你好,我是徐文浩。上一讲里我们一起分析了如何对一个MySQL集群进行扩容,来支撑更高的随机读写请求。而在扩容过程中遇到的种种不便,也让我们深入理解了Bigtable的设计中需要重点解决的问题。
第一个问题,自然还是如何支撑好每秒十万、乃至百万级别的随机读写请求。
第二个问题,则是如何解决好“可伸缩性”和“可运维性”的问题。在一个上千台服务器的集群上,Bigtable怎么能够做到自动分片和灾难恢复。
今天我们就先来看看第二个问题,其实也是Bigtable的整体架构。而第一个问题,一半要依赖第二个问题,也就是可以不断将集群扩容到成百上千个节点。另一半,则取决于在每一个节点上,Bigtable的读写操作是怎么进行的,这一部分我们会放到下一讲,也就是Bigtable的底层存储SSTable究竟是怎么一回事儿。
那么接下来,我们就一起来看看Bigtable的整体架构。在学完这一讲后,希望你可以掌握Bigtable三个重要的知识点:
相信在学完这一讲后,你也能自己设计一个分布式数据库的基本架构。并且,你也会对分布式数据库设计的分区和复制机制、系统整体架构设计,以及如何分析和优化整个架构的瓶颈所在,有一个清晰的了解。
在进入到针对Bigtable的架构设计解读之前,我们先来弄清楚Bigtable基本的数据模型。
上一讲里,我们举了很多MySQL的例子。在这个过程中,相信你会发现,一旦我们开始分库分表了,我们就很难使用关系数据库的一系列的特性了。比如SQL里面的Join功能,或者是跨行的事务。因为这些功能在分库分表的场景下,都要涉及到多台服务器,不是说做不到,但是问题一下子就复杂了。
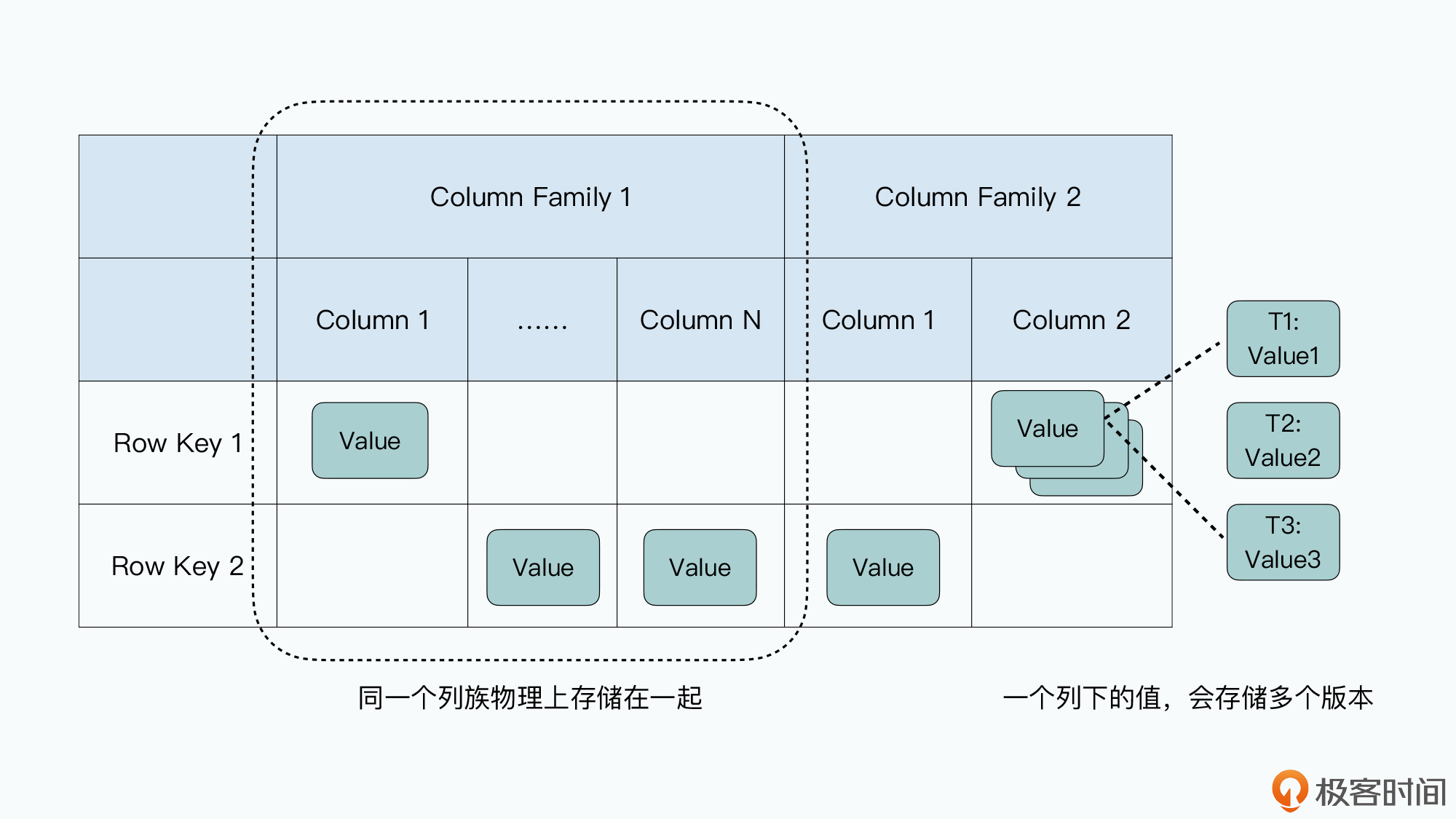
所以,Bigtable在一开始,也不准备先考虑事务、Join等高级的功能,而是把核心放在了“可伸缩性”上。因此,Bigtable自己的数据模型也特别简单,是一个很宽的稀疏表。
每一张Bigtable的表都特别简单,每一行就是一条数据:
其实,这里的有些命名容易让人误解,比如列族,这个名字很容易让人误解Bigtable是一个基于列存储的数据库。但事实完全不是这样,我觉得对于列族,更合理的解读是,它是一张“物理表”,同一个列族下的数据会在物理上存储在一起。而整个表,是一张“逻辑表”。
在现实当中,Bigtable的开源实现HBase,就是把每一个列族的数据存储在同一个HFile文件里。而在Bigtable的论文中,Google定义了一个叫做本地组(Locality Group)的概念,我们可以把多个列族放在同一个本地组中,而同一个本地组的所有列的数据,都会存储在同一个SSTable文件里。
这个设计,就使得我们不需要针对字段多的数据表,像MySQL那样,进行纵向拆表了。
Bigtable的这个数据模型,使得我们能很容易地去增加列,而且增加列并不算是修改Bigtable里一张表的Schema,而是在某些这个列需要有值的行里面,直接写入数据就好了。这里的列和值,其实是直接以key-value键值对的形式直接存储下来的。
这个灵活、稀疏而又宽的表,特别适合早期的互联网业务。虽然数据量很大,但是数据本身的Schema我们可能没有想清楚,加减字段都不需要停机或者锁表。要知道,MySQL直到5.5版本,用ALTER命令修改表结构仍然需要将整张表锁住。并且在锁住这张表的时候,我们是不能往表里写数据的。对于一张数据量很大的表来说,这会让整张表有很长一段时间不能写入数据。
而Bigtable这个稀疏列的设计,就为我们带来了很大的灵活性,如同《架构整洁之道》的作者Uncle Bob说的那样:“架构师的工作不是作出决策,而是尽可能久地推迟决策,在现在不作出重大决策的情况下构建程序,以便以后有足够信息时再作出决策。”
搞清楚了Bigtable的数据模型,我们再来一起看一看,Bigtable是怎么解决上一讲MySQL集群解决不好的水平分库问题的。
把一个数据表,根据主键的不同,拆分到多个不同的服务器上,在分布式数据库里被称之为数据分区( Paritioning)。分区之后的每一片数据,在不同的分布式系统里有不同的名字,在MySQL里呢,我们一般叫做Shard,Bigtable里则叫做Tablet。
上一讲里,MySQL集群的分区之所以遇到种种困难,是因为我们通过取模函数来进行分区,也就是所谓的哈希分区。我们会拿一个字段哈希取模,然后划分到预先定好N个分片里面。这里最大的问题,在于分区需要在一开始就设计好,而不是自动随我们的数据变化动态调整的。
但是往往计划不如变化快,当我们的业务变化和计划稍有不同,就会遇到需要搬运数据或者各个分片负载不均衡的情况。你可以看一下我从上一讲里搬过来的这张图,当我们将4台服务器扩展到6台服务器的时候,哈希分区的方式使得我们要在网络上搬运整个数据库2/3的数据。

所以,在Bigtable里,我们就采用了另外一种分区方式,也就是动态区间分区。我们不再是一开始就定义好需要多少个机器,应该怎么分区,而是采用了一种自动去“分裂”(split)的方式来动态地进行分区。
我们的整个数据表,会按照行键排好序,然后按照连续的行键一段段地分区。如果某一段行键的区间里,写的数据越来越多,占用的存储空间越来越大,那么整个系统会自动地将这个分区一分为二,变成两个分区。而如果某一个区间段的数据被删掉了很多,占用的空间越来越小了,那么我们就会自动把这个分区和它旁边的分区合并到一起。
这个分区的过程,就好像你按照A~Z的字母顺序去管理你的书的过程。一开始,你只有一个空箱子放在地上,然后你把你的书按照书名的拼音,从上到下放在箱子里。当有一本新书需要放进来的时候,你就按照字母顺序插在某两本书中间。而当箱子放不下的时候,你就再拿一个空箱子,放在放不下的箱子下面,然后把之前的箱子里的图书从中间一分,把下面的一半放到新箱子里。
而我们删除数据的时候,就要把书从箱子里面拿走。当两个相邻的箱子里都很空的时候,我们就可以把两个箱子里面的书放到一个箱子里面,然后把腾出来的空箱子挪走。这里的一个个“箱子”就是我们的分片,这里面的一本本书,就是我们的一行数据,而书名的拼音,就是我们的行键。可能以A、B、C开头的书多一些,那么它们占用的分区就会多一些,以U、V、W开头的书少一些,可能这些书就都在一个分区里面。

采用这样的方式,你会发现,你可以动态地调整数据是如何分区的,并且每个分区在数据量上,都会相对比较均匀。而且,在分区发生变化的时候,你需要调整的只有一个分区,再没有需要大量搬运数据的压力了。
那么看到这儿,你可能要问了:要是上一讲的MySQL集群也用这样的分区方式,问题是不是就解决了?
答案当然是办不到了。因为我们还需要有一套存储、管理分区信息的机制,这在哈希分片的MySQL集群里是没有的。在Bigtable里,我们是通过Master和Chubby这两个组件来完成这个任务的。这两个组件,加上每个分片提供服务的Tablet Server,以及实际存储数据的GFS,共同组成了整个Bigtable集群。
Tablet Server的角色最明确,就是用来实际提供数据读写服务的。一个Tablet Server上会分配到10到1000个Tablets,Tablet Server就去负责这些Tablets的读写请求,并且在单个Tablet太大的时候,对它们进行分裂。
而哪些Tablets分配给哪个Tablet Server,自然是由Master负责的,而且Master可以根据每个Tablet Server的负载进行动态的调度,也就是Master还能起到负载均衡(load balance)的作用。而这一点,也是MySQL集群很难做到的。
这是因为,Bigtable的Tablet Server只负责在线服务,不负责数据存储。实际的存储,是通过一种叫做SSTable的数据格式写入到GFS上的。也就是Bigtable里,数据存储和在线服务的职责是完全分离的。我们调度Tablet的时候,只是调度在线服务的负载,并不需要把数据也一并搬运走。
而在上一讲里的MySQL集群,服务职责和数据存储是在同一个节点上的。我们要想把负载大的节点调度到其他地方去,就意味着数据也要一并迁移走,而复制和迁移数据又会进一步加大节点的负载,很有可能造成雪崩效应。

事实上,Master一共会负责5项工作:
那看到这里你可能要问了,好像Master加上Tablet Server就足以组成Bigtable了,为什么还有一个Chubby这个组件呢?别着急,你接着往下看。
Bigtable需要Chubby来搞定这么几件事儿:
这里面的最后两项只是简单的数据存储功能,我们就不多讲了,我们重点来看看前三项。
如果没有Chubby的话,我能想到最直接的集群管理方案,就是让所有的Tablet Server直接和Master通信,把分区信息以及Tablets分配到哪些Tablet Server,也直接放在Master的内存里面。这个办法,就和我们之前在GFS里的办法一样。但是这个方案,也就使得Master变成了一个单点故障点(SPOF-Single Point of Failure)。当然,我们可以通过Backup Master以及Shadow Master等方式,来尽可能提升可用性。
可是这样第一个问题就来了,我们在GFS的论文里面说过,我们可以通过一个外部服务去监控Master的存活,等它挂了之后,自动切换到Backup Master。但是,我们怎么知道Master是真的挂了,还是只是“外部服务”和Master之间的网络出现故障了呢?
如果是后者的话,我们很有可能会遇到一个很糟糕的情况,就是系统里面出现了两个Master。这个时候,可能两个客户端分别认为这两个Master是真的,当它们分头在两边写入数据的时候,我们就会遇到数据不一致的问题。
那么Chubby,就是这里的这个外部服务,不过Chubby不是1台服务器,而是5台服务器组成的一个集群,它会通过Paxos这样的共识算法,来确保不会出现误判。而且因为它有5台服务器,所以也一并解决了高可用的问题,就算挂个1~2台,也并不会丢数据。关于具体Chubby的原理和使用,我们会在后面讲解Chubby论文的时候专门介绍,今天就先不展开了。
Chubby帮我们保障了只有一个Master,那么我们再来看看分区和Tablets的分配信息,这些信息也没有放在Master。Bigtable在这里用了一个很巧妙的方法,就是直接把这个信息,存成了Bigtable的一张METADATA表,而这张表在哪里呢,它是直接存放在Bigtable集群里面的,其实METADATA表自己就是一张Bigtable的数据表。
这其实有点像MySQL里面的information_schema表,也就是数据库定义了一张特殊的表,用来存放自己的元数据。不过,Bigtable是一个分布式数据库,所以我们还要知道,这个元数据究竟存放在哪个Tablet Server里,这个就需要通过Chubby来告诉我们了。
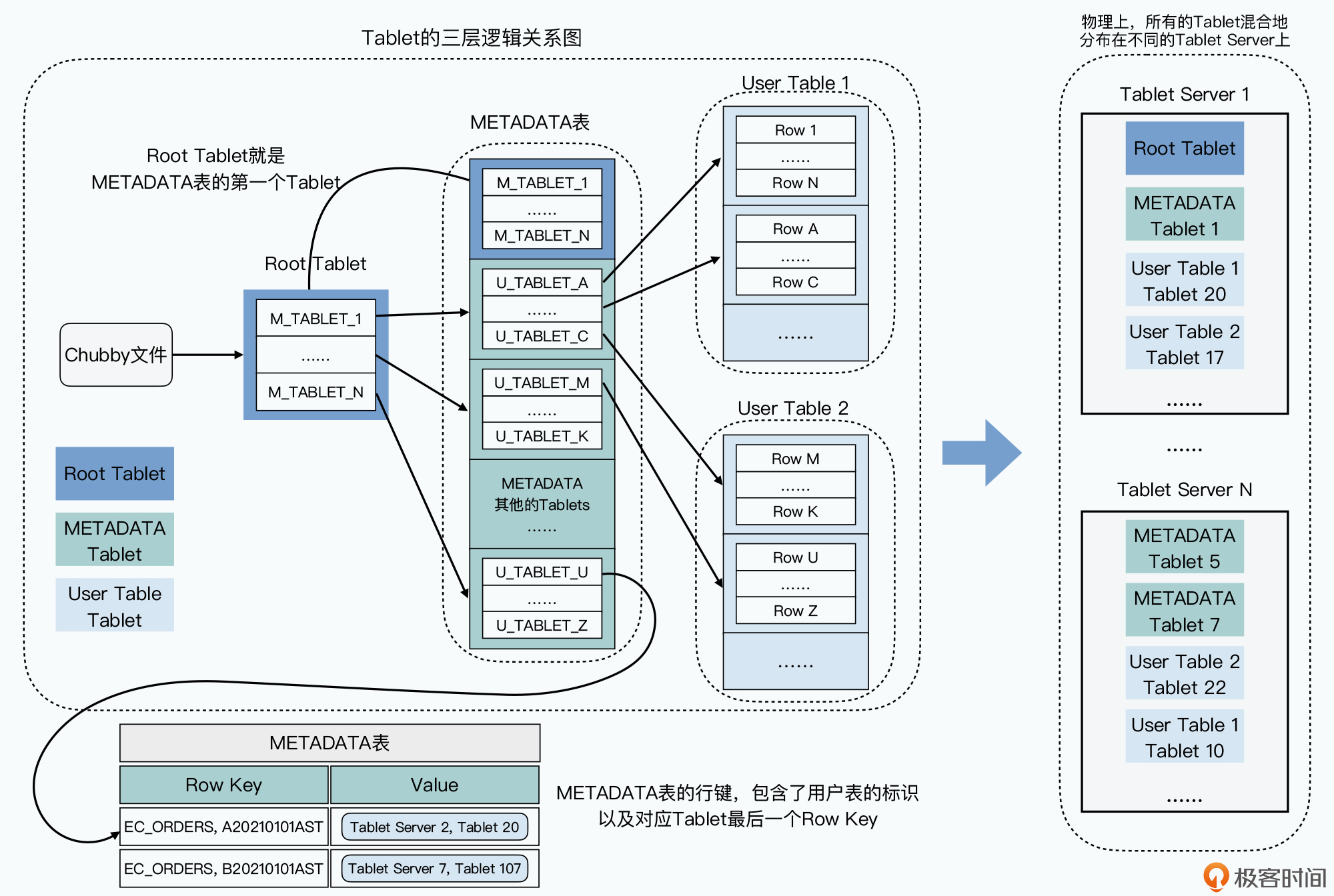
这里我们来看一个具体的Bigtable数据读写的例子,来帮助你理解这样一个三层结构。比如,客户端想要根据订单号,查找我们的订单信息,订单都存在Bigtable的ECOMMERCE_ORDERS表里,这张要查的订单号,就是A20210101RST。
那么,我们的客户端具体是怎么查询的呢?

可以看到,在这个过程里,我们用了三次网络查询,找到了想要查询的数据的具体位置,然后再发起一次请求拿到最终的实际数据。一般我们会把前三次查询位置结果缓存起来,以减少往返的网络查询次数。而对于整个METADATA表来说,我们都会把它们保留在内存里,这样每个Bigtable请求都要读写的数据,就不需要通过访问GFS来读取到了。
这个Tablet分区信息,其实是一个三层Tablet信息存储的架构,而三层结构让Bigtable可以“伸缩”到足够大。METADATA的一条记录,大约是1KB,而METADATA的Tablet如果限制在128MB,三层记录可以存下大约 (128*1000)**2=2**34个Tablet的位置,也就是大约160亿个Tablet,肯定是够用了。
这个设计带来了一个很大的好处,就是查询Tablets在哪里这件事情,尽可能地被分摊到了Bigtable的整个集群,而不是集中在某一个Master节点上。而唯一所有人都需要查询的Root Tablet的位置和里面的数据,考虑到Root Tablet不会分裂,并且客户端可以有缓存,Chubby和Root Tablet所在的Tablet服务器也不会有太大压力。
另外你还会发现,在整个数据读写的过程中,客户端是不需要经过Master的。即使Master节点已经挂掉了,也不会影响数据的正常读写。客户端不需要认识Master这个“主人”,也不依赖Master这个“主人”为我们提供服务。这个设计,让Bigtable更加“高可用”了。
而如果我们回顾前面整个查询过程,其实就很容易理解,为什么Chubby里面存的叫做Bigtable的引导位置,因为这个过程和操作系统启动的过程很类似,都是要从一个固定的位置读取信息,来获得后面的动态的信息。在操作系统里,这个是读取硬盘的第一个扇区,而在Bigtable里,则是Chubby里存放Root Tablet位置的固定文件。
的确,在单纯的数据读写的过程中不需要Master。Master只负责Tablets的调度而已,而且这个调度功能,也对Chubby有所依赖。我们来看一看这个过程是怎么样的:
好了,到了这里,相信你对整个Bigtable的系统架构就有一个清晰的了解了,现在我们就一起来回顾一下。
整个Bigtable是由4个组件组成的,分别是:

而通过动态区域分区的方式,Bigtable的分区策略需要的数据搬运工作量会很小。在Bigtable里,Master并不负责保存分区信息,也不负责为分区信息提供查询服务。
Bigtable是通过把分区信息直接做成了三层树状结构的Bigtable表,来让查询分区位置的请求分散到了整个Bigtable集群里,并且通过把查询的引导位置放在Chubby中,解决了和操作系统类似的“如何启动”问题。而整个系统的分区分配工作,由Master完成。通过对于Chubby锁的使用,就解决了Master、Tablet Server进出整个集群的问题。
到这里,Bigtable的基础架构就介绍完了。不过我们还有两个非常重要的知识点需要深入探讨,一个是单个Tablet的底层存储和读写,具体是如何实现来做到高性能的,另一个是今天出现的神奇的Chubby到底是什么。接下来的两节课,我们就会一起来寻找答案。
对于数据分区可以有哪些方法,《数据密集型应用系统设计》的第6章做了非常详尽的讲解,你可以去好好读一下。另外,对于Bigtable本身的论文,我也建议你多花时间去弄清楚,因为后续的Megastore、Spanner等等的论文,都只是Bigtable的升级改进而已,底层的基本原理是不变的。
Bigtable论文里的第7部分“性能评估”里,你可以看到Bigtable在随机读数据上的性能表现并不好,无法真正做到随着节点数的增加线性增长。这是为什么呢?这个和我们今天讲的Bigtable的设计中的哪一个设计点相关?