拟内存地址不一样,G1使用了一种 Region 方式对堆内存进行了划分,同样也分年轻代、老年代,但每一代使用的是N个不连续的Region内存块,每个Region占用一块连续的虚拟内存地址。
在G1中,还有一种叫 Humongous 区域,用于存储特别大的对象。G1内部做了一个优化,一旦发现没有引用指向巨型对象,则可直接在年轻代的YoungGC中被回收掉。
G1分为Young GC、Mix GC以及Full GC。
G1 Young GC主要是在Eden区进行,当Eden区空间不足时,则会触发一次Young GC。将Eden区数据移到Survivor空间时,如果Survivor空间不足,则会直接晋升到老年代。此时Survivor的数据也会晋升到老年代。Young GC的执行是并行的,期间会发生STW。
当堆空间的占用率达到一定阈值后会触发G1 Mix GC(阈值由命令参数-XX:InitiatingHeapOccupancyPercent设定,默认值45),Mix GC主要包括了四个阶段,其中只有并发标记阶段不会发生STW,其它阶段均会发生STW。
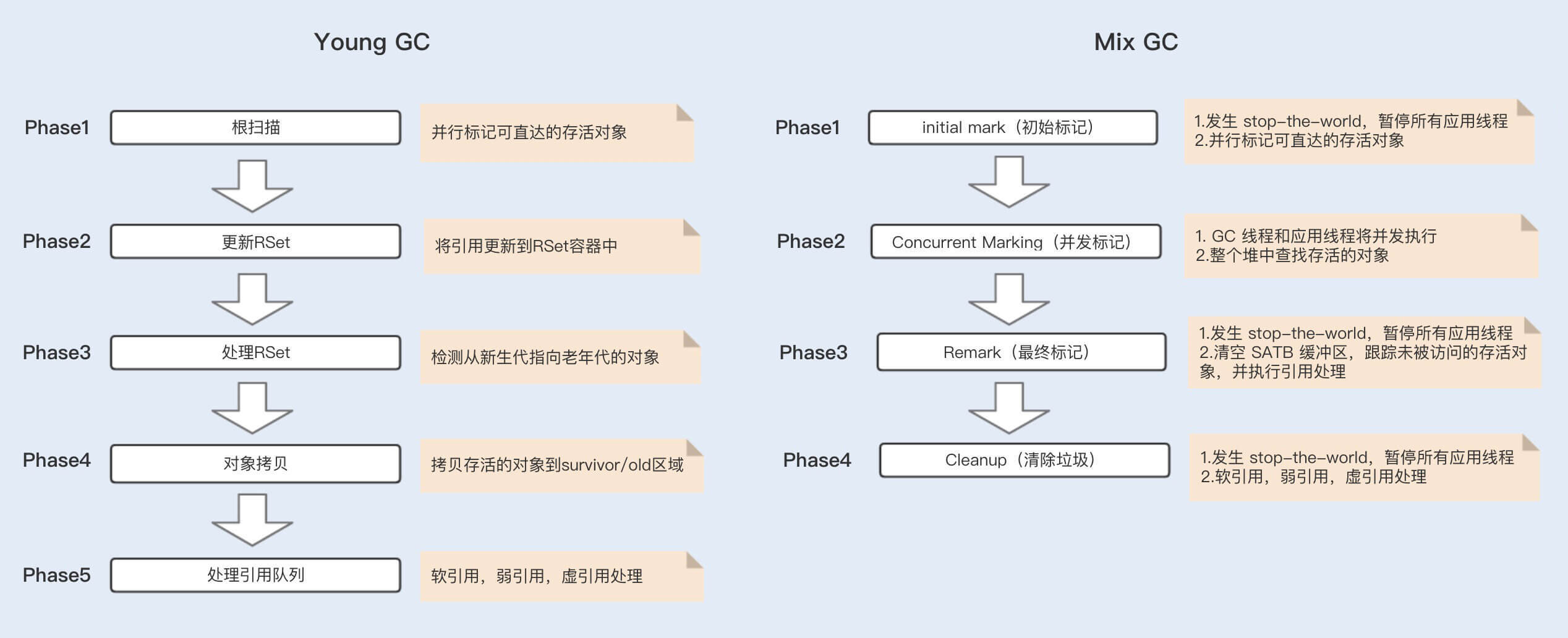
G1和CMS主要的区别在于:
这里我简单解释下Card Table,在垃圾回收的时候都是从Root开始搜索,这会先经过年轻代再到老年代,也有可能老年代引用到年轻代对象,如果发生Young GC,除了从年轻代扫描根对象之外,还需要再从老年代扫描根对象,确认引用年轻代对象的情况。
这种属于跨代处理,非常消耗性能。为了避免在回收年轻代时跨代扫描整个老年代,CMS和G1都用到了Card Table来记录这些引用关系。只是G1在Card Table的基础上引入了RSet,每个Region初始化时,都会初始化一个RSet,RSet记录了其它Region中的对象引用本Region对象的关系。
除此之外,CMS和G1在解决并发标记时漏标的方式也不一样,CMS使用的是Incremental Update算法,而G1使用的是SATB算法。
首先,我们要了解在并发标记中,G1和CMS都是基于三色标记算法来实现的:
基于这种标记有一个漏标的问题,也就是说,当一个白色标记对象,在垃圾回收被清理掉时,正好有一个对象引用了该白色标记对象,此时由于被回收掉了,就会出现对象丢失的问题。
为了避免上述问题,CMS采用了Incremental Update算法,只要在写屏障(write barrier)里发现一个白对象的引用被赋值到一个黑对象的字段里,那就把这个白对象变成灰色的。而在G1中,采用的是SATB算法,该算法认为开始时所有能遍历到的对象都是需要标记的,即认为都是活的。
G1具备Pause Prediction Model ,即停顿预测模型。用户可以设定整个GC过程中期望的停顿时间,用参数-XX:MaxGCPauseMillis可以指定一个G1收集过程的目标停顿时间,默认值200ms。
G1会根据这个模型统计出来的历史数据,来预测一次垃圾回收所需要的Region数量,通过控制Region数来控制目标停顿时间的实现。

Liam提出的这两个问题都非常好。
不管什么GC,都会发送stop-the-world,区别是发生的时间长短。而这个时间跟垃圾收集器又有关系,Serial、PartNew、Parallel Scavenge收集器无论是串行还是并行,都会挂起用户线程,而CMS和G1在并发标记时,是不会挂起用户线程的,但其它时候一样会挂起用户线程,stop the world 的时间相对来说就小很多了。
Major Gc 在很多参考资料中是等价于 Full GC的,我们也可以发现很多性能监测工具中只有Minor GC 和 Full GC。一般情况下,一次Full GC将会对年轻代、老年代、元空间以及堆外内存进行垃圾回收。触发Full GC的原因有很多:

接下来解答 ninghtmare 的提问。我们可以通过 jstat -gc pid interval 查看每次GC之后,具体每一个分区的内存使用率变化情况。我们可以通过JVM的设置参数,来查看垃圾收集器的具体设置参数,使用的方式有很多,例如 jcmd pid VM.flags 就可以查看到相关的设置参数。

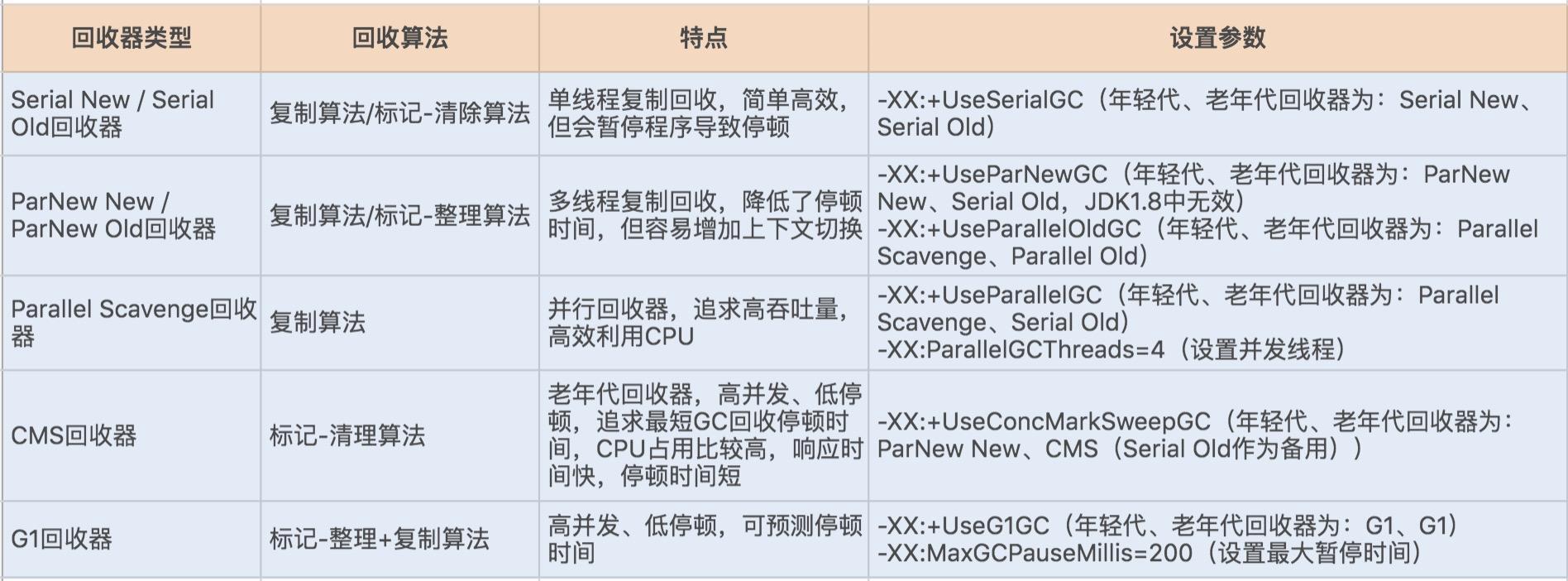
这里附上第22讲中,我总结的各个设置参数对应的垃圾收集器图表。

我又不乱来同学的留言真是没有乱来,细节掌握得很好!
前提是老年代有足够接受这些对象的空间,才会进行分配担保。如果老年代剩余空间小于每次Minor GC晋升到老年代的平均值,则会发起一次 Full GC。

看到这里,我发现爱提问的同学始终爱提问,非常鼓励啊,技术是需要交流的,也欢迎你有任何疑问,随时留言给我,我会知无不尽。
现在回答W.LI同学的问题。这个会根据我们创建对象占用的内存使用率,合理分配内存,并不仅仅考虑对象晋升的问题,还会综合考虑回收停顿时间等因素。针对某些特殊场景,我们可以手动来调优配置。

下面解答Geek_75b4cd同学的问题。
我们知道,ThreadLocal是基于ThreadLocalMap实现的,这个Map的Entry继承了WeakReference,而Entry对象中的key使用了WeakReference封装,也就是说Entry中的key是一个弱引用类型,而弱引用类型只能存活在下次GC之前。
如果一个线程调用ThreadLocal的set设置变量,当前ThreadLocalMap则会新增一条记录,但由于发生了一次垃圾回收,此时的key值就会被回收,而value值依然存在内存中,由于当前线程一直存在,所以value值将一直被引用。.
这些被垃圾回收掉的key就会一直存在一条引用链的关系:Thread --> ThreadLocalMap–>Entry–>Value。这条引用链会导致Entry不会被回收,Value也不会被回收,但Entry中的key却已经被回收的情况发生,从而造成内存泄漏。
我们只需要在使用完该key值之后,将value值通过remove方法remove掉,就可以防止内存泄漏了。

最后一个问题来自于WL同学。
内存泄漏是指不再使用的对象无法得到及时的回收,持续占用内存空间,从而造成内存空间的浪费。例如,我在第03讲中说到的,Java6中substring方法就可能会导致内存泄漏。
当调用substring方法时会调用new string构造函数,此时会复用原来字符串的char数组,而如果我们仅仅是用substring获取一小段字符,而在原本string字符串非常大的情况下,substring的对象如果一直被引用,由于substring里的char数组仍然指向原字符串,此时string字符串也无法回收,从而导致内存泄露。
内存溢出则是发生了OutOfMemoryException,内存溢出的情况有很多,例如堆内存空间不足,栈空间不足,还有方法区空间不足等都会导致内存溢出。
内存泄漏与内存溢出的关系:内存泄漏很容易导致内存溢出,但内存溢出不一定是内存泄漏导致的。
今天的答疑就到这里,如果你还有其它问题,请在留言区中提出,我会一一解答。最后欢迎你点击“请朋友读”,把今天的内容分享给身边的朋友,邀请他加入讨论。
评论