
你好,我是徐文浩。在前面的两讲中,我们一起探讨了GFS系统设计中秉持的两个原则,分别是“保持简单”和“根据硬件特性设计系统”,而今天我们要讨论的GFS的最后一个设计特点,是“放宽数据一致性的要求”。
分布式系统的一致性要求是一个很有挑战的话题。如果说分布式系统天生通过更多的服务器提升了性能,是一个天然的优点,那么在这些通过网络连起来的服务器之间保持数据一致,就是一个巨大的挑战。毕竟网络传输总有延时,硬件总会有故障,你的程序稍有不慎,就会遇到甲服务器觉得你的钱转账失败,而乙服务器却觉得钱已经转走了的情况。可以说,一致性是分布式系统里的一个永恒的话题。
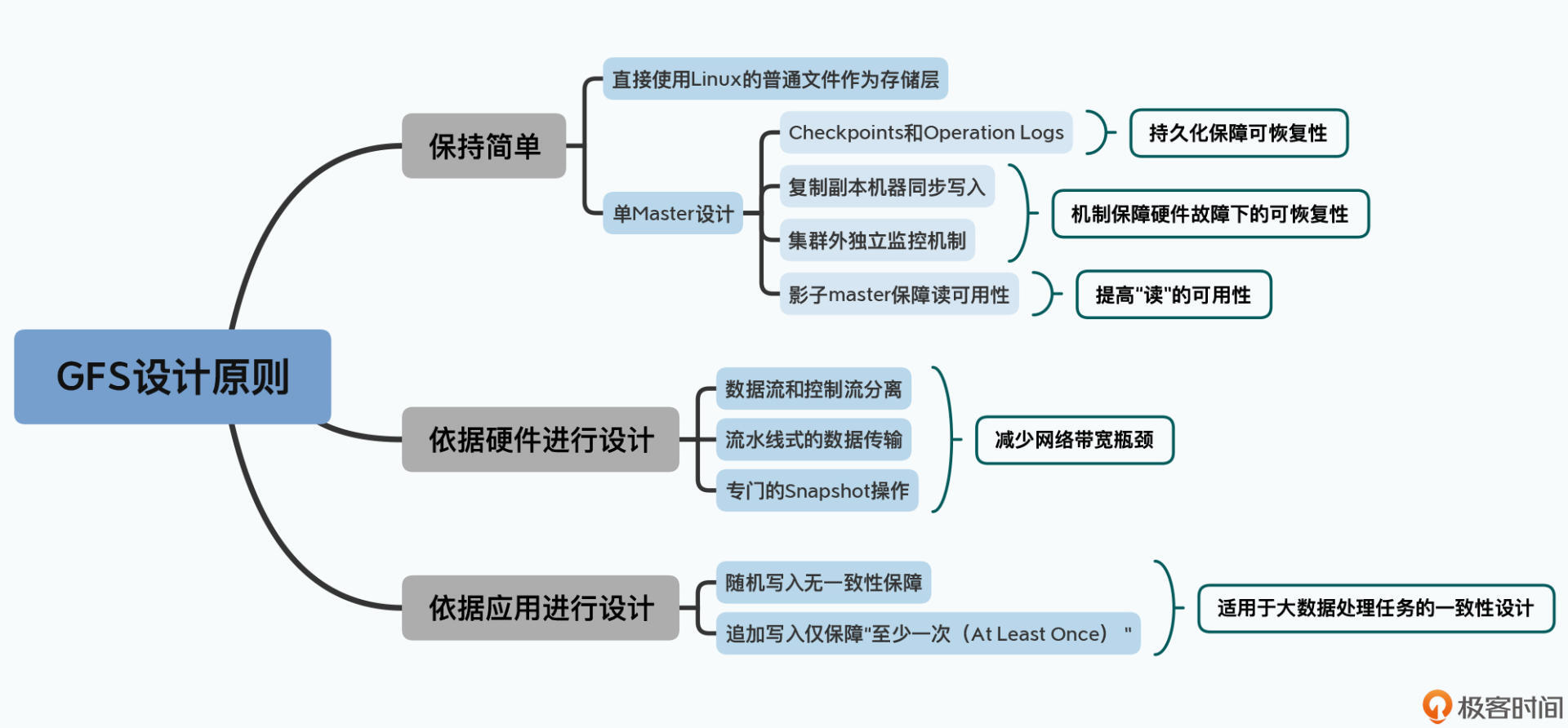
不过2003年的GFS,对于一致性的要求,是非常宽松的。一方面,这是为了遵循第一个设计原则,就是“保持简单”,简单的设计使得做到很强的一致性变得困难。另一方面,则是要考虑“硬件特性”,GFS希望在机械硬盘上尽量有比较高的写入性能,所以它只对顺序写入考虑了一致性,这就自然带来了宽松的一致性。
好,废话不多说,让我们切入正题。
通过上一讲的学习,我们知道了在GFS中,客户端是怎么把数据写入到文件系统里的。不过,我们并没有探讨一个非常重要的问题,就是数据写入的一致性(Consistency)问题。这个一致性,也是我们常常听说的CAP理论中的C,即一致性、可用性、分区容错性在分布式系统中,三者不能兼得中的一致性问题。这个C,也正来自于一致性的英文Consitency的首字母。
我们先来看看,一致性到底指的是什么东西。在GFS里面,主要定义了对一致性的两个层级的概念:

现在,我们来看看GFS的论文里留的一个表格,其中告诉了我们GFS对于数据写入的一致性问题。
这个很容易理解,GFS里面的数据写入,并不是一个事务。上一讲里说过,主副本会把写入指令下发到两个次副本,如果次副本写入失败了,它会告诉主副本。但是,此时主副本和另一个次副本都已经写入成功了。那么这个时候,GFS里的三个副本的数据,就是不一致的了。不同的客户端,就可能读到不同的数据。
比如,你先往一个文件里,写入一部电影《星球大战》,这个时候,客户端无论从哪个副本读数据,读到的都是星球大战。然后再写入《星际迷航》,那么客户端再读数据,读到的也一定是《星际迷航》。
也就是说,两个客户端并发往一个文件里面写数据,一个想要写入《星球大战》,一个想要写入《星际迷航》,两个写入都成功了。这个时候,GFS里面三份副本的数据是一样的,客户端读到的数据无论是从哪个副本里读,都是一样的。
但是呢,客户端可能读出来的数据里,前一小时是《星球大战》,后一小时是《星际迷航》。无论哪个时间节点去读数据,客户端都不能读到一部完整的《星球大战》,或者是《星际迷航》。

那么,为什么GFS的数据写入会出现一致但是非确定的状态呢?这个来自于两个因素。
第一种因素是在GFS的数据读写中,为了减轻Master的负载,数据的写入顺序并不需要通过Master来进行协调,而是直接由存储了主副本的chunkserver,来管理同一个chunk下数据写入的操作顺序。
第二种因素是随机的数据写入极有可能要跨越多个chunk。
我们在写入《星球大战》和《星际迷航》的时候,前一个小时的电影是在chunk 1,对应的主副本在server A,后一个小时的电影是在chunk 2,对应的主副本在server B。然后写入请求到server A的时候,《星际迷航》在前,《星球大战》在后,那么《星球大战》的数据就覆盖了《星际迷航》。
而到server B的时候则是反过来,《星际迷航》又覆盖了《星球大战》。于是,就会出现客户端读数据,前半段是《星球大战》,后半段是《星际迷航》的奇怪现象了。
其实,这个一致但是非确定的状态,是因为随机的数据写入,没有原子性(Atomic)或者事务性(Transactional)。如果想要随机修改GFS上的数据,一般会建议使用方在客户端的应用层面,保障数据写入是顺序的,从而可以避免并发写入的出现。
看到这里,你可能要纳闷了。不是说GFS支持几百个客户端并发读写吗?现在怎么又说,写入要客户端自己保障是“顺序”的呢?
实际上,这是因为随机写入并不是GFS设计的主要的数据写入模式,GFS设计了一个专门的操作,叫做记录追加(Record Appends)。这是GFS希望我们主要使用的数据写入的方式,而且它是原子性(Atomic)的,能够做到在并发写入时候是基本确定的。
不过,作为一个严谨的工程师,听到“基本”这两个字你可能心里一颤。别慌,接下来我就带你一起看一下,这个基本到底是怎么回事儿。
GFS的记录追加的写入过程,和上一讲的数据写入几乎一样。它们之间的差别主要在于,GFS并不会指定在chunk的哪个位置上写入数据,而是告诉最后一个chunk所在的主副本服务器,“我”要进行记录追加。
这个时候,主副本所在的chunkserver会做这样几件事情:

那么到了这里,你可能要问了:如果在主副本上写入成功了,但是在次副本上写入失败了怎么办呢?这样不是还会出现数据不一致的情况吗?
其实在这个时候,主副本会告诉客户端数据写入失败,然后让客户端重试。不过客户端发起的重试,并不是在原来的位置去写入数据,而是发起一个新的记录追加操作。这个时候,可能已经有其他的并发追加写入请求成功了,那么这次重试会写入到更后面。
我们可以一起来看这样一个例子:有三个客户端X、Y、Z并发向同一个文件进行记录追加,写入数据A、B、C,对应的三个副本的chunkserver分别是Q、P、R。
主副本先收到数据A的记录追加,在主副本和次副本上进行数据写入。在A写入的同时,B,C的记录追加请求也来了,这个时候写入会并行进行,追加在A的后面。
这个时候,A的写入在某个次副本R上失败了,于是主副本告诉客户端去重试;同时,客户端再次发起记录追加的重试,这次的数据写入,不在A原来的位置,而会是在C后面。
如此一来,在B和C的写入,以及A的重试完成之后,我们可以看到:
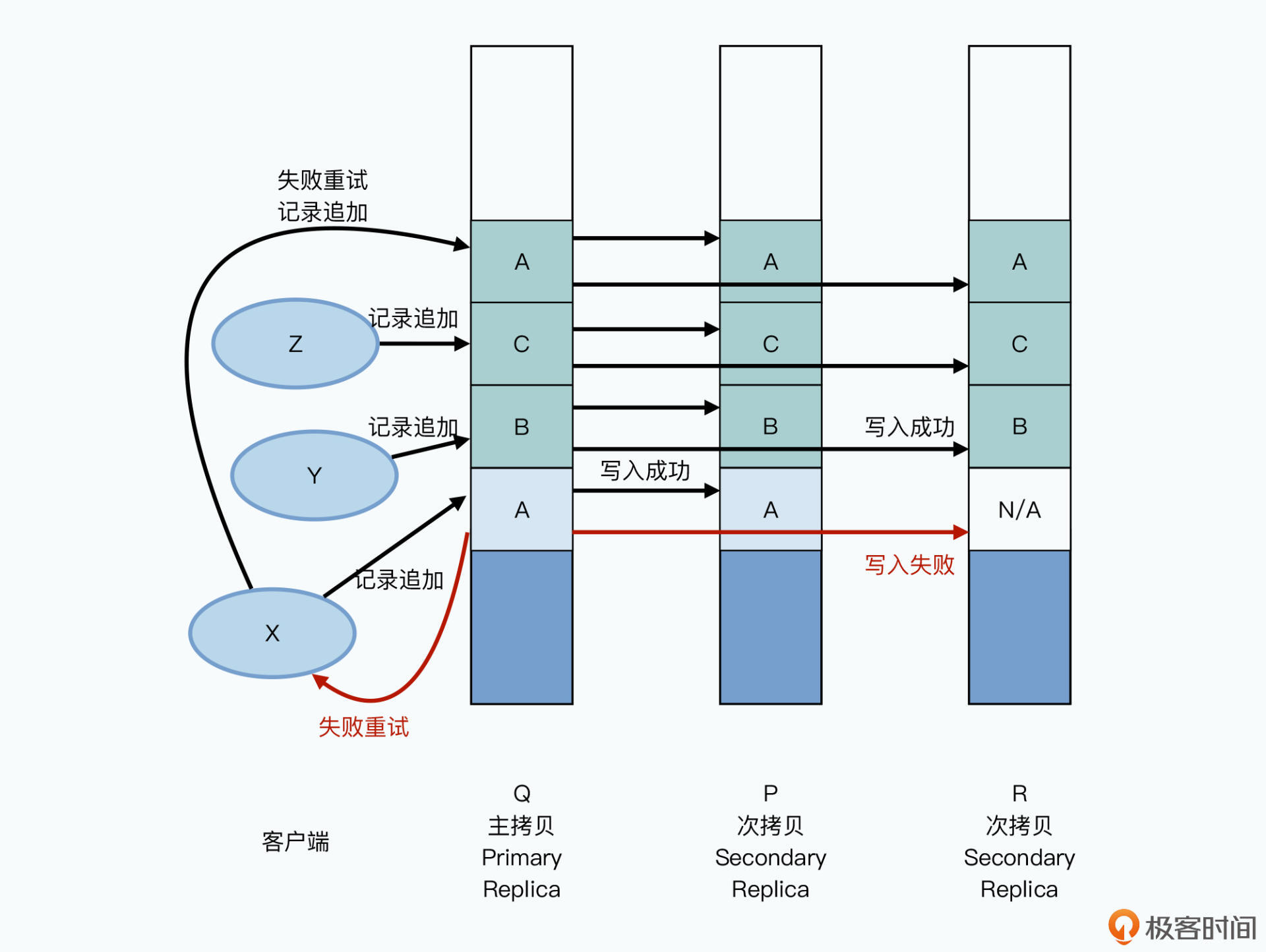
所以在这个记录追加的场景下,GFS承诺的一致性,叫做“至少一次(At Least Once)”。也就是写入一份数据A,在重试的情况下,至少会完整地在三个副本的同一个位置写入一次。但是也可能会因为失败,在某些副本里面写入多次。那么,在不断追加数据的情况下,你会看到大部分数据都是一致的,并且是确定的,但是整个文件中,会夹杂着少数不一致也不确定的数据。
看到这里,你发现没有,GFS的写入数据的一致性保障是相当低的。它只是保障了所有数据追加至少被写入一次,并且还保障不了数据追加的顺序。这使得客户端读取到的副本中,可能也会存在重复的数据或者空的填充数据,这样的文件系统实在不咋样。
不过,这个“至少一次”的机制,其实很适合Google的应用场景。你想像一下,如果你是一个搜索引擎,不断抓取网页然后存到GFS上。其实你并不会太在意这个网页信息是不是被重复存了两次,你也不太会在意不同的两个网页存储的顺序。而且即使你在意这两点,比如你存的不是网页,而是用户的搜索日志或广告展示和点击的日志数据。或者你担心数据写入失败,带来的是部分不完整的数据,也有很多简单的解决办法。
事实上,GFS的客户端里面自带了对写入的数据去添加校验和(checksum),并在读取的时候计算来验证数据完整性的功能。而对于数据可能重复写入多次的问题,你也可以对每一条要写入的数据生成一个唯一的ID,并且在里面带上当时的时间戳。这样,即使这些日志顺序不对、有重复,你也可以很容易地在你后续的数据处理程序中,通过这个ID进行排序和去重。
而这个“至少一次”的写入模型也带来了两个巨大的好处。
第一是高并发和高性能,这个设计使得我们可以有很多个客户端并发向同一个GFS上的文件进行追加写入,而高性能本身也是我们需要分布式系统的起点。
第二是简单,GFS采用了一个非常简单的单master server,多个chunkserver架构,所有的协调动作都由master来做,而不需要复杂的一致性模型。毕竟,2003年我们只有极其难以读懂的Paxos论文,Raft这样的分布式共识算法要在10年之后的2013年才会诞生。而简单的架构设计,使得系统不容易出Bug,出了各种Bug也更容易维护。
而即使GFS里的数据随机写入能够保障确定性,在那个年代的实用价值也不高。因为那个时候,大家用的还都是5400转,或者7200转的机械硬盘。如果你读过我的《深入浅出计算机组成原理》,你一定还记得机械硬盘的IOPS也就是在70左右,几百个客户端要是并发写入一个位置,硬盘根本抗不住。
对于随机数据写入的一致性,我会在后面Bigtable的论文里,再带你看看Google是如何在这个不可靠的GFS上,架起一个高可用性、可以随机读写的KV数据库。
好了,到这里,我们通过三讲把GFS的论文讲完了。在今天的最后一讲中,我们深入剖析了GFS非常宽松的一致性模型。对于随机数据写入,GFS针对成功的并发写入,只保障一致性,但是不保障确定性。
而对于记录追加这样专门设计出来的操作,GFS也只保障“至少一次”的写入,避免不了确定的数据中,夹杂着不一致和不确定的脏数据。而这些数据,都需要你通过校验和乃至应用层自行去重来进行处理。这些设计和机制,都是和GFS面临的应用场景所匹配的,即高并发大量追加写入新的日志、网页、生成的索引等等的应用场景。
回顾过去三讲,我们可以看到GFS的设计原则,就是简单、围绕硬件性能设计,以及在这两个前提下对于一致性的宽松要求。可以说,GFS不是一个“黑科技”系统,而是一个非常优秀的工程化系统。在后面的MapReduce以及Bigtable的论文中,我们还会反复看到类似的设计选择。
今天我们所讲的,其实是在大数据及分布式领域中一个非常重要的主题,那就是CAP问题。在之后的很多论文里,你也可以看到不同系统是如何处理CAP问题带来的挑战的。在学完今天这节课之后,我比较推荐你去读一读2012年,在CAP理论发表12年后,作者埃里克·布鲁尔(Eric Brewer)对CAP问题的回顾文章《CAP理论十二年回顾:“规则”变了》。
最后,我们还是来针对今天所学的内容,来思考一个简单的问题:GFS的文件,只能保障“至少一次”的追加写入。那么,如果我们通过GFS的客户端要写入一部电影到GFS,然后过一阵再读出来,我们都可以有哪些方式,来保障这个电影读取之后能够正常播放呢?
无论是在读、还是写、还是播放的时候进行技术处理的方法,你都可以在留言区提出来,我们一起讨论。如果觉得有收获,欢迎你把今天的内容分享给更多的朋友。