你好,我是唐聪。
在使用etcd的过程中,你是否吐槽过etcd性能差呢? 我们知道,etcd社区线性读压测结果可以达到14w/s,那为什么在实际业务场景中有时却只有几千,甚至几百、几十,还会偶发超时、频繁抖动呢?
我相信不少人都遇到过类似的问题。要解决这些问题,不仅需要了解症结所在,还需要掌握优化和扩展etcd性能的方法,对症下药。因为这部分内容比较多,所以我分成了两讲内容,分别从读性能、写性能和稳定性入手,为你详细讲解如何优化及扩展etcd性能及稳定性。
希望通过这两节课的学习,能让你在使用etcd的时候,设计出良好的业务存储结构,遵循最佳实践,让etcd稳定、高效地运行,获得符合预期的性能。同时,当你面对etcd性能瓶颈的时候,也能自己分析瓶颈原因、选择合适的优化方案解决它,而不是盲目甩锅etcd,甚至更换技术方案去etcd化。
今天这节课,我将重点为你介绍如何提升读的性能。
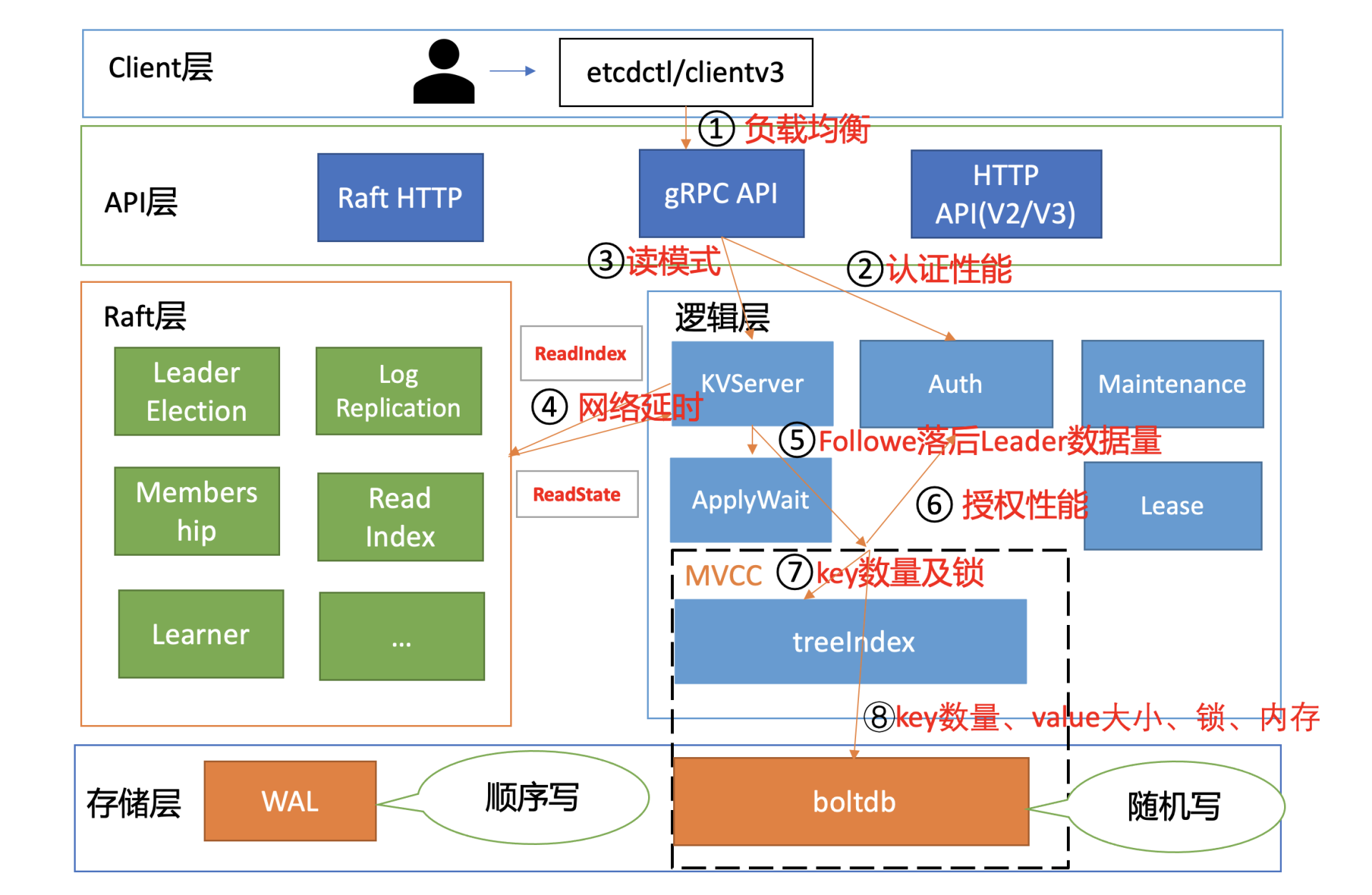
我们说读性能差,其实本质是读请求链路中某些环节出现了瓶颈。所以,接下来我将通过一张读性能分析链路图,为你从上至下分析影响etcd性能、稳定性的若干因素,并给出相应的压测数据,最终为你总结出一系列的etcd性能优化和扩展方法。
为什么在你的业务场景中读性能不如预期呢? 是读流程中的哪一个环节出现了瓶颈?
在下图中,我为你总结了一个开启密码鉴权场景的读性能瓶颈分析链路图,并在每个核心步骤数字旁边,标出了影响性能的关键因素。我之所以选用密码鉴权的读请求为案例,是因为它使用较广泛并且请求链路覆盖最全,同时它也是最容易遇到性能瓶颈的场景。
接下来我将按照这张链路分析图,带你深入分析一个使用密码鉴权的线性读请求,和你一起看看影响它性能表现的核心因素以及最佳优化实践。
首先是流程一负载均衡。在02节时我和你提到过,在etcd 3.4以前,client为了节省与server节点的连接数,clientv3负载均衡器最终只会选择一个sever节点IP,与其建立一个长连接。
但是这可能会导致对应的server节点过载(如单节点流量过大,出现丢包), 其他节点却是低负载,最终导致业务无法获得集群的最佳性能。在etcd 3.4后,引入了Round-robin负载均衡算法,它通过轮询的方式依次从endpoint列表中选择一个endpoint访问(长连接),使server节点负载尽量均衡。
所以,如果你使用的是etcd低版本,那么我建议你通过Load Balancer访问后端etcd集群。因为一方面Load Balancer一般支持配置各种负载均衡算法,如连接数、Round-robin等,可以使你的集群负载更加均衡,规避etcd client早期的固定连接缺陷,获得集群最佳性能。
另一方面,当你集群节点需要替换、扩缩容集群节点的时候,你不需要去调整各个client访问server的节点配置。
client通过负载均衡算法为请求选择好etcd server节点后,client就可调用server的Range RPC方法,把请求发送给etcd server。在此过程中,如果server启用了鉴权,那么就会返回无权限相关错误给client。
如果server使用的是密码鉴权,你在创建client时,需指定用户名和密码。etcd clientv3库发现用户名、密码非空,就会先校验用户名和密码是否正确。
client是如何向sever请求校验用户名、密码正确性的呢?
client是通过向server发送Authenticate RPC鉴权请求实现密码认证的,也就是图中的流程二。
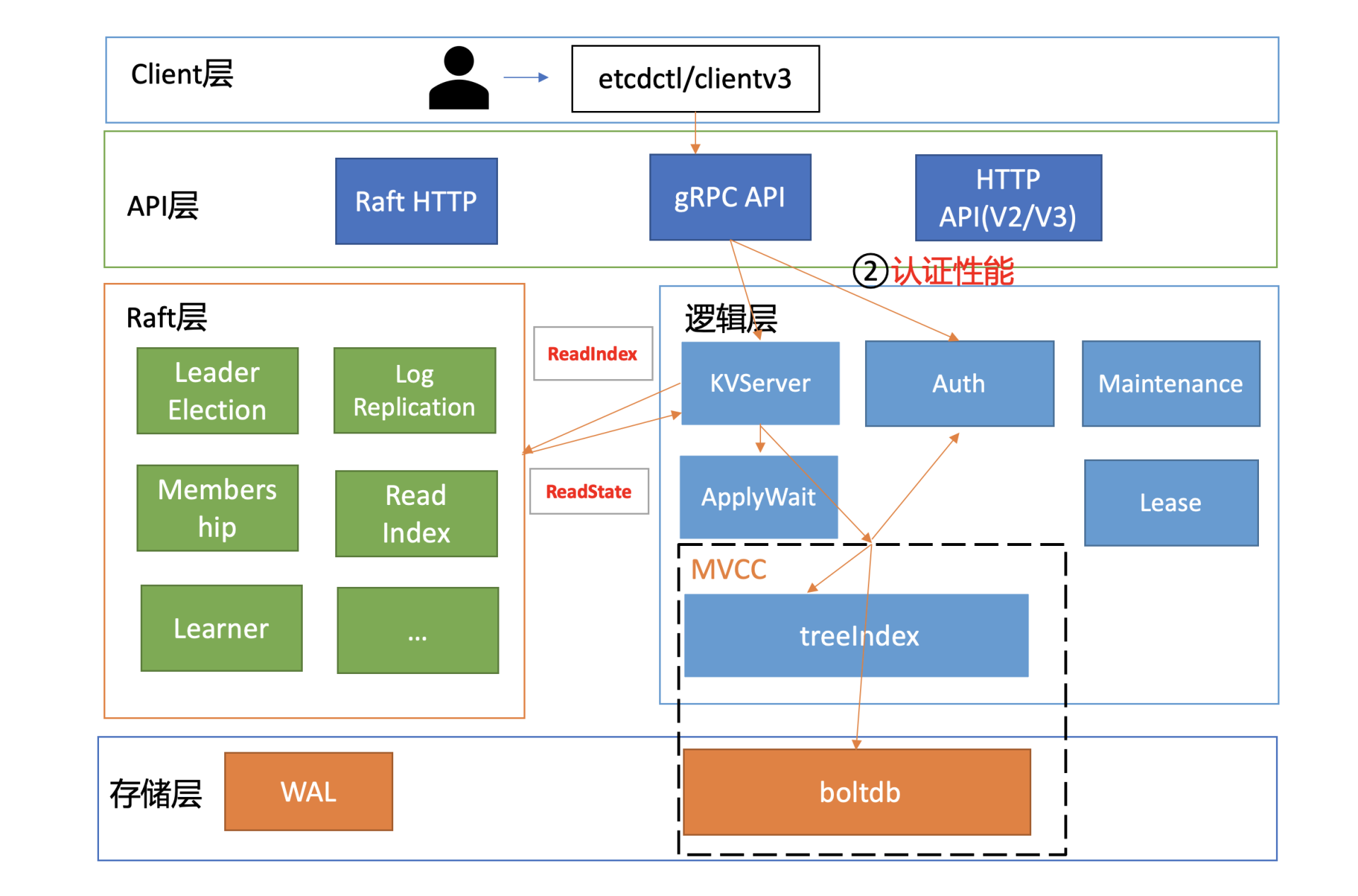
根据我们05介绍的密码认证原理,server节点收到鉴权请求后,它会从boltdb获取此用户密码对应的算法版本、salt、cost值,并基于用户的请求明文密码计算出一个hash值。
在得到hash值后,就可以对比db里保存的hash密码是否与其一致了。如果一致,就会返回一个token给client。 这个token是client访问server节点的通行证,后续server只需要校验“通行证”是否有效即可,无需每次发起昂贵的Authenticate RPC请求。
讲到这里,不知道你有没有意识到,若你的业务在访问etcd过程中未复用token,每次访问etcd都发起一次Authenticate调用,这将是一个非常大的性能瓶颈和隐患。因为正如我们05所介绍的,为了保证密码的安全性,密码认证(Authenticate)的开销非常昂贵,涉及到大量CPU资源。
那这个Authenticate接口究竟有多慢呢?
为了得到Authenticate接口的性能,我们做过这样一个测试:
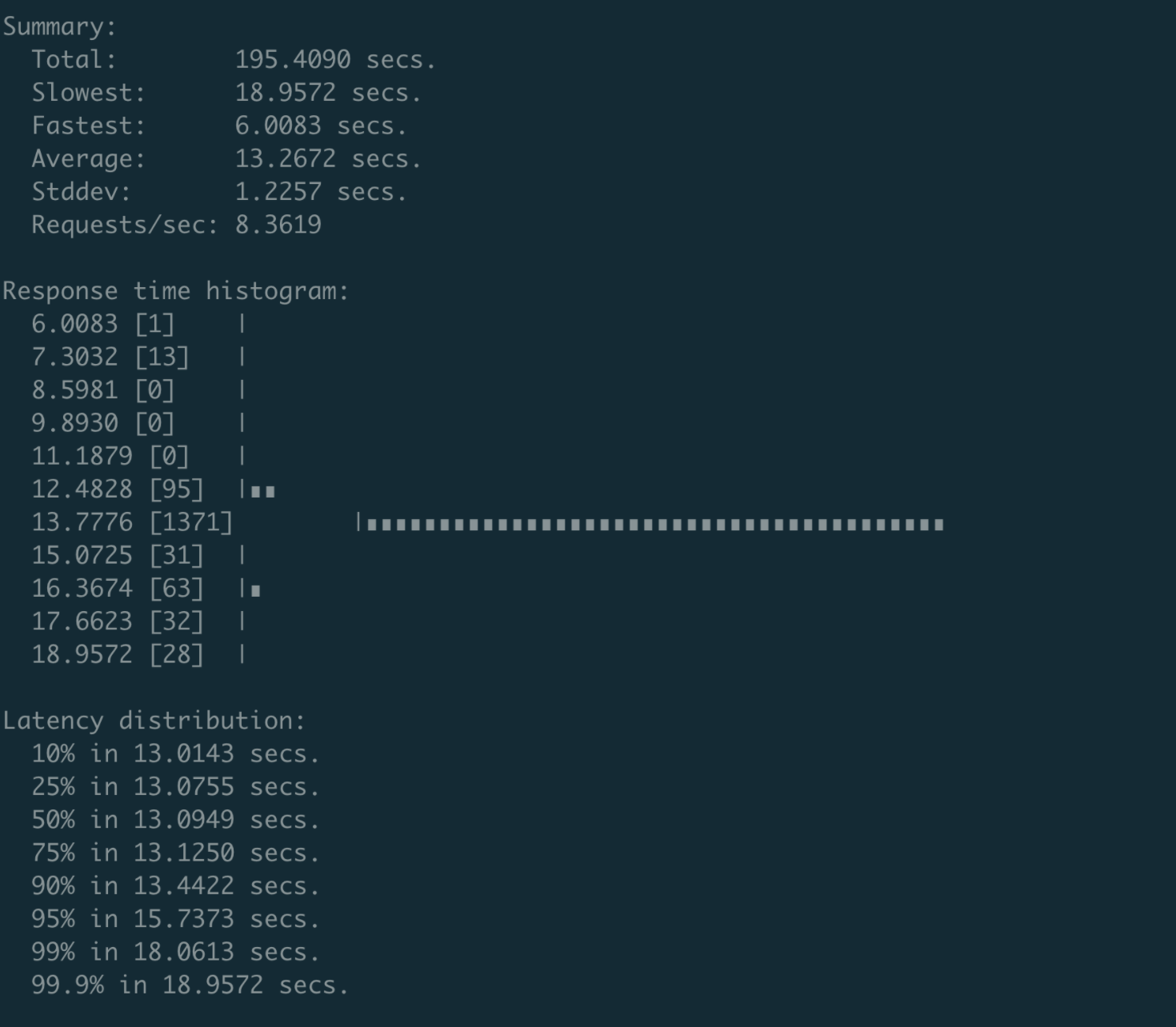
最终的测试结果非常惊人。etcd v3.4.9之前的版本,Authenticate接口性能不到16 QPS,并且随着client和connection增多,该性能会继续恶化。
当client和connection的数量达到200个的时候,性能会下降到8 QPS,P99延时为18秒,如下图所示。
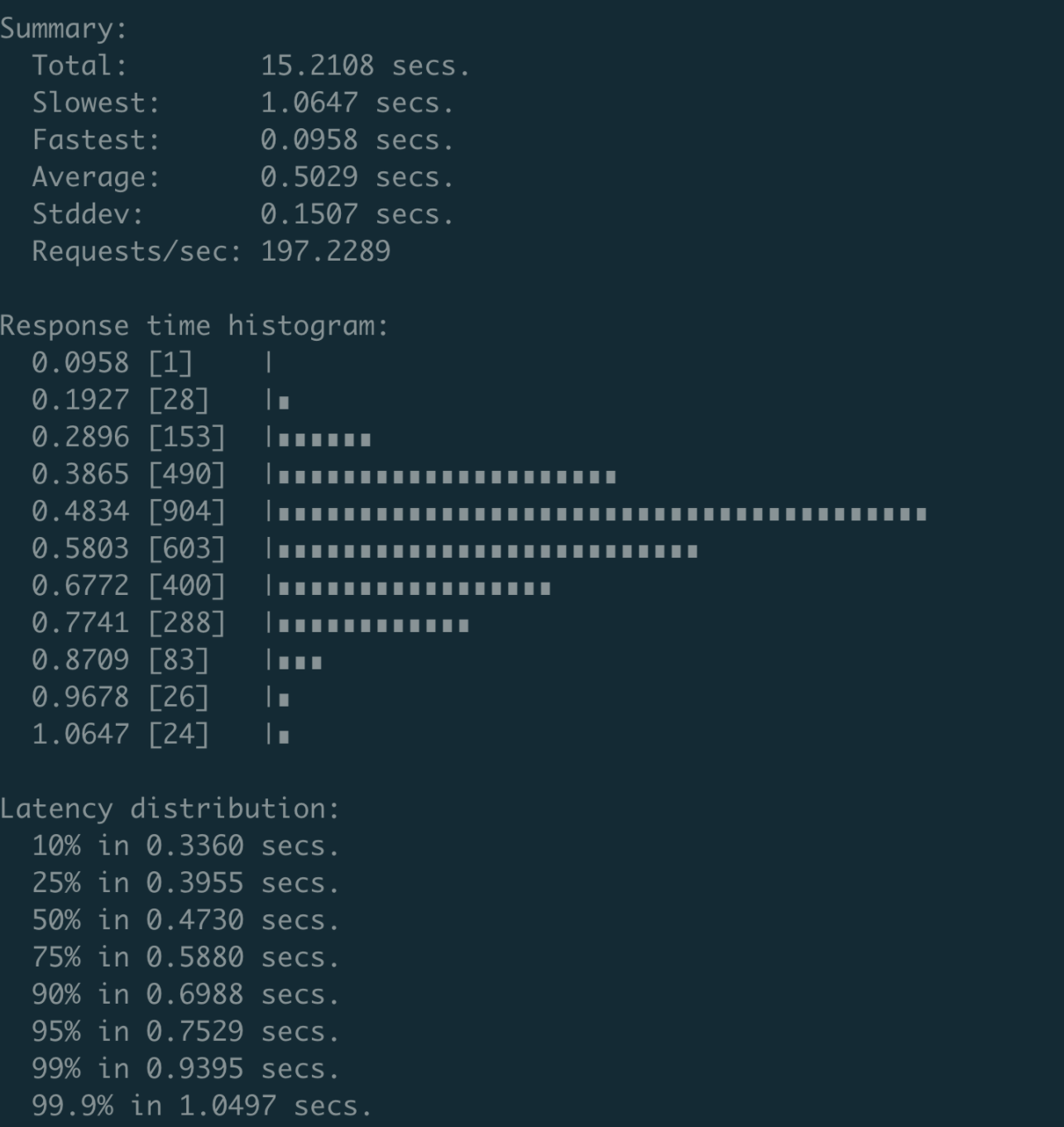
对此,我和小伙伴王超凡通过一个减少锁的范围PR(该PR已经cherry-pick到了etcd 3.4.9版本),将性能优化到了约200 QPS,并且P99延时在1秒内,如下图所示。
由于导致Authenticate接口性能差的核心瓶颈,是在于密码鉴权使用了bcrpt计算hash值,因此Authenticate性能已接近极限。
最令人头疼的是,Auenticate的调用由clientv3库默默发起的,etcd中也没有任何日志记录其耗时等。当大家开启密码鉴权后,遇到读写接口超时的时候,未详细了解etcd的同学就会非常困惑,很难定位超时本质原因。
我曾多次收到小伙伴的求助,协助他们排查etcd异常超时问题。通过metrics定位,我发现这些问题大都是由比较频繁的Authenticate调用导致,只要临时关闭鉴权或升级到etcd v3.4.9版本就可以恢复。
为了帮助大家快速发现Authenticate等特殊类型的expensive request,我在etcd 3.5版本中提交了一个PR,通过gRPC拦截器的机制,当一个请求超过300ms时,就会打印整个请求信息。
讲到这里,你应该会有疑问,密码鉴权的性能如此差,可是业务又需要使用它,我们该怎么解决密码鉴权的性能问题呢?对此,我有三点建议。
第一,如果你的生产环境需要开启鉴权,并且读写QPS较大,那我建议你不要图省事使用密码鉴权。最好使用证书鉴权,这样能完美避坑认证性能差、token过期等问题,性能几乎无损失。
第二,确保你的业务每次发起请求时有复用token机制,尽可能减少Authenticate RPC调用。
第三,如果你使用密码鉴权时遇到性能瓶颈问题,可将etcd升级到3.4.9及以上版本,能适当提升密码鉴权的性能。
client通过server的鉴权后,就可以发起读请求调用了,也就是我们图中的流程三。
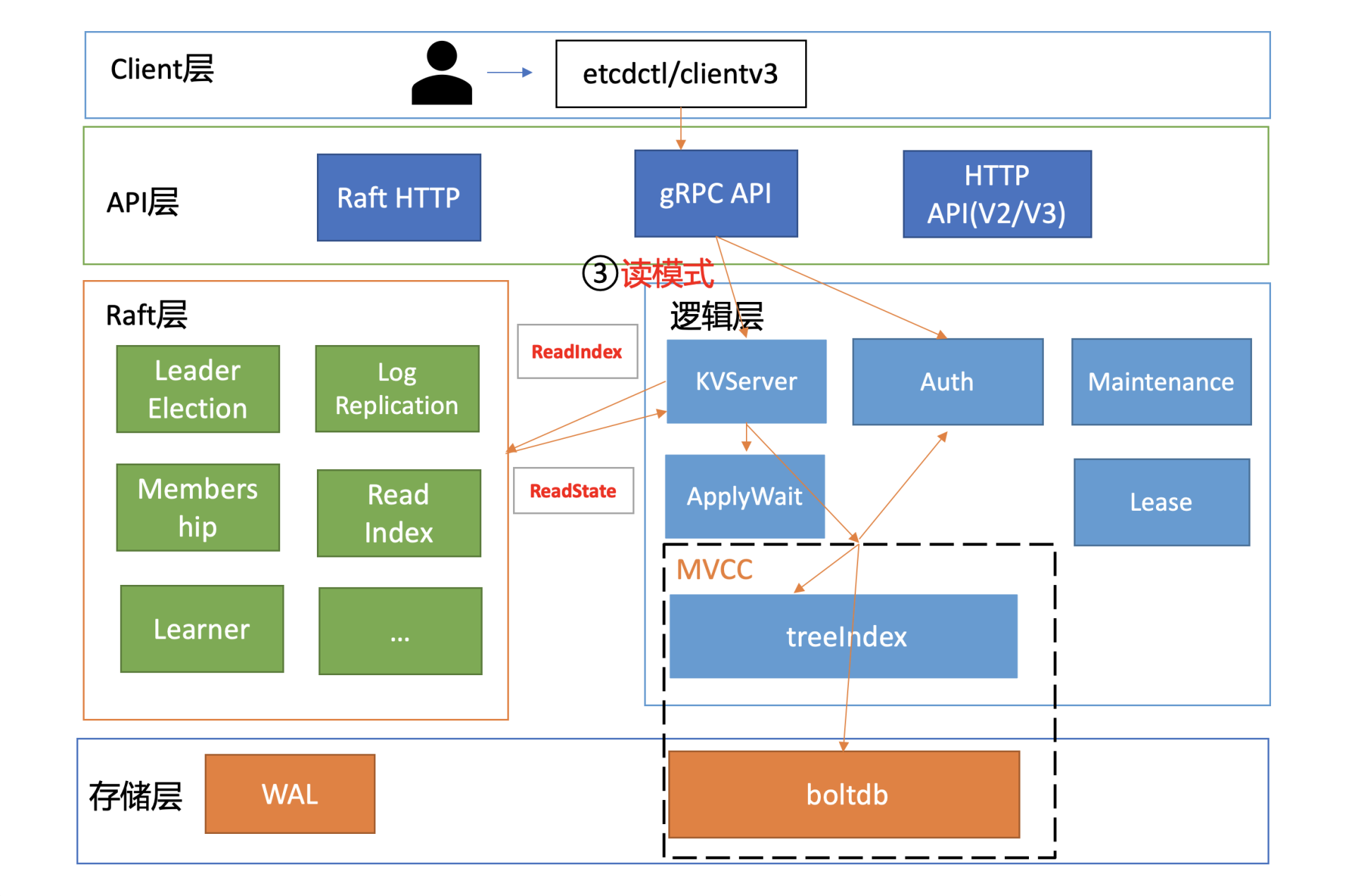
在这个步骤中,读模式对性能有着至关重要的影响。我们前面讲过etcd提供了串行读和线性读两种读模式。前者因为不经过ReadIndex模块,具有低延时、高吞吐量的特点;而后者在牺牲一点延时和吞吐量的基础上,实现了数据的强一致性读。这两种读模式分别为不同场景的读提供了解决方案。
关于串行读和线性读的性能对比,下图我给出了一个测试结果,测试环境如下:
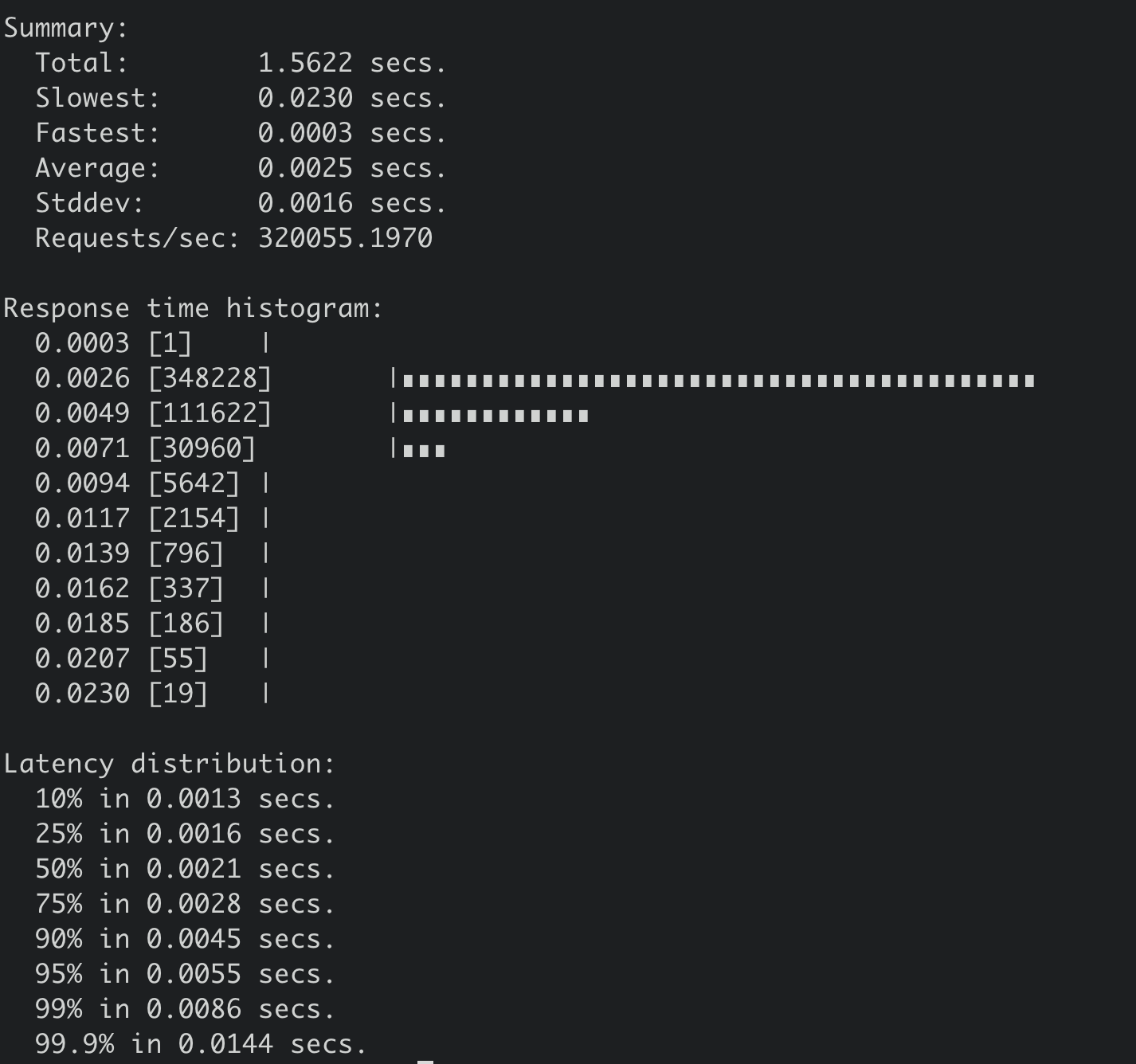
执行如下串行读压测命令:
benchmark --endpoints=addr --conns=100 --clients=1000 \
range hello --consistency=s --total=500000
得到串行读压测结果如下,32万 QPS,平均延时2.5ms。
执行如下线性读压测命令:
benchmark --endpoints=addr --conns=100 --clients=1000 \
range hello --consistency=l --total=500000
得到线性读压测结果如下,19万 QPS,平均延时4.9ms。
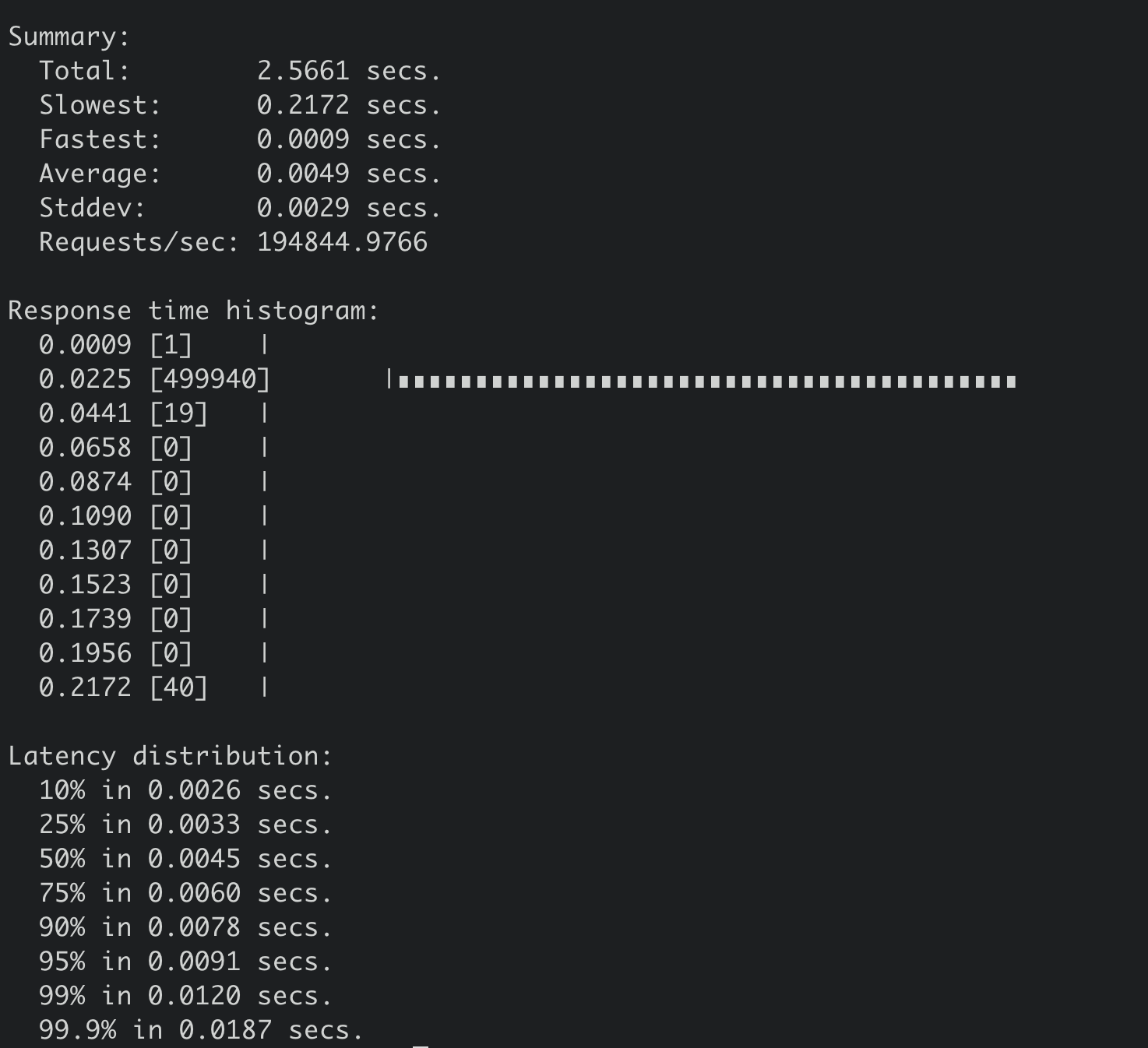
从两个压测结果图中你可以看到,在100个连接时,串行读性能比线性读性能高近11万/s,串行读请求延时(2.5ms)比线性读延时约低一半(4.9ms)。
需要注意的是,以上读性能数据是在1个key、没有任何写请求、同可用区的场景下压测出来的,实际的读性能会随着你的写请求增多而出现显著下降,这也是实际业务场景性能与社区压测结果存在非常大差距的原因之一。所以,我建议你使用etcd benchmark工具在你的etcd集群环境中自测一下,你也可以参考下面的etcd社区压测结果。
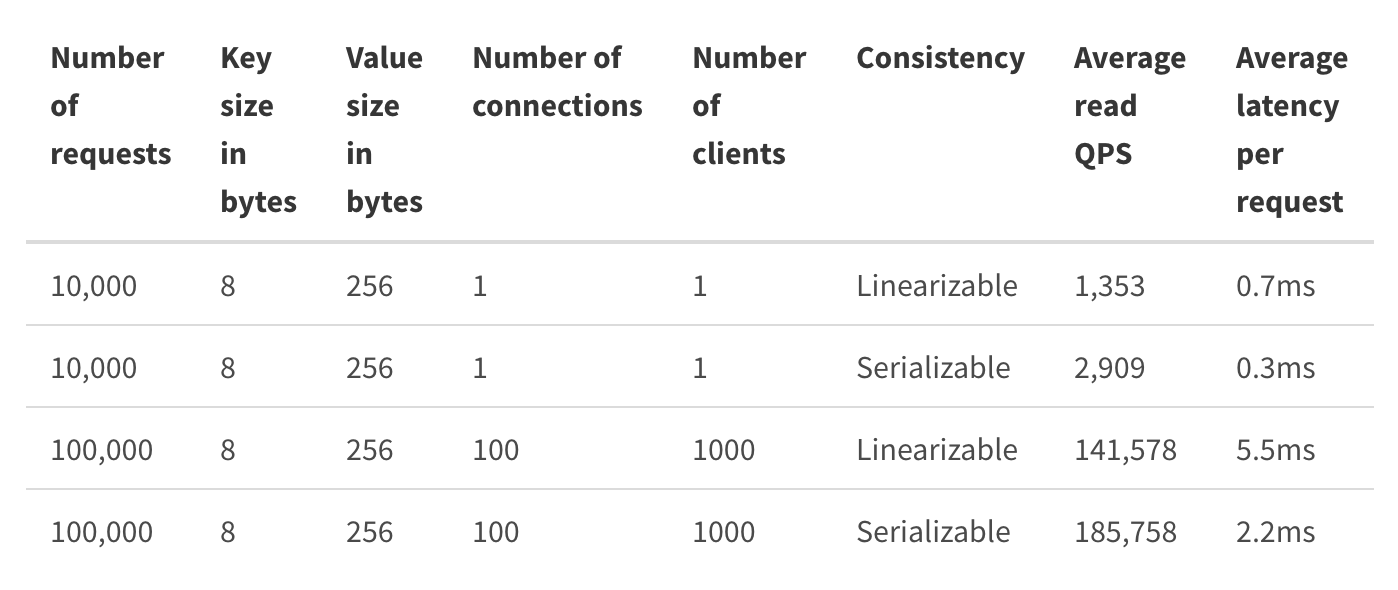
如果你的业务场景读QPS较大,但是你又不想通过etcd proxy等机制来扩展性能,那你可以进一步评估业务场景对数据一致性的要求高不高。如果你可以容忍短暂的不一致,那你可以通过串行读来提升etcd的读性能,也可以部署Learner节点给可能会产生expensive read request的业务使用,实现cheap/expensive read request隔离。
了解完读模式对性能的影响后,我们继续往下分析。在我们这个密码鉴权读请求的性能分析案例中,读请求使用的是etcd默认线性读模式。线性读对应图中的流程四、流程五,其中流程四对应的是ReadIndex,流程五对应的是等待本节点数据追上Leader的进度(ApplyWait)。
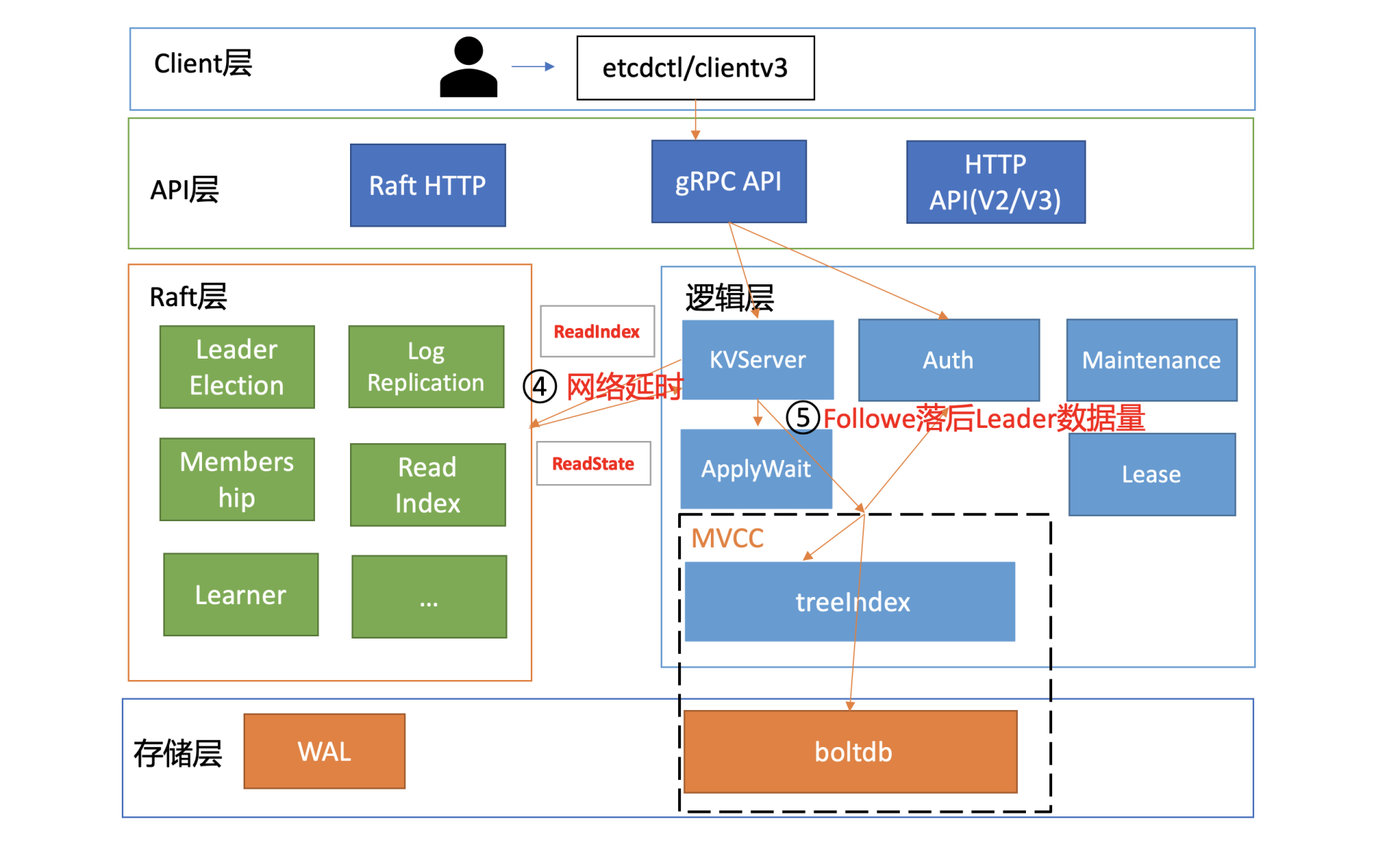
在早期的etcd 3.0版本中,etcd线性读是基于Raft log read实现的。每次读请求要像写请求一样,生成一个Raft日志条目,然后提交给Raft一致性模块处理,基于Raft日志执行的有序性来实现线性读。因为该过程需要经过磁盘I/O,所以性能较差。
为了解决Raft log read的线性读性能瓶颈,etcd 3.1中引入了ReadIndex。ReadIndex仅涉及到各个节点之间网络通信,因此节点之间的RTT延时对其性能有较大影响。虽然同可用区可获取到最佳性能,但是存在单可用区故障风险。如果你想实现高可用区容灾的话,那就必须牺牲一点性能了。
跨可用区部署时,各个可用区之间延时一般在2毫秒内。如果跨城部署,服务性能就会下降较大。所以一般场景下我不建议你跨城部署,你可以通过Learner节点实现异地容灾。如果异地的服务对数据一致性要求不高,那么你甚至可以通过串行读访问Learner节点,来实现就近访问,低延时。
各个节点之间的RTT延时,是决定流程四ReadIndex性能的核心因素之一。
到了流程五,影响性能的核心因素就是磁盘IO延时和写QPS。
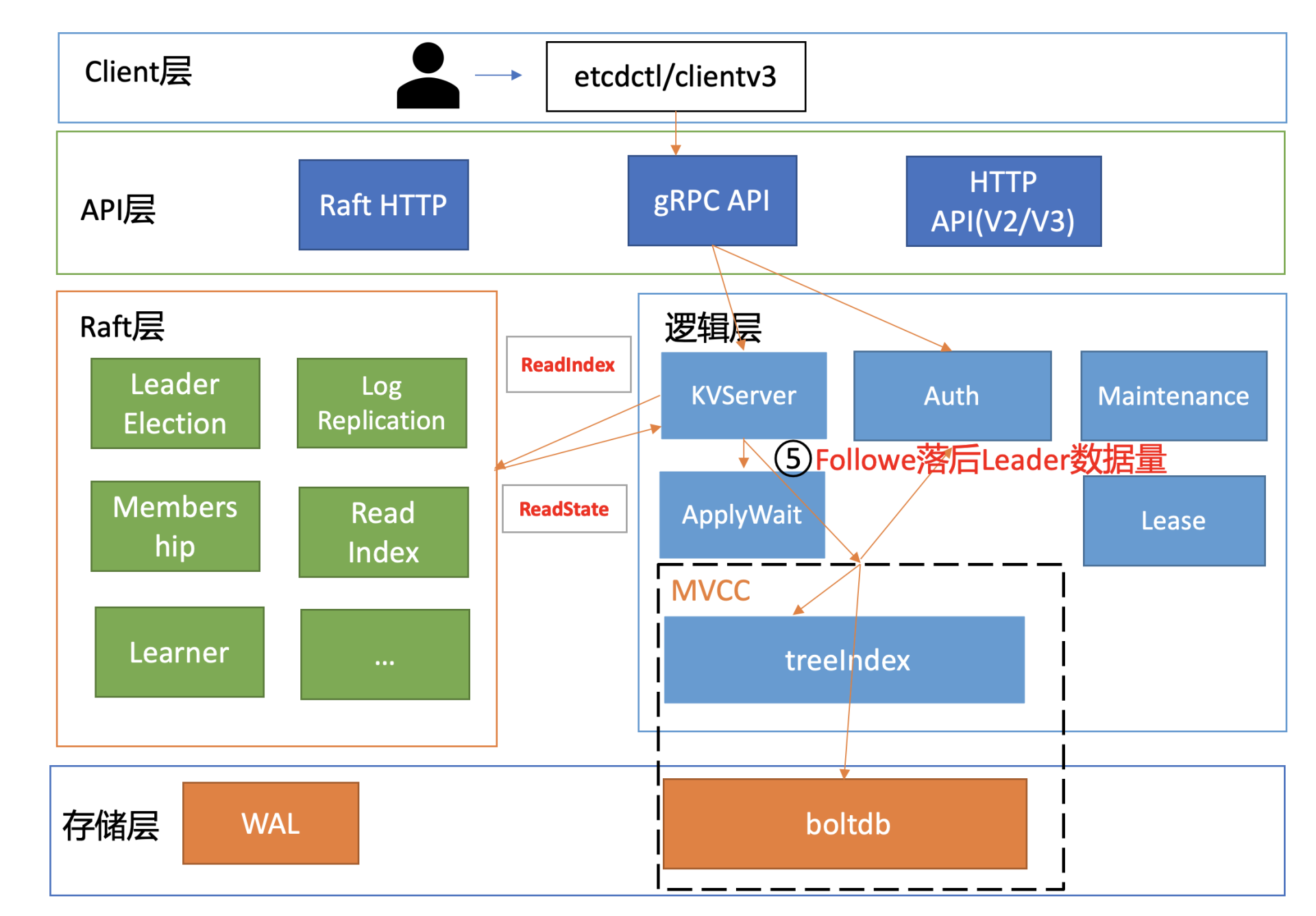
如下面代码所示,流程五是指节点从Leader获取到最新已提交的日志条目索引(rs.Index)后,它需要等待本节点当前已应用的Raft日志索引,大于等于Leader的已提交索引,确保能在本节点状态机中读取到最新数据。
if ai := s.getAppliedIndex(); ai < rs.Index {
select {
case <-s.applyWait.Wait(rs.Index):
case <-s.stopping:
return
}
}
// unblock all l-reads requested at indices before rs.Index
nr.notify(nil)
而应用已提交日志条目到状态机的过程中又涉及到随机写磁盘,详情可参考我们03中介绍过etcd的写请求原理。
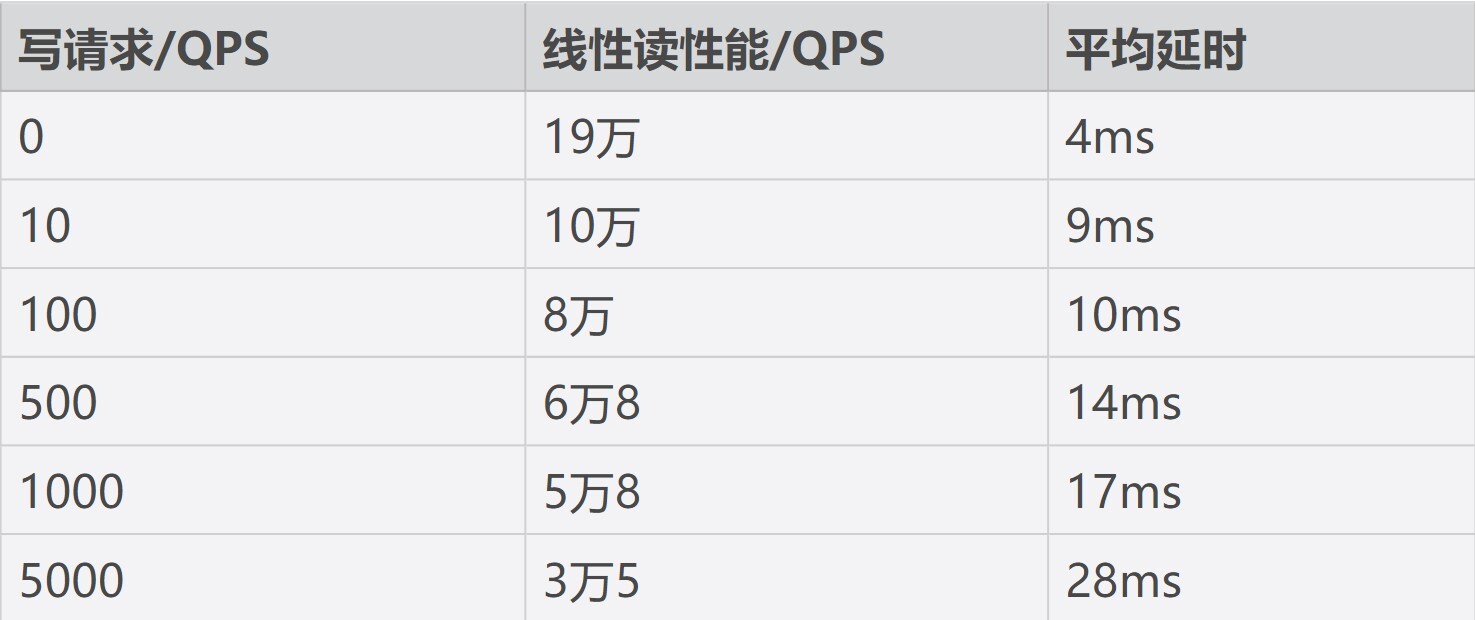
因此我们可以知道,etcd是一个对磁盘IO性能非常敏感的存储系统,磁盘IO性能不仅会影响Leader稳定性、写性能表现,还会影响读性能。线性读性能会随着写性能的增加而快速下降。如果业务对性能、稳定性有较大要求,我建议你尽量使用SSD盘。
下表我给出了一个8核16G的三节点集群,在总key数只有一个的情况下,随着写请求增大,线性读性能下降的趋势总结(基于benchmark工具压测结果),你可以直观感受下读性能是如何随着写性能下降。
当本节点已应用日志条目索引大于等于Leader已提交的日志条目索引后,读请求就会接到通知,就可通过MVCC模块获取数据。
读请求到了MVCC模块后,首先要通过鉴权模块判断此用户是否有权限访问请求的数据路径,也就是流程六。影响流程六的性能因素是你的RBAC规则数和锁。
首先是RBAC规则数,为了解决快速判断用户对指定key范围是否有权限,etcd为每个用户维护了读写权限区间树。基于区间树判断用户访问的范围是否在用户的读写权限区间内,时间复杂度仅需要O(logN)。
另外一个因素则是AuthStore的锁。在etcd 3.4.9之前的,校验密码接口可能会占用较长时间的锁,导致授权接口阻塞。etcd 3.4.9之后合入了缩小锁范围的PR,可一定程度降低授权接口被阻塞的问题。
通过流程六的授权后,则进入流程七,从treeIndex中获取整个查询涉及的key列表版本号信息。在这个流程中,影响其性能的关键因素是treeIndex的总key数、查询的key数、获取treeIndex锁的耗时。
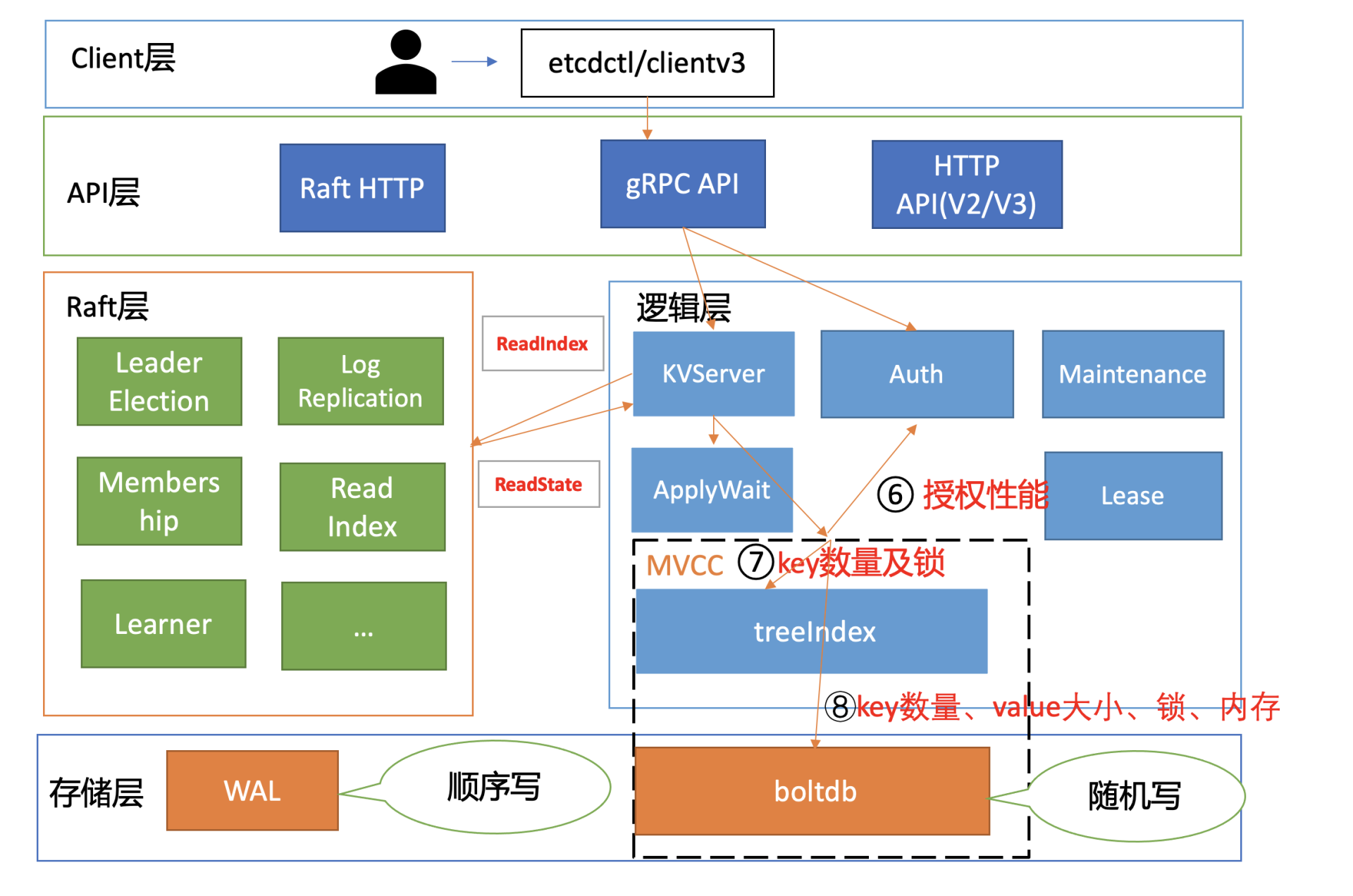
首先,treeIndex中总key数过多会适当增大我们遍历的耗时。
其次,若要访问treeIndex我们必须获取到锁,但是可能其他请求如compact操作也会获取锁。早期的时候,它需要遍历所有索引,然后进行数据压缩工作。这就会导致其他请求阻塞,进而增大延时。
为了解决这个性能问题,优化方案是compact的时候会将treeIndex克隆一份,以空间来换时间,尽量降低锁阻塞带来的超时问题。
接下来我重点给你介绍下查询key数较多等expensive read request时对性能的影响。
假设我们链路分析图中的请求是查询一个Kubernetes集群所有Pod,当你Pod数一百以内的时候可能对etcd影响不大,但是当你Pod数千甚至上万的时候, 流程七、八就会遍历大量的key,导致请求耗时突增、内存上涨、性能急剧下降。你可结合13db大小、14延时、15内存三节一起看看,这里我就不再重复描述。
如果业务就是有这种expensive read request逻辑,我们该如何应对呢?
首先我们可以尽量减少expensive read request次数,在程序启动的时候,只List一次全量数据,然后通过etcd Watch机制去获取增量变更数据。比如Kubernetes的Informer机制,就是典型的优化实践。
其次,在设计上评估是否能进行一些数据分片、拆分等,不同场景使用不同的etcd prefix前缀。比如在Kubernetes中,不要把Pod全部都部署在default命名空间下,尽量根据业务场景按命名空间拆分部署。即便每个场景全量拉取,也只需要遍历自己命名空间下的资源,数据量上将下降一个数量级。
再次,如果你觉得Watch改造大、数据也无法分片,开发麻烦,你可以通过分页机制按批拉取,尽量减少一次性拉取数万条数据。
最后,如果以上方式都不起作用的话,你还可以通过引入cache实现缓存expensive read request的结果,不过应用需维护缓存数据与etcd的一致性。
从流程七获取到key列表及版本号信息后,我们就可以访问boltdb模块,获取key-value信息了。在这个流程中,影响其性能表现的,除了我们上面介绍的expensive read request,还有大key-value和锁。
首先是大key-value。我们知道etcd设计上定位是个小型的元数据存储,它没有数据分片机制,默认db quota只有2G,实践中往往不会超过8G,并且针对每个key-value大小,它也进行了大小限制,默认是1.5MB。
大key-value非常容易导致etcd OOM、server 节点出现丢包、性能急剧下降等。
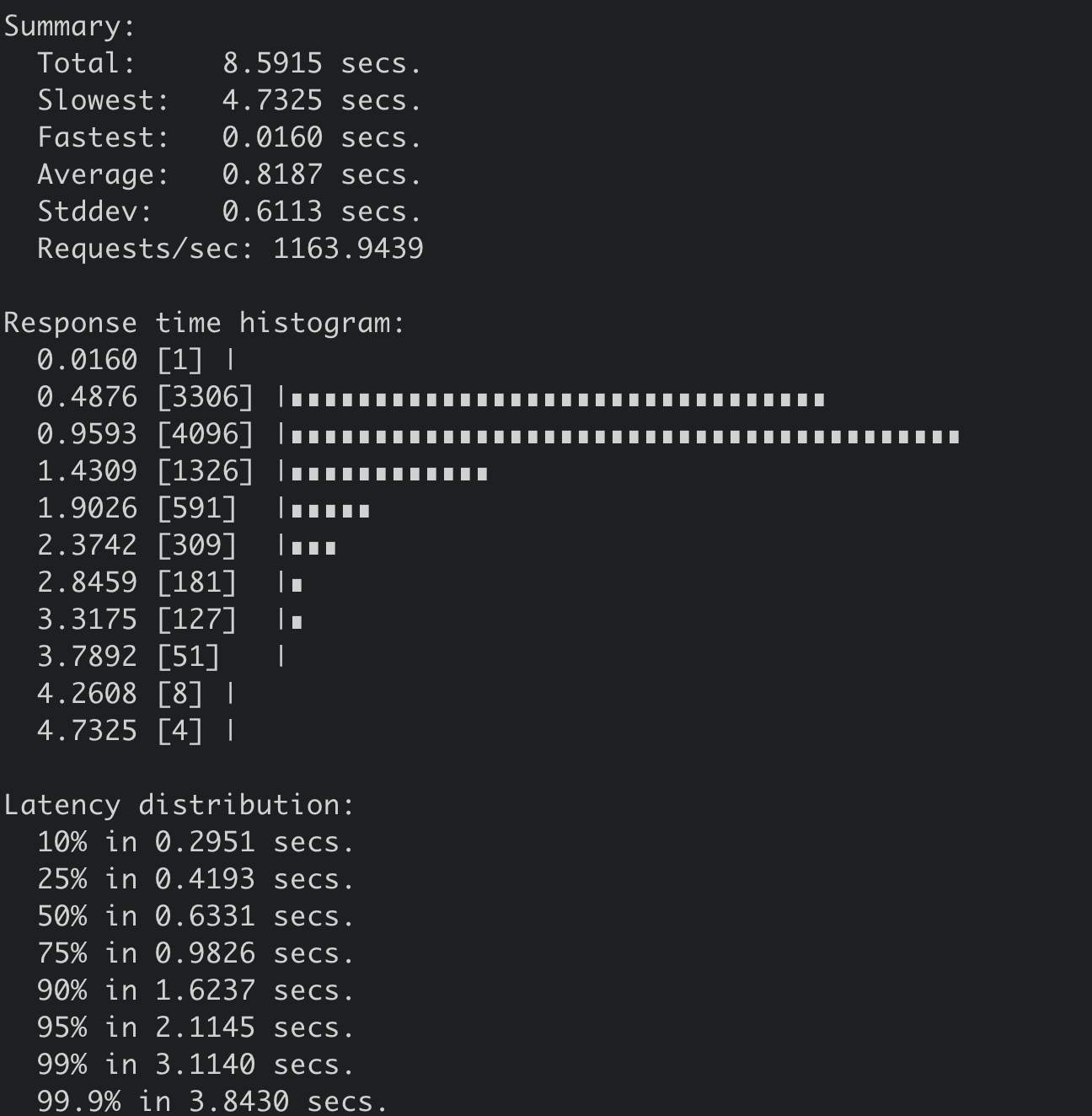
那么当我们往etcd集群写入一个1MB的key-value时,它的线性读性能会从17万QPS具体下降到多少呢?
我们可以执行如下benchmark命令:
benchmark --endpoints=addr --conns=100 --clients=1000 \
range key --consistency=l --total=10000
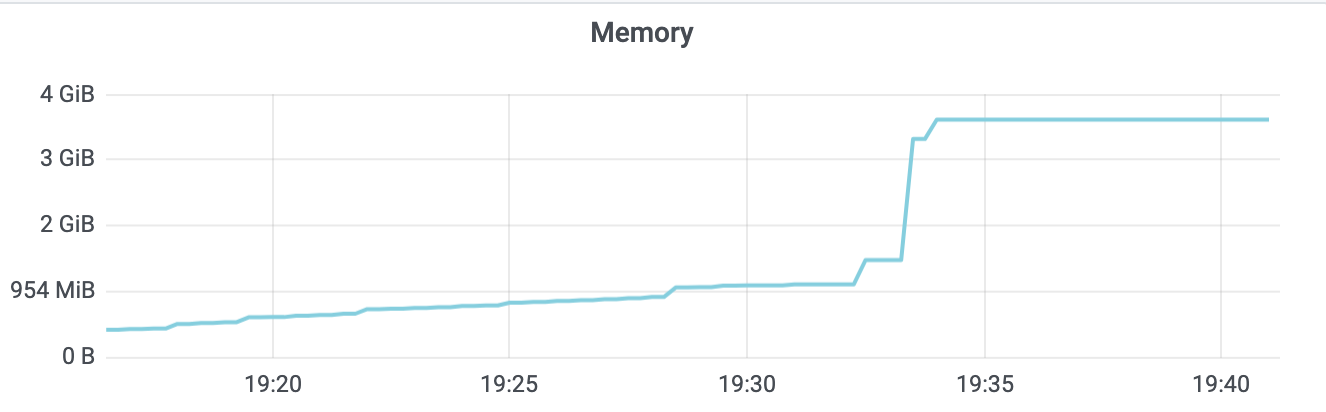
得到其结果如下,从下图你可以看到,读取一个1MB的key-value,线性读性能QPS下降到1163,平均延时上升到818ms,可见大key-value对性能的巨大影响。
同时,从下面的etcd监控图上你也可以看到内存出现了突增,若存在大量大key-value时,可想而知,etcd内存肯定暴涨,大概率会OOM。
其次是锁,etcd为了提升boltdb读的性能,从etcd 3.1到etcd 3.4版本,分别进行过几次重大优化,在下一节中我将和你介绍。
以上就是一个开启密码鉴权场景,线性读请求的性能瓶颈分析过程。
今天我通过从上至下的请求流程分析,介绍了各个流程中可能存在的瓶颈和优化方法、最佳实践等。
优化读性能的核心思路是首先我们可通过etcd clientv3自带的Round-robin负载均衡算法或者Load Balancer,尽量确保整个集群负载均衡。
然后,在开启鉴权场景时,建议你尽量使用证书而不是密码认证,避免校验密码的昂贵开销。
其次,根据业务场景选择合适的读模式,串行读比线性度性能提高30%以上,延时降低一倍。线性读性能受节点之间RTT延时、磁盘IO延时、当前写QPS等多重因素影响。
最容易被大家忽视的就是写QPS对读QPS的影响,我通过一系列压测数据,整理成一个表格,让你更直观感受写QPS对读性能的影响。多可用区部署会导致节点RTT延时增高,读性能下降。因此你需要在高可用和高性能上做取舍和平衡。
最后在访问数据前,你的读性能还可能会受授权性能、expensive read request、treeIndex及boltdb的锁等影响。你需要遵循最佳实践,避免一个请求查询大量key、大key-value等,否则会导致读性能剧烈下降。
希望你通过本文当遇到读etcd性能问题时,能从请求执行链路去分析瓶颈,解决问题,让业务和etcd跑得更稳、更快。
你在使用etcd过程中遇到了哪些读性能问题?又是如何解决的呢?
欢迎分享你的性能优化经历,感谢你阅读,也欢迎你把这篇文章分享给更多的朋友一起阅读。
评论