你好,我是姚秋辰。
在上一节中我们已经搭建了Seata Server,这节课我们就来动手落地一套Seata AT方案。Seata AT不仅是官方最推荐的一套分布式事务解决方案,也是大多数Seata使用者选用的方案。AT方案备受推崇,一个最主要的原因就在于省心。
Seata AT可以给你带来一种“无侵入”式的编程体验,你不需要改动任何业务代码,只需要一个注解和少量的配置信息,就可以实现分布式事务。这似乎听上去有那么点玄幻,如果一个分布式方案既不依赖XA协议的长事务方案,又不依赖代码补偿逻辑,那碰到Rollback的时候它怎么知道该回滚哪些内容呢?
下面我就通过一个实际的业务模型,带你了解一下AT方案的底层原理。
我们以“删除券模板”作为落地案例,它需要Customer和Template两个服务的共同参与。其中Customer服务是整个业务的起点,它先是调用了Template服务注销券模板,然后再调用本地方法注销了由该模板生成的优惠券。说白了,我们就是在两个不同的微服务中,分别使用Update SQL语句修改了底层数据。
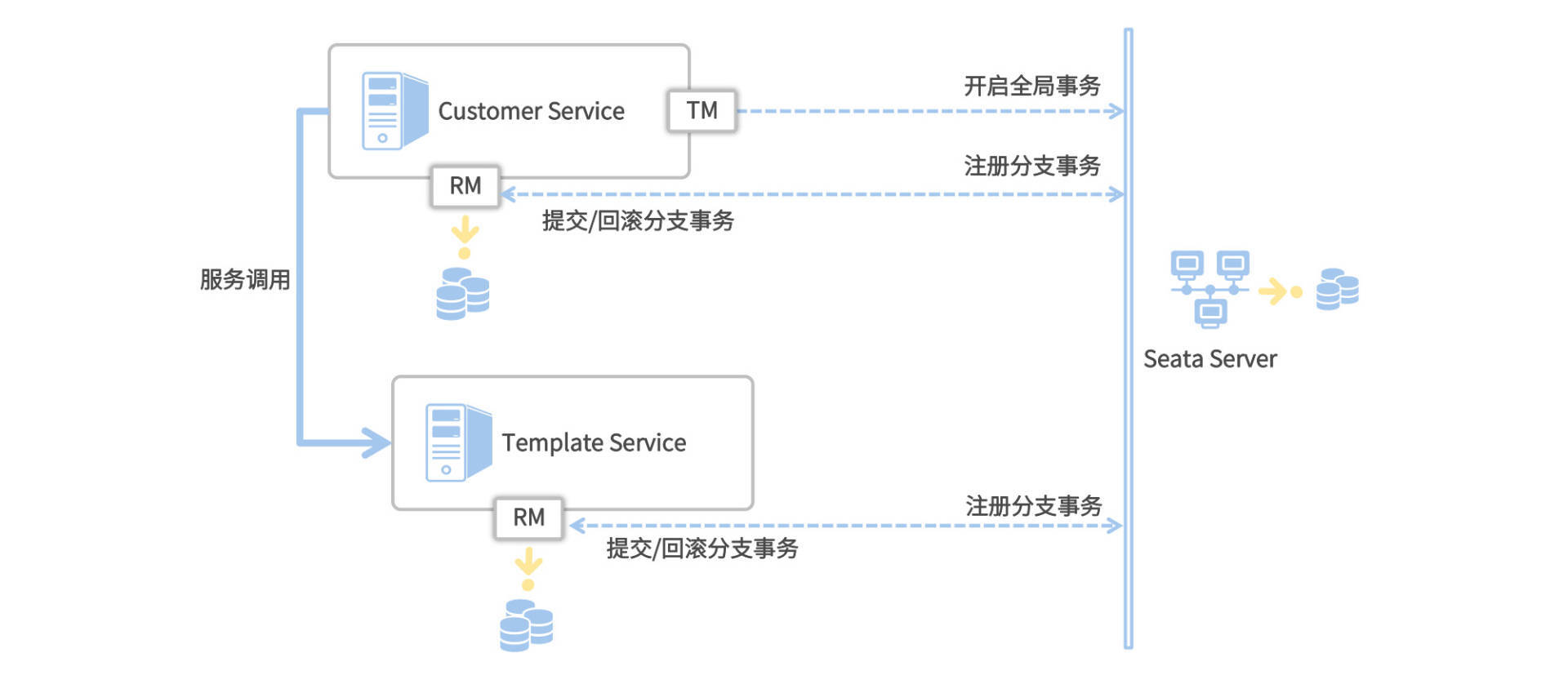
我们接下来就基于“删除券模板”场景,看一下Seata AT背后的业务流程。在开始之前,我需要先花点时间带你认识下Seata框架的三个重要角色,TC、TM和RM。
TC全称是Transaction Coordinator,你一定非常熟悉了,它就是上节课我们介绍过的Seata Server。TC扮演了一个中心化的事务协调者的角色,负责协调全局事务的提交和回滚,并维护全局和分支事务的状态。
TM全称是Transaction Manager,它是事务管理器,主要作用是发起一个全局事务,对全局事务的提交和回滚做出决议。在AT方案中,TM通常是由发起全局事务的那个微服务所扮演的,比如在“删除券模板”这个场景里,TM的扮演者就是Customer服务。
RM全称是Resource Manager,它是资源管理器,向TC注册分支事务并上报事务状态,同时负责对当前分支事务进行提交和回滚。每一个分支事务都是全局事务的参与者,这些分支事务的所属应用扮演了RM的角色。
介绍完了这三个重要角色之后,让我们结合下面这张图来看看Seata AT的业务流程吧。
Seata AT的业务流程分为两个阶段来执行。
从这两个阶段可以看出,Seata AT方案的核心在于这个undo_log。正是有了这个记录回滚日志的undo_log表,我们才能将一阶段和二阶段剥离成两个独立的本地事务来执行。而Seata AT之所以执行效率高,主要原因有两个。一是核心业务逻辑可以在一阶段得到快速提交,DB资源被快速释放;二是全局事务的Commit和Rollback是异步执行。
首先,Customer服务作为分布式事务的起点,扮演了一个TM的角色,它会向TC注册并发起一个全局事务。全局事务会生成一个XID,它是全局唯一的ID标识,所有分支事务都会和这个XID进行绑定。XID在服务内部(非跨服务调用)的传播机制是基于ThreadLocal构建的,即XID在当前线程的上下文中进行透传,对于跨服务调用来说,则依赖seata-all组件内置的各个适配器(如Interceptor和Filter)将XID传递给对象服务。
然后,Customer服务调用了Template服务进行模板注销流程,Template服务的RM开启了一个分支事务,并注册到TC。在执行分支事务的过程中,RM还会生成回滚日志并提交到undo_log表中。除此之外,RM还需要获取到两个特殊的Lock。其中一个是Local Lock(本地锁),另一个是Global Lock(全局锁)。
Lock信息存放在lock_table这张表里,它会记录待修改的资源ID以及它的全局事务和分支事务ID等信息。无论是一阶段提交还是二阶段回滚,RM都需要获取待修改记录的本地锁,然后才会去执行CRUD操作。而在RM提交一阶段事务之前,它还会尝试获取Global Lock(全局锁),目的是防止多个分布式事务对同一条记录进行修改。假设有两个不同的分布式事务想要修改记录A,那么只有同时获取到Local Lock和Global Lock的事务才能正常提交一阶段事务。
本地锁会随一阶段事务的提交/回滚而释放,而全局锁只有等到全局事务提交/回滚之后才会被释放。在一阶段中,如果某一个事务在一定的尝试次数后仍然无法获取全局锁,它会知难而退,执行本地事务回滚操作。而如果在二阶段回滚的时候,RM无法获取本地锁,它会原地打转不停重试,直到成功获取本地锁并完成重试。
接下来,Template服务调用成功,Customer服务开始执行自己的本地事务,流程都大同小异就不说了。TM端根据业务的执行情况,最终做出二阶段决议,Commit或Rollback。
最后,TC向各个分支下达了二阶段决议。如果最终决议是Commit,那么各个RM会执行一段异步操作,删除undo_log;如果最终决议是Rollback,那么RM端会根据undo_log中记录的回滚日志做反向补偿。
到这里,整个全局事务就结束了。下面让我们通过代码实战,落地一套Seata AT的解决方案吧。
我们这次的改造涉及到Customer和Template这两个服务,所以接下来你需要在这两个微服务中提交同样的配置项和代码改动。
在这个环节,你就能体会到什么叫“无感知”的分布式事务了。我们并不需要对业务代码做任何的改动,只需要在分布式事务开始的方法上做一点手脚,添加一个简单的注解,就能为本地事务赋予分布式一致性的能力,用互联网行业的黑话这就叫“赋能”。
按照惯例我们先从添加依赖项开始。
你需要为Customer和Template两个服务添加以下依赖项,它是Seata框架的starter组件。在以往的老版本里,Seata和Spring Cloud的兼容性并不是那么好,我们经常要在starter依赖项中使用exclude标签排除seata-all组件,再单独引入一个不同版本的seata-all。但在新版本中,这个兼容性问题已经不复存在,我们只需要一个依赖就够了。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
添加好了依赖项,接下来我们需要到代码中声明一个数据源代理类。
Seata AT之所以能够实现无感知的编程体验,其中的一个秘诀就在这个数据源代理上了。
我们在项目中使用的数据源通常是JDBC driver的底层DataSource,或者是hikari之类的连接池。但在分布式事务的场景上,为了能够在分支事务开启/提交等关键节点上做一番手脚(比如向Seata注册分支事务、生成undo_log等),我们需要用Seata特有的数据源“接管”项目原有的数据源。
我在项目中创建了一个SeataConfiguration的类,用来声明一个Seata特有的数据源,作为当前项目的DataSrouce代理。
@Configuration
public class SeataConfiguration {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
@Bean("dataSource")
@Primary
public DataSource dataSourceDelegation(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
在上面的代码中,我先是创建了一个DruidDataSource作为数据源连接池,并指定其读取spring.datasoource下的数据库连接信息。Druid也是alibaba出品的一个开源数据库连接池方案,在阿里系内部应用也非常广泛。
在dataSourceDelegation方法中,我声明了一个DataSourceProxy的类,并接收DruidDataSource作为构造器初始化参数。DataSourceProxy是由Seata框架提供的一个数据源代理类,为了确保Spring上下文使用DataSourceProxy而不是其它三方数据源,我在dataSourceDelegation方法上添加了@Primary注解,将其作为javax.sql.DataSource的默认代理类。
数据源代理改造完成之后,我们可以去添加seata的配置项了。
Seata的配置项定义在application.yml文件中,分为上下两部分,一部分在spring.cloud.alibaba节点下面,它指定了当前应用的事务分组;另一部分在根节点seata下面,定义了连接Seata Server的方式。
spring:
cloud:
alibaba:
seata:
tx-service-group: seata-server-group
seata:
application-id: coupon-customer-serv
registry:
type: nacos
nacos:
application: seata-server
server-addr: localhost:8848
namespace: dev
group: myGroup
cluster: default
service:
vgroup-mapping:
seata-server-group: default
在seata.registry节点下,我通过type属性指定了本地服务和Seata Server之间基于Nacos服务发现来获取地址信息,而且我还在seata.registry.nacos节点下配置了Nacos的地址、命名空间、group等信息。
spring.cloud.alibaba.seata.tx-service-group节点定义了事务服务的分组名称,你可以随意写一个名称,比如我这里写的是seata-server-group。唯一要注意的一点是,tx-service-group中的分组名称一定要和seata.service.vgroup-mapping中定义的分组名称一致,我为seata-server-group分组所指定的值是default,这个值会被用来获取Seata Server地址。
在项目启动的时候,Seata框架会尝试从Nacos获取Seata Server的地址信息,执行这个操作的类是NacosRegistryServiceImpl。在这个类的lookup方法中,Seata使用了下面这行代码查找seata-server服务,其中clusters参数的值就来自于seata.service.vgroup-mapping.seata-server-group所对应的值。
List<Instance> firstAllInstances = getNamingInstance()
.getAllInstances(getServiceName(), getServiceGroup(), clusters);
关于Seata AT的所有准备工作到这里就完成了,接下来我们就去写一段分布式事务的方法。
删除券模板是一个非常合适的分布式事务用例,全局事务分别在Template服务和Customer服务两个地方进行了Write操作。全局事务是从Customer服务开启的,在Customer服务中我们先调用Template服务将模板设置为Inactive状态,然后在Customer服务本地将用户所领取到的相关优惠券全部注销。
首先,我们在Customer服务中声明一个新的Controller方法deleteTemplate,它作为整个链路的调用起点,入参是一个TemplateID。
@DeleteMapping("template")
@GlobalTransactional(name = "coupon-customer-serv", rollbackFor = Exception.class)
public void deleteCoupon(@RequestParam("templateId") Long templateId) {
customerService.deleteCouponTemplate(templateId);
}
在这个方法上,我使用了一个特殊的注解@GlobalTransactional,它是Seata用来开启分布式事务的顶层注解。你只要在全局事务“开始”的地方把这个注解添加上去就好了,并不需要在每个分支事务中都声明它。全局事务碰到任何Exception异常,都会触发全局事务回滚操作,这个行为是通过GlobalTransactional注解的rollbackFor方法指定的。
删除模板的业务逻辑定义在了CustomerService类中,你可以参考下面的代码。
@Override
@Transactional
public void deleteCouponTemplate(Long templateId) {
templateService.deleteTemplate(templateId);
couponDao.deleteCouponInBatch(templateId, CouponStatus.INACTIVE);
// 模拟分布式异常
throw new RuntimeException("AT分布式事务挂球了");
}
我先是借助templateService这个Openfeign接口,间接调用了Template服务注销模板,再通过一个本地DAO方法注销了用户已经领取的优惠券。为了验证分布式事务是否能正常回滚,我在方法的最后一行抛出了一个RuntimeException。
在开启Seata分布式事务的时候,你必须把异常抛出到全局事务的发起方,让@GlobalTransactional注解的方法能够感知到这个异常,才能顺利触发事务的回滚。如果你开发了统一的异常处理拦截器,记得千万不要把异常吞掉。
在非分布式事务的模式下,即便有异常抛出,也顶多只能触发本地事务的回滚,而Template远程服务调用对应的DB改动是不会被回滚的。接下来我们一起见证一下Seata AT方案能否把Template的改动也一块回滚。
让我们通过下面这几步操作构造一个测试用例:
此时切换到Template服务的控制台页面,你会看到Seata框架输出的几行关键日志(加粗部分)。
再检查一下数据库表,你会发现Template表中的模板数据并没有被注销,这表示我们二阶段回滚逻辑执行成功。到这里,我们就完整搭建了一套Seata AT无侵入式的分布式事务方案。
如果从编写代码的角度来看,Seata AT方案应该是一致性解决方案中的Easy模式了,既没有XA方案的DB性能瓶颈,也不用编写任何跑批补偿的业务。但尽管如此,我还是坚持一个观点:非必要就别上分布式事务。
Seata分布式事务是个双刃剑,当我们给项目引入Seata的时候,无形中也增加了架构层面的复杂程度,说白了,就是增加了一个failure point。你需要考虑Seata Server不可用的情况,制定降级预案保证业务正常运转。同时在大促等环节的压测端,你也要对Seata Server的高可用做好充足的功课。
如果你的本地业务非常简单,那么没必要上Seata,这纯属用大炮打苍蝇。我推荐你使用传统的事务型消息+日志补偿+跑批补偿的方式,用最经济实惠的技术手段搞定简单业务。
你能深入Seata Client端的源码,了解GlobalTransactional注解是如何接收二阶段提交/回滚的指令的吗?一个方向是顺着GlobalTransactional注解找对应的拦截器逻辑,再往下深挖;另一个方向是从代码中的Rollback/Commit日志中找到对应的类,反向摸排。
好啦,这节课就结束啦。欢迎你把这节课分享给更多对Spring Cloud感兴趣的朋友。我是姚秋辰,我们下节课再见!