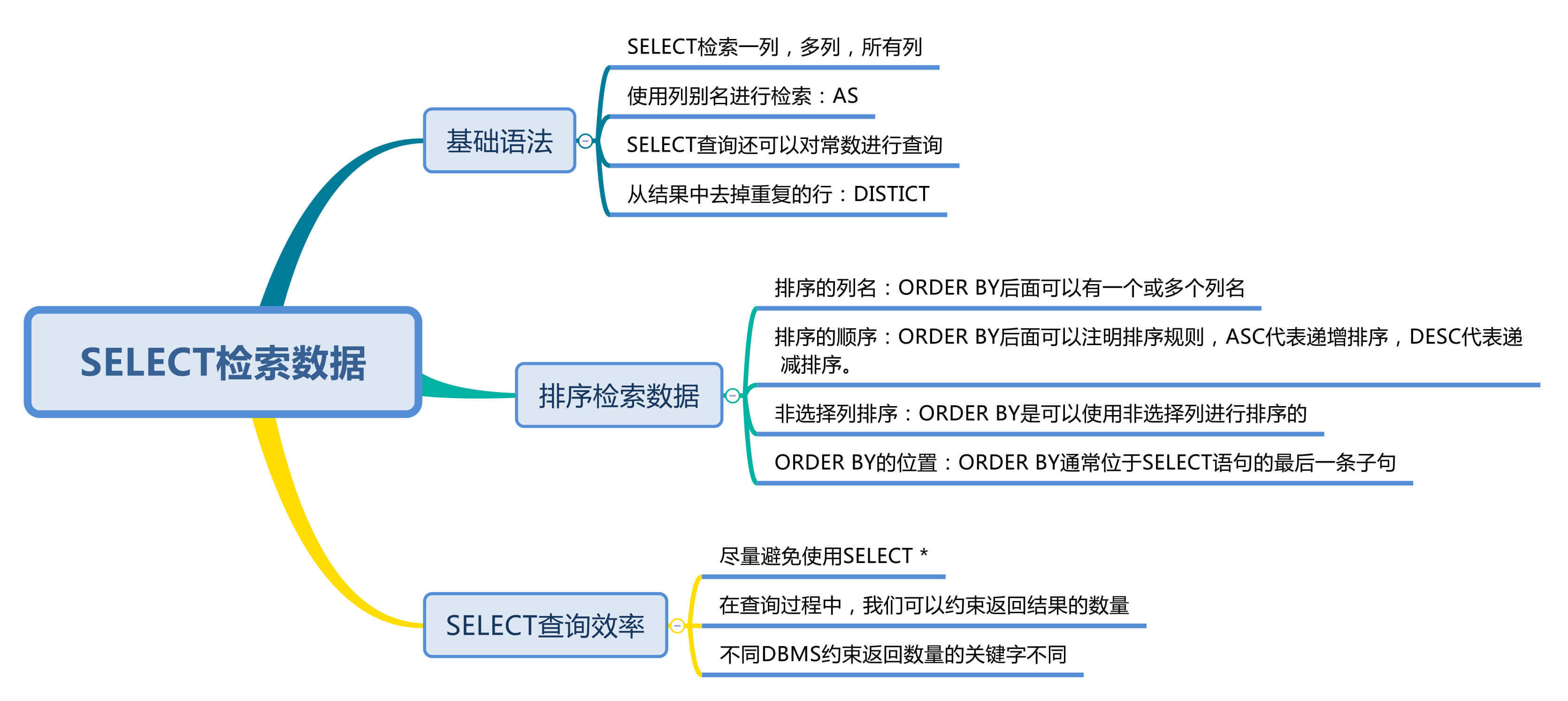
今天我们主要学习如何使用SQL检索数据。如果你已经有了一定的SQL基础,这节课可以跳过,也可以把它当做是个快速的复习。
SELECT可以说是SQL中最常用的语句了。你可以把SQL语句看作是英语语句,SELECT就是SQL中的关键字之一,除了SELECT之外,还有INSERT、DELETE、UPDATE等关键字,这些关键字是SQL的保留字,这样可以很方便地帮助我们分析理解SQL语句。我们在定义数据库表名、字段名和变量名时,要尽量避免使用这些保留字。
SELECT的作用是从一个表或多个表中检索出想要的数据行。今天我主要讲解SELECT的基础查询,后面我会讲解如何通过多个表的连接操作进行复杂的查询。
在这篇文章中,你需要重点掌握以下几方面的内容:
SELECT*,如何提升SELECT查询效率?SELECT可以帮助我们从一个表或多个表中进行数据查询。我们知道一个数据表是由列(字段名)和行(数据行)组成的,我们要返回满足条件的数据行,就需要在SELECT后面加上我们想要查询的列名,可以是一列,也可以是多个列。如果你不知道所有列名都有什么,也可以检索所有列。
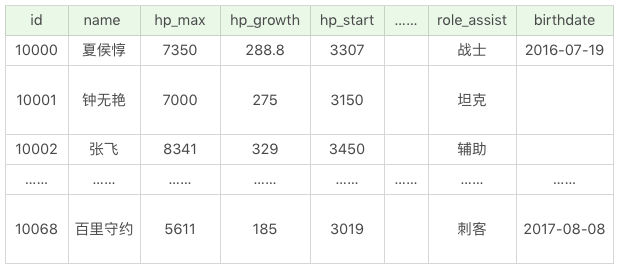
我创建了一个王者荣耀英雄数据表,这张表里一共有69个英雄,23个属性值(不包括英雄名name)。SQL文件见Github地址。
数据表中这24个字段(除了id以外),分别代表的含义见下图。
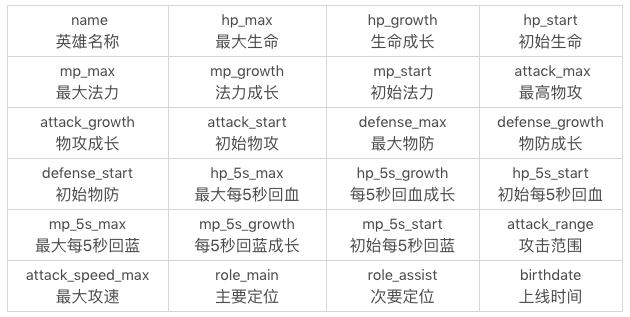
如果我们想要对数据表中的某一列进行检索,在SELECT后面加上这个列的字段名即可。比如我们想要检索数据表中都有哪些英雄。
SQL:SELECT name FROM heros
运行结果(69条记录)见下图,你可以看到这样就等于单独输出了name这一列。
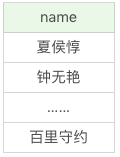
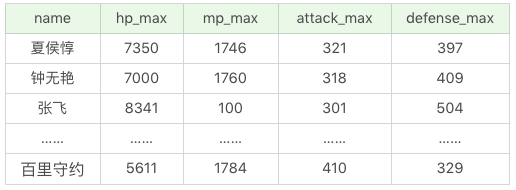
我们也可以对多个列进行检索,在列名之间用逗号(,)分割即可。比如我们想要检索有哪些英雄,他们的最大生命、最大法力、最大物攻和最大物防分别是多少。
SQL:SELECT name, hp_max, mp_max, attack_max, defense_max FROM heros
运行结果(69条记录):
这个表中一共有25个字段,除了id和英雄名name以外,还存在23个属性值,如果我们记不住所有的字段名称,可以使用SELECT * 帮我们检索出所有的列:
SQL:SELECT * FROM heros
运行结果(69条记录):
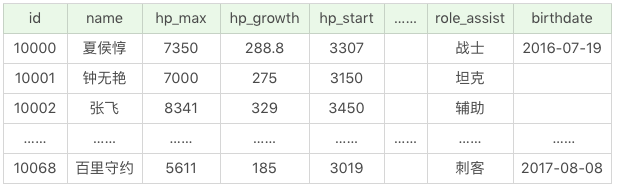
我们在做数据探索的时候,SELECT *还是很有用的,这样我们就不需要写很长的SELECT语句了。但是在生产环境时要尽量避免使用SELECT*,具体原因我会在后面讲。
我们在使用SELECT查询的时候,还有一些技巧可以使用,比如你可以给列名起别名。我们在进行检索的时候,可以给英雄名、最大生命、最大法力、最大物攻和最大物防等取别名:
SQL:SELECT name AS n, hp_max AS hm, mp_max AS mm, attack_max AS am, defense_max AS dm FROM heros
运行结果和上面多列检索的运行结果是一样的,只是将列名改成了n、hm、mm、am和dm。当然这里的列别名只是举例,一般来说起别名的作用是对原有名称进行简化,从而让SQL语句看起来更精简。同样我们也可以对表名称起别名,这个在多表连接查询的时候会用到。
SELECT查询还可以对常数进行查询。对的,就是在SELECT查询结果中增加一列固定的常数列。这列的取值是我们指定的,而不是从数据表中动态取出的。你可能会问为什么我们还要对常数进行查询呢?SQL中的SELECT语法的确提供了这个功能,一般来说我们只从一个表中查询数据,通常不需要增加一个固定的常数列,但如果我们想整合不同的数据源,用常数列作为这个表的标记,就需要查询常数。
比如说,我们想对heros数据表中的英雄名进行查询,同时增加一列字段platform,这个字段固定值为“王者荣耀”,可以这样写:
SQL:SELECT '王者荣耀' as platform, name FROM heros
运行结果:(69条记录)
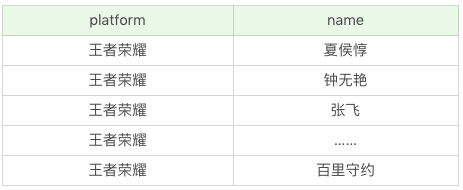
在这个SQL语句中,我们虚构了一个platform字段,并且把它设置为固定值“王者荣耀”。
需要说明的是,如果常数是个字符串,那么使用单引号(‘’)就非常重要了,比如‘王者荣耀’。单引号说明引号中的字符串是个常数,否则SQL会把王者荣耀当成列名进行查询,但实际上数据表里没有这个列名,就会引起错误。如果常数是英文字母,比如'WZRY'也需要加引号。如果常数是个数字,就可以直接写数字,不需要单引号,比如:
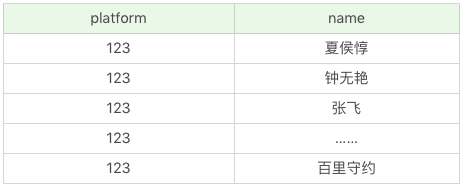
SQL:SELECT 123 as platform, name FROM heros
运行结果:(69条记录)
关于单个表的SELECT查询,还有一个非常实用的操作,就是从结果中去掉重复的行。使用的关键字是DISTINCT。比如我们想要看下heros表中关于攻击范围的取值都有哪些:
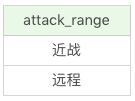
SQL:SELECT DISTINCT attack_range FROM heros
这是运行结果(2条记录),这样我们就能直观地看到攻击范围其实只有两个值,那就是近战和远程。
如果我们带上英雄名称,会是怎样呢:
SQL:SELECT DISTINCT attack_range, name FROM heros
运行结果(69条记录):
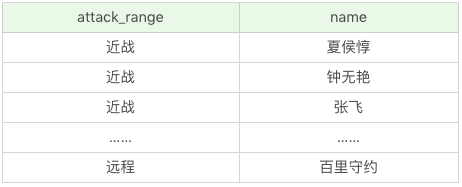
这里有两点需要注意:
SELECT name, DISTINCT attack_range FROM heros会报错。DISTINCT attack_range即可,后面不需要再加其他的列名了。当我们检索数据的时候,有时候需要按照某种顺序进行结果的返回,比如我们想要查询所有的英雄,按照最大生命从高到底的顺序进行排列,就需要使用ORDER BY子句。使用ORDER BY子句有以下几个点需要掌握:
在了解了ORDER BY的使用语法之后,我们来看下如何对heros数据表进行排序。
假设我们想要显示英雄名称及最大生命值,按照最大生命值从高到低的方式进行排序:
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC
运行结果(69条记录):
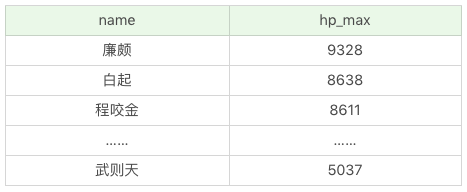
如果想要显示英雄名称及最大生命值,按照第一排序最大法力从低到高,当最大法力值相等的时候则按照第二排序进行,即最大生命值从高到低的方式进行排序:
SQL:SELECT name, hp_max FROM heros ORDER BY mp_max, hp_max DESC
运行结果:(69条记录)
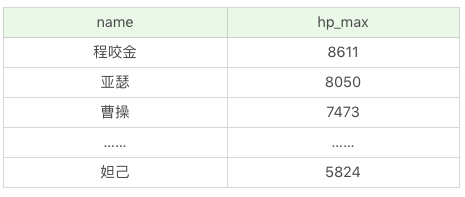
另外在查询过程中,我们可以约束返回结果的数量,使用LIMIT关键字。比如我们想返回英雄名称及最大生命值,按照最大生命值从高到低排序,返回5条记录即可。
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5
运行结果(5条记录):
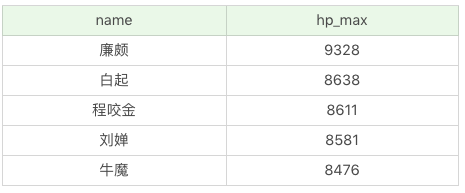
有一点需要注意,约束返回结果的数量,在不同的DBMS中使用的关键字可能不同。在MySQL、PostgreSQL、MariaDB和SQLite中使用LIMIT关键字,而且需要放到SELECT语句的最后面。如果是SQL Server和Access,需要使用TOP关键字,比如:
SQL:SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC
如果是DB2,使用FETCH FIRST 5 ROWS ONLY这样的关键字:
SQL:SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY
如果是Oracle,你需要基于ROWNUM来统计行数:
SQL:SELECT name, hp_max FROM heros WHERE ROWNUM <=5 ORDER BY hp_max DESC
需要说明的是,这条语句是先取出来前5条数据行,然后再按照hp_max从高到低的顺序进行排序。但这样产生的结果和上述方法的并不一样。我会在后面讲到子查询,你可以使用SELECT name, hp_max FROM (SELECT name, hp_max FROM heros ORDER BY hp_max) WHERE ROWNUM <=5得到与上述方法一致的结果。
约束返回结果的数量可以减少数据表的网络传输量,也可以提升查询效率。如果我们知道返回结果只有1条,就可以使用LIMIT 1,告诉SELECT语句只需要返回一条记录即可。这样的好处就是SELECT不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
查询是RDBMS中最频繁的操作。我们在理解SELECT语法的时候,还需要了解SELECT执行时的底层原理。只有这样,才能让我们对SQL有更深刻的认识。
其中你需要记住SELECT查询时的两个顺序:
1.关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
2.SELECT语句的执行顺序(在MySQL和Oracle中,SELECT执行顺序基本相同):
FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT
比如你写了一个SQL语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num #顺序5
FROM player JOIN team ON player.team_id = team.team_id #顺序1
WHERE height > 1.80 #顺序2
GROUP BY player.team_id #顺序3
HAVING num > 2 #顺序4
ORDER BY num DESC #顺序6
LIMIT 2 #顺序7
在SELECT语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在SQL的执行过程中,对于我们来说是不可见的。
我来详细解释一下SQL的执行原理。
首先,你可以注意到,SELECT是先执行FROM这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表vt1,就可以在此基础上再进行WHERE阶段。在这个阶段中,会根据vt1表的结果进行筛选过滤,得到虚拟表vt2。
然后进入第三步和第四步,也就是GROUP和 HAVING阶段。在这个阶段中,实际上是在虚拟表vt2的基础上进行分组和分组过滤,得到中间的虚拟表vt3和vt4。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到SELECT和DISTINCT阶段。
首先在SELECT阶段会提取想要的字段,然后在DISTINCT阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1和vt5-2。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是ORDER BY阶段,得到虚拟表vt6。
最后在vt6的基础上,取出指定行的记录,也就是LIMIT阶段,得到最终的结果,对应的是虚拟表vt7。
当然我们在写SELECT语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为SQL是一门类似英语的结构化查询语言,所以我们在写SELECT语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
当我们初学SELECT语法的时候,经常会使用SELECT *,因为使用方便。实际上这样也增加了数据库的负担。所以如果我们不需要把所有列都检索出来,还是先指定出所需的列名,因为写清列名,可以减少数据表查询的网络传输量,而且考虑到在实际的工作中,我们往往不需要全部的列名,因此你需要养成良好的习惯,写出所需的列名。
如果我们只是练习,或者对数据表进行探索,那么是可以使用SELECT *的。它的查询效率和把所有列名都写出来再进行查询的效率相差并不大。这样可以方便你对数据表有个整体的认知。但是在生产环境下,不推荐你直接使用SELECT *进行查询。
今天我对SELECT的基础语法进行了讲解,SELECT是SQL的基础。但不同阶段看SELECT都会有新的体会。当你第一次学习的时候,关注的往往是如何使用它,或者语法是否正确。再看的时候,可能就会更关注SELECT的查询效率,以及不同DBMS之间的差别。
在我们的日常工作中,很多人都可以写出SELECT语句,但是执行的效率却相差很大。产生这种情况的原因主要有两个,一个是习惯的培养,比如大部分初学者会经常使用SELECT *,而好的习惯则是只查询所需要的列;另一个对SQL查询的执行顺序及查询效率的关注,比如当你知道只有1条记录的时候,就可以使用LIMIT 1来进行约束,从而提升查询效率。
最后留两道思考题吧,我今天对单表的SELECT查询进行了讲解,你之前可能也有学习使用的经验,可以说下你对SELECT使用的理解吗?另外,我今天使用heros数据表进行了举例,请你编写SQL语句,对英雄名称和最大法力进行查询,按照最大生命从高到低排序,只返回5条记录即可。你可以说明下使用的DBMS及相应的SQL语句。
欢迎你把这篇文章分享给你的朋友或者同事,与他们一起来分析一下王者荣耀的数据,互相切磋交流。