你好,我是Tony Bai。
美国时间2022年1月31日,在中国人民欢庆虎年春节之际,Go核心团队发布了Go 1.18 Beta2版本。在Go 1.18beta2版本发布的博文中,Go核心团队还给出了Go 1.18版本的发布计划:2022年2月发布Go 1.18RC(release candidate,即发布候选版),2022年3月发布Go 1.18最终版本。
考虑到Go 1.18版本中引入了Go语言开源以来最大的语法特性变化:泛型(generic),改动和影响都很大,Go核心团队将Go 1.18版本延迟一个月,放到3月发布也不失为稳妥之举。
在Go泛型正式落地之前,我想在这篇加餐中带你认识一下Go泛型,目的是“抛砖引玉”,为你后续系统学习和应用Go泛型语法特性开个头儿。
我们今天将围绕Go为什么加入泛型、泛型设计方案的演化历史、Go泛型的主要语法以及Go泛型的使用建议几个方面,聊聊Go泛型的那些事儿。
首先,我们先来了解一下Go语言为什么要加入泛型语法特性。
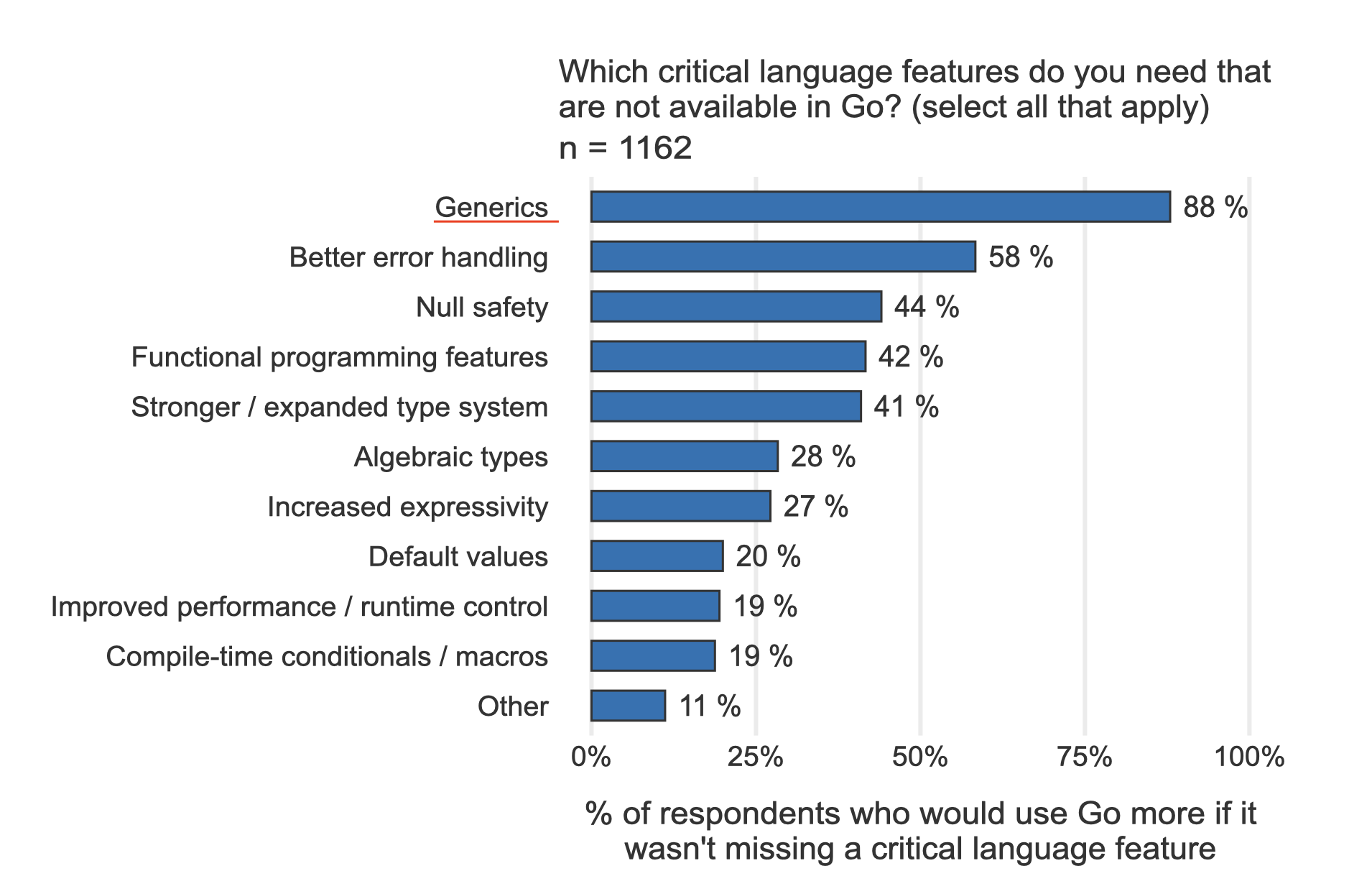
根据近几年的Go官方用户调查结果,在“你最想要的Go语言特性”这项调查中,泛型霸榜多年。你可以看下这张摘自最新的2020年Go官方用户调查结果的图片:
既然Go社区对泛型特性的需求如此强烈,那么Go核心团队为何要在Go开源后的第13个年头,才将这个特性加入语言当中呢?这里的故事说来话长。要想了解其中原因,我们需要先来了解一下什么是泛型?
维基百科提到:最初泛型编程这个概念来自于缪斯.大卫和斯捷潘诺夫.亚历山大合著的“泛型编程”一文。那篇文章对泛型编程的诠释是:“泛型编程的中心思想是对具体的、高效的算法进行抽象,以获得通用的算法,然后这些算法可以与不同的数据表示法结合起来,产生各种各样有用的软件”。说白了就是将算法与类型解耦,实现算法更广泛的复用。
我们举个简单的例子。这里是一个简单得不能再简单的加法函数,这个函数接受两个int32类型参数作为加数:
func Add(a, b int32) int32 {
return a + b
}
不过上面的函数Add仅适用于int32类型的加数,如果我们要对int、int64、byte等类型的加数进行加法运算,我们还需要实现AddInt、AddInt64、AddByte等函数。
那如果我们用泛型编程的思想来解决这个问题,是怎样呢?
我们需要将算法与类型解耦,实现一个泛型版的Add算法,我们用Go泛型语法实现的泛型版Add是这样的(注意这里需要使用Go 1.18beta1或后续版本进行编译和运行):
func Add[T constraints.Integer](a, b T) T {
return a + b
}
这样,我们就可以直接使用泛型版Add函数去进行各种整型类型的加法运算了,比如下面代码:
func main() {
var m, n int = 5, 6
println(Add(m,n)) // Add[int](m, n)
var i,j int64 = 15, 16
println(Add(i,j)) // Add[int64](i, j)
var c,d byte = 0x11, 0x12
println(Add(c,d)) // Add[byte](c, d)
}
通过这个例子我们可以看到,在没有泛型的情况下,我们需要针对不同类型重复实现相同的算法逻辑,比如上面例子提到的AddInt、AddInt64等。
这对于简单的、诸如上面这样的加法函数还可忍受,但对于复杂的算法,比如涉及复杂排序、查找、树、图等算法,以及一些容器类型(链表、栈、队列等)的实现时,缺少了泛型的支持还真是麻烦。
在没有泛型之前,Gopher们通常使用空接口类型interface{},作为算法操作的对象的数据类型,不过这样做的不足之处也很明显:一是无法进行类型安全检查,二是性能有损失。
那么回到前面的问题,既然泛型有这么多优点,为什么Go不早点加入泛型呢?其实这个问题在Go FAQ中早有答案,我总结一下大概三点主要理由:
在Go诞生早期,很多基本语法特性的优先级都要高于泛型。此外,Go团队更多将语言的设计目标定位在规模化(scalability)、可读性、并发性上,泛型与这些主要目标关联性不强。等Go成熟后,Go团队会在适当时候引入泛型。
Go语言最吸睛的地方就是简单,简单也是Go设计哲学之首!但泛型这个语法特性会给语言带来复杂性,这种复杂性不仅体现在语法层面上引入了新的语法元素,也体现在类型系统和运行时层面上为支持泛型进行了复杂的实现。
从Go开源那一天开始,Go团队就没有间断过对泛型的探索,并一直尝试寻找一个理想的泛型设计方案,但始终未能如愿。
直到近几年Go团队觉得Go已经逐渐成熟,是时候下决心解决Go社区主要关注的几个问题了,包括泛型、包依赖以及错误处理等,并安排伊恩·泰勒和罗伯特·格瑞史莫花费更多精力在泛型的设计方案上,这才有了在即将发布的Go 1.18版本中泛型语法特性的落地。
为了让你更清晰地看到Go团队在泛型上付出的努力,同时也能了解Go泛型的设计过程与来龙去脉,这里我简单整理了一个Go泛型设计的简史,你可以参考一下。
Go核心团队对泛型的探索,是从2009年12月3日Russ Cox在其博客站点上发表的一篇文章开始的。在这篇叫“泛型窘境”的文章中,Russ Cox提出了Go泛型实现的三个可遵循的方法,以及每种方法的不足,也就是三个slow(拖慢):
在当时,三个slow之间需要取舍,就如同数据一致性的CAP原则一样,无法将三个slow同时消除。
之后,伊恩·泰勒主要负责持续跟进Go泛型方案的设计,从2010到2016年,伊恩·泰勒先后提出了几版泛型设计方案,它们是:
虽然这些方案因为存在各种不足,最终都没有被接受,但这些探索为后续Go泛型的最终落地奠定了基础。
2017年7月,Russ Cox在GopherCon 2017大会上发表演讲“Toward Go 2”,正式吹响Go向下一个阶段演化的号角,包括重点解决泛型、包依赖以及错误处理等Go社区最广泛关注的问题。
后来,在2018年8月,也就是GopherCon 2018大会结束后不久,Go核心团队发布了Go2 draft proposal,这里面涵盖了由伊恩·泰勒和罗伯特·格瑞史莫操刀主写的Go泛型的第一版draft proposal。
这版设计草案引入了contract关键字来定义泛型类型参数(type parameter)的约束、类型参数放在普通函数参数列表前面的小括号中,并用type关键字声明。下面是这个草案的语法示例:
// 第一版泛型技术草案中的典型泛型语法
contract stringer(x T) {
var s string = x.String()
}
func Stringify(type T stringer)(s []T) (ret []string) {
}
接着,在2019年7月,伊恩·泰勒在GopherCon 2019大会上发表演讲“Why Generics?”,并更新了泛型的技术草案,简化了contract的语法设计,下面是简化后的contract语法,你可以对比上面代码示例中的contract语法看看:
contract stringer(T) {
T String() string
}
后来,在2020年6月,一篇叫《Featherweight Go》论文发表在arxiv.org上,这篇论文出自著名计算机科学家、函数语言专家、Haskell语言的设计者之一、Java泛型的设计者菲利普-瓦德勒(PHILIP WADLER)之手。
Rob Pike邀请他Go核心团队解决Go语言的泛型扩展问题,这篇论文就是菲利普-瓦德对这次邀请的回应
这篇论文为Go语言的一个最小语法子集设计了泛型语法Featherweight Generic Go(FGG),并成功地给出了FGG到Feighterweight Go(FG)的可行性实现的形式化证明。这篇论文的形式化证明给Go团队带来了很大信心,也让Go团队在一些泛型语法问题上达成更广泛的一致。
2020年6月末,伊恩·泰勒和罗伯特·格瑞史莫在Go官方博客发表了文章《The Next Step for Generics》,介绍了Go泛型工作的最新进展。Go团队放弃了之前的技术草案,并重新编写了一个新草案。
在这份新技术方案中,Go团队放弃了引入contract关键字作为泛型类型参数的约束,而采用扩展后的interface来替代contract。这样上面的Stringify函数就可以写成如下形式:
type Stringer interface {
String() string
}
func Stringify(type T Stringer)(s []T) (ret []string) {
... ...
}
同时,Go团队还推出了可以在线试验Go泛型语法的playground,这样Gopher们可以直观体验新语法,并给出自己的意见反馈。
然后,在2020年11月的GopherCon 2020大会,罗伯特·格瑞史莫与全世界的Gopher同步了Go泛型的最新进展和roadmap,在最新的技术草案版本中,包裹类型参数的小括号被方括号取代,类型参数前面的type关键字也不再需要了:
func Stringify[T Stringer](s []T) (ret []string) {
... ...
}
与此同时,go2goplay.golang.org也支持了方括号语法,Gopher们可以在线体验。
接下来的2021年1月,Go团队正式提出将泛型加入Go的proposal,2021年2月,这个提案被正式接受。
然后是2021年4月,伊恩·泰勒在GitHub上发布issue,提议去除原Go泛型方案中置于interface定义中的type list中的type关键字,并引入type set的概念,下面是相关示例代码:
// 之前使用type list的方案
type SignedInteger interface {
type int, int8, int16, int32, int64
}
// type set理念下的新语法
type SignedInteger interface {
~int | ~int8 | ~int16 | ~int32 | ~int64
}
那什么是type set(类型集合)呢?伊恩·泰勒给出了这个概念的定义:
这样一来,我们可以试试用type set概念,重新表述一下一个类型T实现一个接口类型I:也就是当类型T是接口类型I的type set的一员时,T便实现了接口I;对于使用嵌入接口类型组合而成的接口类型,其type set就是其所有的嵌入的接口类型的type set的交集。
而对于一个带有自身Method的嵌入其他接口类型的接口类型,比如下面代码中的MyInterface3:
type MyInterface3 interface {
E1
E2
MyMethod03()
}
它的type set可以看成E1、E2和E3(type E3 interface { MyMethod03()})的type set的交集。
最后,在2021年12月14日,Go 1.18 beta1版本发布,这个版本包含了对Go泛型的正式支持。
经过12年的努力与不断地自我否定,Go团队终于将泛型引入到Go中,并且经过缜密设计的语法并没有违背Go1的兼容性。那么接下来,我们就正式看看Go泛型的基本语法。
我们前面也说了,Go泛型是Go开源以来在语法层面的最大一次变动,Go泛型的最后一版技术提案长达数十页,我们要是把其中的细节都展开细讲,那都可以自成一本小册子了。因此,Go泛型语法不是一篇加餐可以系统学习完的,我这里不会抠太多细节,只给你呈现主要的语法
Go泛型的核心是类型参数(type parameter),下面我们就从类型参数开始,了解一下Go泛型的基本语法。
类型参数是在函数声明、方法声明的receiver部分或类型定义的类型参数列表中,声明的(非限定)类型名称。类型参数在声明中充当了一个未知类型的占位符(placeholder),在泛型函数或泛型类型实例化时,类型参数会被一个类型实参替换。
为了让你更好地理解类型参数究竟如何声明,它又起到了什么作用,我们以函数为例,对普通函数的参数与泛型函数的类型参数作一下对比:
我们知道,普通函数的参数列表是这样的:
func Foo(x, y aType, z anotherType)
这里,x, y, z是形参(parameter)的名字,也就是变量,而aType,anotherType是形参的类型,也就是类型。
我们再来看一下泛型函数的类型参数(type parameter)列表:
func GenericFoo[P aConstraint, Q anotherConstraint](x,y P, z Q)
这里,P,Q是类型形参的名字,也就是类型,aConstraint,anotherConstraint代表类型参数的约束(constraint),我们可以理解为对类型参数可选值的一种限定。
从GenericFoo函数的声明中,我们可以看到,泛型函数的声明相比于普通函数多出了一个组成部分:类型参数列表。
类型参数列表位于函数名与函数参数列表之间,通过一个方括号括起。类型参数列表不支持变长类型参数。而且,类型参数列表中声明的类型参数,可以作为函数普通参数列表中的形参类型。
但在泛型函数声明时,我们并不知道P、Q两个类型参数具体代表的究竟是什么类型,因此函数参数列表中的P、Q更像是未知类型的占位符。
那么P、Q的类型什么时候才能确定呢?这就要等到泛型函数具化(instantiation)时才能确定。另外,按惯例,类型参数(type parameter)的名字都是首字母大写的,通常都是用单个大写字母命名。
在类型参数列表中修饰类型参数的就是约束(constraint)。那什么是约束呢?我们继续往下看。
约束(constraint)规定了一个类型实参(type argument)必须满足的条件要求。如果某个类型满足了某个约束规定的所有条件要求,那么它就是这个约束修饰的类型形参的一个合法的类型实参。
在Go泛型中,我们使用interface类型来定义约束。为此,Go接口类型的定义也进行了扩展,我们既可以声明接口的方法集合,也可以声明可用作类型实参的类型列表。下面是一个约束定义与使用的示例:
type C1 interface {
~int | ~int32
M1()
}
type T struct{}
func (T) M1() {
}
type T1 int
func (T1) M1() {
}
func foo[P C1](t P)() {
}
func main() {
var t1 T1
foo(t1)
var t T
foo(t) // 编译器报错:T does not implement C1
}
在这段代码中,C1是我们定义的约束,它声明了一个方法M1,以及两个可用作类型实参的类型(~int | ~int32)。我们看到,类型列表中的多个类型实参类型用“|”分隔。
在这段代码中,我们还定义了两个自定义类型T和T1,两个类型都实现了M1方法,但T类型的底层类型为struct{},而T1类型的底层类型为int,这样就导致了虽然T类型满足了约束C1的方法集合,但类型T因为底层类型并不是int或int32而不满足约束C1,这也就会导致foo(t)调用在编译阶段报错。
不过,我这里还要建议你:做约束的接口类型与做传统接口的接口类型最好要分开定义,除非约束类型真的既需要方法集合,也需要类型列表。
知道了类型参数声明的形式,也知道了约束如何定义后,我们再来看看如何使用带有类型参数的泛型函数。
声明了泛型函数后,接下来就要调用泛型函数来实现具体的业务逻辑。现在我们就通过一个泛型版本Sort函数的调用例子,看看调用泛型函数的过程都发生了什么:
func Sort[Elem interface{ Less(y Elem) bool }](list []Elem) {
}
type book struct{}
func (x book) Less(y book) bool {
return true
}
func main() {
var bookshelf []book
Sort[book](bookshelf) // 泛型函数调用
}
根据Go泛型的实现原理,上面的泛型函数调用Sort[book](bookshelf)会分成两个阶段:
第一个阶段就是具化(instantiation)。
形象点说,具化(instantiation)就好比一家生产“排序机器”的工厂根据要排序的对象的类型,将这样的机器生产出来的过程。我们继续举前面的例子来分析一下,整个具化过程如下:
第二阶段是调用(invocation)。
一旦“排序机器”被生产出来,那么它就可以对目标对象进行排序了,这和普通的函数调用没有区别。这里就相当于调用booksort(bookshelf),整个过程只需要检查传入的函数实参(bookshelf)的类型与booksort函数原型中的形参类型([]book)是否匹配就可以了。
我们用伪代码来表述上面两个过程:
Sort[book](bookshelf)
<=>
具化:booksort := Sort[book]
调用:booksort(bookshelf)
不过,每次调用Sort都要传入类型实参book,这和普通函数调用相比还是繁琐了不少。那么能否像普通函数那样只传入普通参数实参,不用传入类型参数实参呢?
答案是可以的。
Go编译器会根据传入的实参变量,进行实参类型参数的自动推导(Argument type inference),也就是说上面的例子,我们只需要像这样进行Sort的调用就可以了:
Sort(bookshelf)
有了对类型参数的实参类型的自动推导,大多数泛型函数的调用方式与常规函数调用一致,不会给Gopher带去额外的代码编写负担。
除了函数可以携带类型参数变身为“泛型函数”外,类型也可以拥有类型参数而化身为“泛型类型”,比如下面代码就定义了一个向量泛型类型:
type Vector[T any] []T
这是一个带有类型参数的类型定义,类型参数位于类型名的后面,同样用方括号括起。在类型定义体中可以引用类型参数列表中的参数名(比如T)。类型参数同样拥有自己的约束,如上面代码中的any。在Go 1.18中,any是interface{}的别名,也是一个预定义标识符,使用any作为类型参数的约束,代表没有任何约束。
使用泛型类型,我们也要遵循先具化,再使用的顺序,比如下面例子:
type Vector[T any] []T
func (v Vector[T]) Dump() {
fmt.Printf("%#v\n", v)
}
func main() {
var iv = Vector[int]{1,2,3,4}
var sv Vector[string]
sv = []string{"a","b", "c", "d"}
iv.Dump()
sv.Dump()
}
在这段代码中,我们在使用Vector[T]之前都显式用类型实参对泛型类型进行了具化,从而得到具化后的类型Vector[int]和Vector[string]。 Vector[int]的底层类型为[]int,Vector[string]的底层类型为[]string。然后我们再对具化后的类型进行操作。
以上就是Go泛型语法特性的一些主要语法概念,我们可以看到,泛型的加入确实进一步提高了程序员的开发效率,大幅提升了算法的重用性。
那么,Go泛型方案对Go程序的运行时性能又带来了哪些影响呢?我们接下来就来通过例子验证一下。
我们创建一个性能基准测试的例子,参加这次测试的三位选手分别来自:
相关的源码较多,我这里就不贴出来了,你可以到这里下载相关源码。
下面是使用Go 1.18beta2版本在macOS上运行该测试的结果:
$go test -bench .
goos: darwin
goarch: amd64
pkg: demo
cpu: Intel(R) Core(TM) i5-8257U CPU @ 1.40GHz
BenchmarkSortInts-8 96 12407700 ns/op 24 B/op 1 allocs/op
BenchmarkSlicesSort-8 172 6961381 ns/op 0 B/op 0 allocs/op
BenchmarkIntSort-8 172 6881815 ns/op 0 B/op 0 allocs/op
PASS
我们看到,泛型版和仅支持[]int的Sort函数的性能是一致的,性能都要比目前标准库的Ints函数高出近一倍,并且在排序过程中没有额外的内存分配。由此我们可以得出结论:至少在这个例子中,泛型在运行时并未给算法带来额外的负担。
现在看来,Go泛型没有拖慢程序员的开发效率,也没有拖慢运行效率,那么按照Russ Cox的“泛型窘境”文章中的结论,Go泛型是否拖慢编译性能了呢?
不过,因为目前采用Go泛型重写的项目比较少,我们还没法举例对比,但Go 1.18发布说明中给出了一个结论:Go 1.18编译器的性能要比Go 1.17下降15%左右。不过,Go核心团队也承诺将在Go 1.19中改善编译器的性能,这里也希望到时候的优化能抵消Go泛型带来的影响。
了解了Go泛型并未影响到运行时性能,这让我们的心里有了底。但关于Go泛型,想必你还会有疑问,那就是:我们应该在什么时候使用泛型,又应该如何使用泛型呢?最后我们就来看看这两个问题的答案。
前面说过,Go当初没有及时引入泛型的一个原因就是与Go语言“简单”的设计哲学有悖,现在加入了泛型,随之而来的就是增加了语言的复杂性。
为了尽量降低复杂性,Go团队做了很多工作,包括前面提到的在语法中加入类型实参的自动推导等语法糖,尽量减少给开发人员编码时带去额外负担,也尽可能保持Go代码良好的可读性。
此外,Go核心团队最担心的就是“泛型被滥用”,所以Go核心团队在各种演讲场合都在努力地告诉大家Go泛型的适用场景以及应该如何使用。这里我也梳理一下来自Go团队的这些建议,你可以参考一下。
首先,类型参数的一种有用的情况,就是当编写的函数的操作元素的类型为slice、map、channel等特定类型的时候。如果一个函数接受这些类型的形参,并且函数代码没有对参数的元素类型作出任何假设,那么使用类型参数可能会非常有用。在这种场合下,泛型方案可以替代反射方案,获得更高的性能。
另一个适合使用类型参数的情况是编写通用数据结构。所谓的通用数据结构,指的是像切片或map这样,但Go语言又没有提供原生支持的类型。比如一个链表或一个二叉树。
今天,需要这类数据结构的程序会使用特定的元素类型实现它们,或者是使用接口类型(interface{})来实现。不过,如果我们使用类型参数替换特定元素类型,可以实现一个更通用的数据结构,这个通用的数据结构可以被其他程序复用。而且,用类型参数替换接口类型通常也会让数据存储的更为高效。
另外,在一些场合,使用类型参数替代接口类型,意味着代码可以避免进行类型断言(type assertion),并且在编译阶段还可以进行全面的类型静态检查。
首先,如果你要对某一类型的值进行的全部操作,仅仅是在那个值上调用一个方法,请使用interface类型,而不是类型参数。比如:io.Reader易读且高效,没有必要像下面代码中这样使用一个类型参数像调用Read方法那样去从一个值中读取数据:
func ReadAll[reader io.Reader](r reader) ([]byte, error) // 错误的作法
func ReadAll(r io.Reader) ([]byte, error) // 正确的作法
使用类型参数的原因是它们让你的代码更清晰,如果它们会让你的代码变得更复杂,就不要使用。
第二,当不同的类型使用一个共同的方法时,如果一个方法的实现对于所有类型都相同,就使用类型参数;相反,如果每种类型的实现各不相同,请使用不同的方法,不要使用类型参数。
最后,如果你发现自己多次编写完全相同的代码(样板代码),各个版本之间唯一的差别是代码使用不同的类型,那就请你考虑是否可以使用类型参数。反之,在你注意到自己要多次编写完全相同的代码之前,应该避免使用类型参数。
好了,今天的加餐讲到这里就结束了。在这一讲中,我带你初步了解了Go泛型的那些事儿,主要是想为你后续系统学习Go泛型引个路。
正如Go团队在Go FAQ中描述的那样,Go团队从来没有拒绝泛型,只是长时间来没有找到一个合适的实现方案。Go团队需要在Russ Cox的“泛型窘境”中提到的三个slow中寻找平衡。
十多年来,Go团队一直在尝试与打磨,终于在近几年取得了突破性的进展,设计出一种可以向后兼容Go1的方案,并下决心在Go 1.18版本中落地泛型。
Go泛型也称为类型参数,我们可以在函数声明、方法声明的receiver部分或类型定义中使用类型参数,来实现泛型函数和泛型类型。我们还需为类型参数设定约束,通过扩展的interface类型定义,我们可以定义这种约束。
目前来看,Go泛型的引入并没有给程序运行带来额外性能开销,但在一定程度上拖慢的编译器的性能。同时也带来了语法上的复杂性,为此,Go团队建议大家谨慎使用泛型,同时给出了一些使用建议。
最后要和你特别说明一下,Go 1.18仅仅是Go泛型的起点,就像Go Module构建机制一样,Go泛型的成熟与稳定还需要几个Go发布版本的努力。而且我们这一讲中涉及到泛型的代码都需要你安装Go 1.18beta1或以上版本。
Go泛型对于你来说估计还比较陌生,这里我也给你留了一个作业,那就是仔细阅读一遍Go泛型的技术方案:https://go.googlesource.com/proposal/+/refs/heads/master/design/43651-type-parameters.md
如果你在阅读过程中有任何问题,欢迎在留言区提出。我是Tony Bai,我们下节课再见。